文章目录
一、项目背景
二、数据处理
1、标签与特征分离
2、数据可视化
3、训练集和测试集
三、模型搭建
四、模型训练
五、完整代码
一、项目背景
数据集cnn_train.csv包含人类面部表情的图片的label和feature。在这里,面部表情识别相当于一个分类问题,共有7个类别。
其中label包括7种类型表情:

一共有28709个label,说明包含了28709张表情包嘿嘿。
每一行就是一张表情包48*48=2304个像素,相当于4848个灰度值(intensity)(0为黑, 255为白)

二、数据处理
1、标签与特征分离
这一步为了后面方便读取数据集,对原数据进行处理,分离后分别保存为cnn_label.csv和cnn_data.csv.
# cnn_feature_label.py 将label和像素数据分离 import pandas as pd path = 'cnn_train.csv'# 原数据路径 # 读取数据 df = pd.read_csv(path) # 提取label数据 df_y = df[['label']] # 提取feature(即像素)数据 df_x = df[['feature']] # 将label写入label.csv df_y.to_csv('cnn_label.csv', index=False, header=False) # 将feature数据写入data.csv df_x.to_csv('cnn_data.csv', index=False, header=False)
执行之后生成结果文件:
2、数据可视化
完成与标签分离后,下一步我们对特征进一步处理,也就是将每个数据行的2304个像素值合成每张48*48的表情图。
# face_view.py 数据可视化 import cv2 import numpy as np # 指定存放图片的路径 path = './/face' # 读取像素数据 data = np.loadtxt('cnn_data.csv') # 按行取数据 for i in range(data.shape[0]): face_array = data[i, :].reshape((48, 48)) # reshape cv2.imwrite(path + '//' + '{}.jpg'.format(i), face_array) # 写图片
这段代码将写入28709张表情图,执行需要一小段时间。
结果如下:

