1、为什么要使用intern()方法
intern方法设计的初衷是为了重用string对象,节省内存
用代码实例验证下
public class StringInternTest { static final int MAX = 100000; static final String[] arr = new String[MAX]; public static void main(String[] args) throws Exception { //为长度为10的Integer数组随机赋值 Integer[] sample = new Integer[10]; Random random = new Random(1000); for (int i = 0; i < sample.length; i++) { sample[i] = random.nextInt(); } //记录程序开始时间 long t = System.currentTimeMillis(); //使用/不使用intern方法为10万个String赋值,值来自于Integer数组的10个数 for (int i = 0; i < MAX; i++) { //arr[i] = new String(String.valueOf(sample[i % sample.length])); arr[i] = new String(String.valueOf(sample[i % sample.length])).intern(); } System.out.println((System.currentTimeMillis() - t) + "ms"); System.gc(); } }
这个例子,为了证明使用intern比不使用消耗的内存更少。
先定一个长度为10的Integer数组,并随机为其赋值,在通过for循环为长度为10w的String对象依次赋值,这些值都来自于Integer数组,两种情况分别运行,可通过Window ---> Preferences --> Java --> Installed JREs设置JVM启动参数为-agentlib:hprof=heap=dump,format=b,将程序运行后的hprof置于工程目录下。再通过MAT插件查看该hprof文件。
两次实验结果:

从运行结果来看,不使用intern的情况下,程序生成了101943个String对象,而使用intern,仅仅生成了1953个String对象,自然证明了intern节省内存的结论。
细心的同学发现了使用intern时执行时间是增加了,这是因为每次都是用了 new String后又进行intern()操作的耗时时间,但是不使用intern占用内存导致gc的时间远远大于这点时间。
2、深入认识intern方法
jdk1.7之后,常量池被放入到堆空间中,这导致intern函数的功能不同,具体怎么个不同法,且看看下面的代码,这个例子是网上流传较广的一个例子,分析图也是直接黏贴过来的。
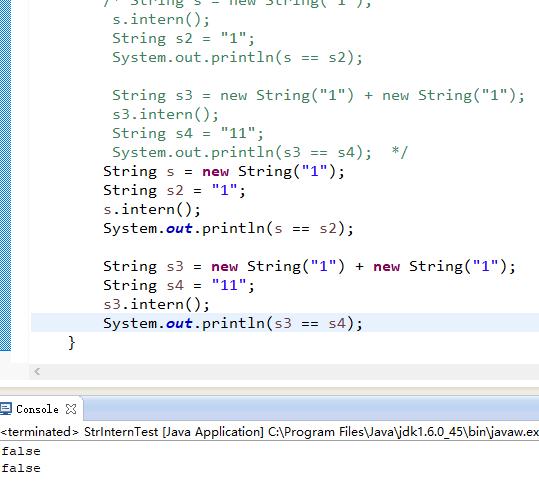
String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4);
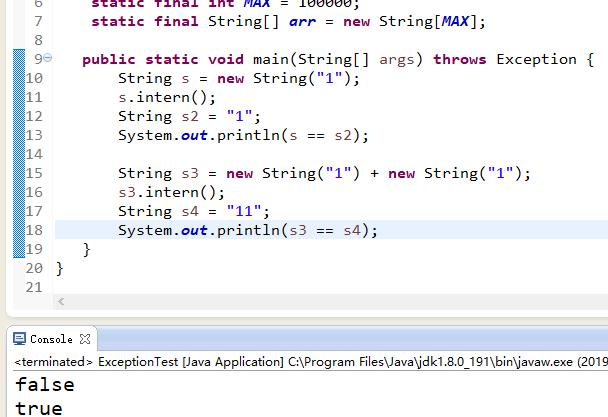
代码做调整之后的执行结果:
2.1 具体分析
JDK1.6的intern底层实现
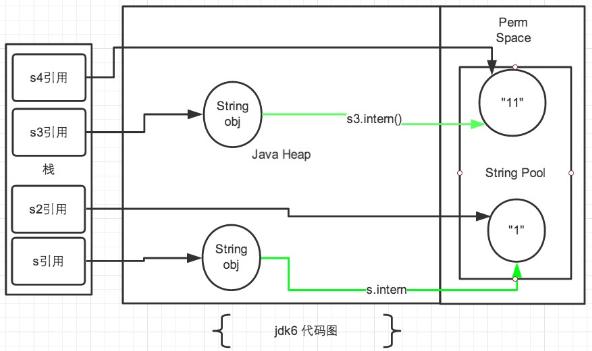
JDK1.6以及之后的版本,常量池是放在Perm区(方法区)的,熟悉JVM的话这个是和堆是完全分开的。
使用引号声明的字符串都是会直接在字符串常量池中生成的,而new出来的String对象是放在堆空间中的,所以两者的内存地址肯定是不相同的,即使调用了intern方法也是不影响的。
intern方法在jdk1.6中的作用是:比如String s = new String("aaa"),再调用s.intern,此时返回值还是字符串“aaa”,表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查常量池里是否存在“aaa”这么一个字符串,如果存在,就返回池里的字符串,如果不存在,该方法会把“aaa”添加到字符串池中,然后再返回它的引用。
JDK1.7
针对JDK1.7以及以上的版本,我们将上面两段代码分开讨论。
public static void main(String[] args) { String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4); }
String s = newString("1"),生成了常量池中的“1” 和堆空间中的字符串对象。
s.intern(),这一行的作用是s对象去常量池中寻找后发现"1"已经存在于常量池中了。
String s2 = "1",这行代码是生成一个s2的引用指向常量池中的“1”对象。
结果就是 s 和 s2 的引用地址明显不同。因此返回了false。
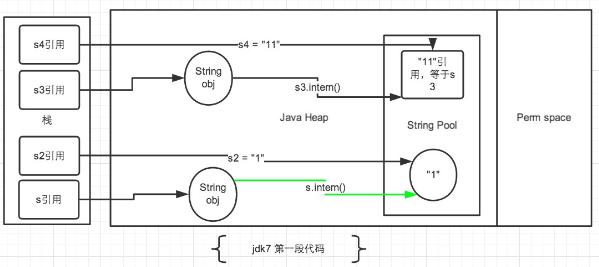
String s3 = new String("1") + new String("1"),这行代码在字符串常量池中生成“1”。并在堆空间中生成s3引用指向的对象(内容为“11”),注意此时常量池中是没有“11”对象的。
s3.intern(),这一行代码,是将s3中的“11”字符串放入String常量池中,此时常量池中不存在“11”字符串,JDK1.6的做法是直接在常量池中生成一个“11”的对象,并返回该对象的引用。
但是在JDK1.7中,常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用直接指向s3引用的对象,也就是说s3.intern()==s3会返回true。
String s4 = “11”,这一行代码会直接去常量池中创建,但是发现已经有这个对象了,此时也就是指向s3引用对象的一个引用。因此s3 == s4返回了true。
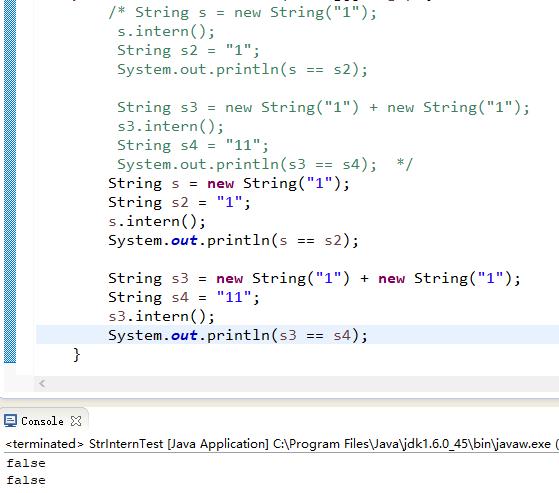
public static void main(String[] args) { String s = new String("1"); String s2 = "1"; s.intern(); System.out.println(s == s2); String s3 = new String("1") + new String("1"); String s4 = "11"; s3.intern(); System.out.println(s3 == s4); }
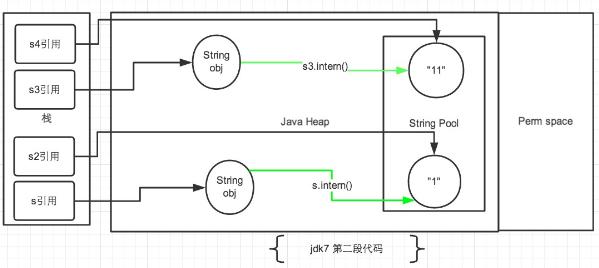
String s = new String("1"),生成了常量池中的“1”和堆空间中的字符串对象。
String s2 = "1",这行代码是生成一个s2的引用指向常量池中的"1"对象,但是发现已经存在了,那么就直接指向了它。
s.intern(),这一行在这里就没什么实际作用了,因为"1"已经存在了。
结果就是s和s2的引用地址明显不同。因此返回了false。
String s3 = new String("1") + new String("1"),这行代码在字符串常量池中生成"1",并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中没有"11"对象的。
String s4 = "11",这一行代码会直接去生成常量池中的"11"。
s3.intern(),这一行在这里就没什么实际作用了,因为"11"已经存在了。
结果就是s3和s4的引用地址明显不同。因此返回了false。