3、训练集和测试集
第一步,我们要训练模型,需要划分一下训练集和验证集。一共有28709张图片,我取前24000张图片作为训练集,其他图片作为验证集。新建文件夹cnn_train和cnn_val,将0.jpg到23999.jpg放进文件夹cnn_train,将其他图片放进文件夹cnn_val。
第二步,对每张图片标记属于哪一个类别,存放在dataset.csv中,分别在刚刚训练集和测试集执行标记任务。
# cnn_picture_label.py 表情图片和类别标注 import os import pandas as pd def data_label(path): # 读取label文件 df_label = pd.read_csv('cnn_label.csv', header=None) # 查看该文件夹下所有文件 files_dir = os.listdir(path) # 用于存放图片名 path_list = [] # 用于存放图片对应的label label_list = [] # 遍历该文件夹下的所有文件 for file_dir in files_dir: # 如果某文件是图片,则将其文件名以及对应的label取出,分别放入path_list和label_list这两个列表中 if os.path.splitext(file_dir)[1] == ".jpg": path_list.append(file_dir) index = int(os.path.splitext(file_dir)[0]) label_list.append(df_label.iat[index, 0]) # 将两个列表写进dataset.csv文件 path_s = pd.Series(path_list) label_s = pd.Series(label_list) df = pd.DataFrame() df['path'] = path_s df['label'] = label_s df.to_csv(path + '\dataset.csv', index=False, header=False) def main(): # 指定文件夹路径 train_path = 'D:\PyCharm_Project\deep learning\model\cnn_train' val_path = 'D:\PyCharm_Project\deep learning\model\cnn_val' data_label(train_path) data_label(val_path) if __name__ == "__main__": main()
完成之后如图:
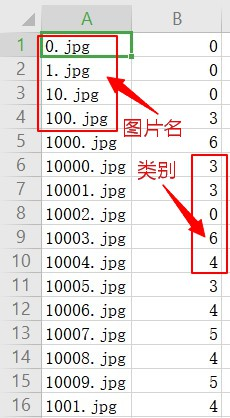
第三步,重写Dataset类,它是Pytorch中图像数据集加载的一个基类,源码如下,我们需要重写类来实现加载上面的图像数据集。
import bisect import warnings from torch._utils import _accumulate from torch import randperm class Dataset(object): r"""An abstract class representing a :class:`Dataset`. All datasets that represent a map from keys to data samples should subclass it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a data sample for a given key. Subclasses could also optionally overwrite :meth:`__len__`, which is expected to return the size of the dataset by many :class:`~torch.utils.data.Sampler` implementations and the default options of :class:`~torch.utils.data.DataLoader`. .. note:: :class:`~torch.utils.data.DataLoader` by default constructs a index sampler that yields integral indices. To make it work with a map-style dataset with non-integral indices/keys, a custom sampler must be provided. """ def __getitem__(self, index): raise NotImplementedError def __add__(self, other): return ConcatDataset([self, other]) # No `def __len__(self)` default? # See NOTE [ Lack of Default `__len__` in Python Abstract Base Classes ] # in pytorch/torch/utils/data/sampler.py
重写之后如下,自定义类名为FaceDataset:
class FaceDataset(data.Dataset): # 初始化 def __init__(self, root): super(FaceDataset, self).__init__() self.root = root df_path = pd.read_csv(root + '\dataset.csv', header=None, usecols=[0]) df_label = pd.read_csv(root + '\dataset.csv', header=None, usecols=[1]) self.path = np.array(df_path)[:, 0] self.label = np.array(df_label)[:, 0] # 读取某幅图片,item为索引号 def __getitem__(self, item): # 图像数据用于训练,需为tensor类型,label用numpy或list均可 face = cv2.imread(self.root + '\' + self.path[item]) # 读取单通道灰度图 face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY) # 直方图均衡化 face_hist = cv2.equalizeHist(face_gray) """ 像素值标准化 读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d() API所接受的数据格式是(batch_size, channel, width, higth), 本次图片通道为1,因此我们要将48X48 reshape为1X48X48。 """ face_normalized = face_hist.reshape(1, 48, 48) / 255.0 face_tensor = torch.from_numpy(face_normalized) face_tensor = face_tensor.type('torch.FloatTensor') label = self.label[item] return face_tensor, label # 获取数据集样本个数 def __len__(self): return self.path.shape[0]
到此,就实现了数据集加载的过程,下面准备使用这个类将数据喂给模型训练了。
这是Github上面部表情识别的一个开源项目的模型结构,我们使用model B搭建网络模型。使用RRelu(随机修正线性单元)作为激活函数。卷积神经网络模型如下:
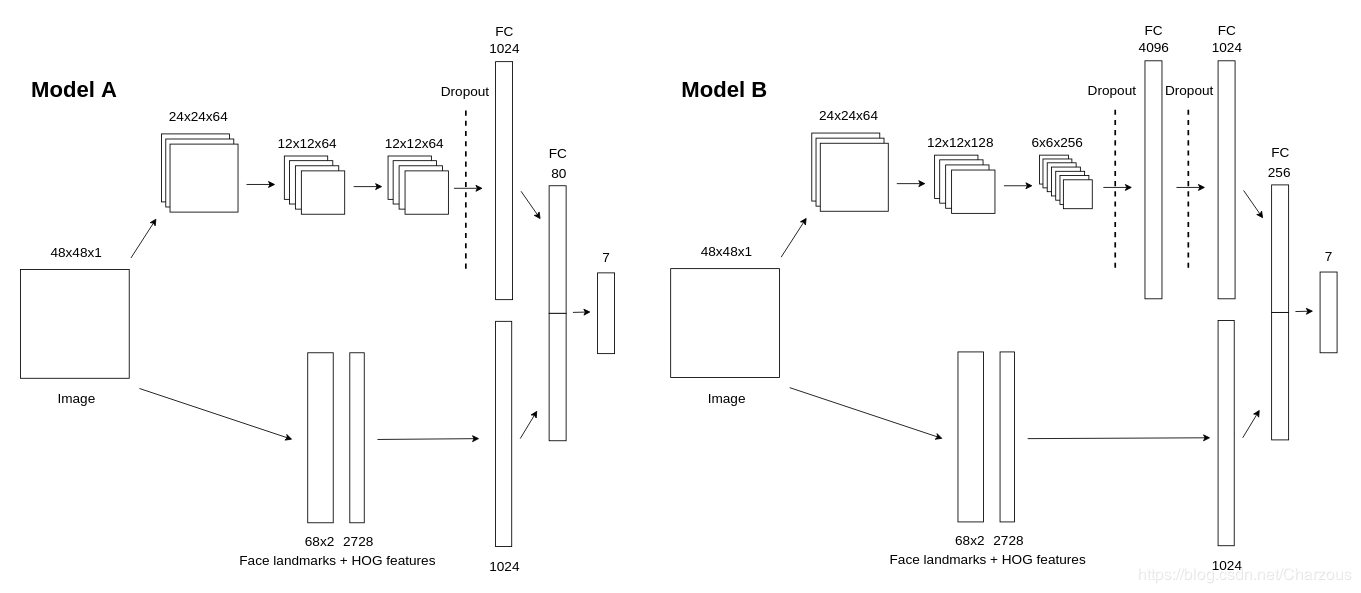
class FaceCNN(nn.Module): # 初始化网络结构 def __init__(self): super(FaceCNN, self).__init__() # 第一层卷积、池化 self.conv1 = nn.Sequential( nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层 nn.BatchNorm2d(num_features=64), # 归一化 nn.RReLU(inplace=True), # 激活函数 nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化 ) # 第二层卷积、池化 self.conv2 = nn.Sequential( nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(num_features=128), nn.RReLU(inplace=True), # output:(bitch_size, 128, 12 ,12) nn.MaxPool2d(kernel_size=2, stride=2), ) # 第三层卷积、池化 self.conv3 = nn.Sequential( nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), nn.BatchNorm2d(num_features=256), nn.RReLU(inplace=True), # output:(bitch_size, 256, 6 ,6) nn.MaxPool2d(kernel_size=2, stride=2), ) # 参数初始化 self.conv1.apply(gaussian_weights_init) self.conv2.apply(gaussian_weights_init) self.conv3.apply(gaussian_weights_init) # 全连接层 self.fc = nn.Sequential( nn.Dropout(p=0.2), nn.Linear(in_features=256 * 6 * 6, out_features=4096), nn.RReLU(inplace=True), nn.Dropout(p=0.5), nn.Linear(in_features=4096, out_features=1024), nn.RReLU(inplace=True), nn.Linear(in_features=1024, out_features=256), nn.RReLU(inplace=True), nn.Linear(in_features=256, out_features=7), ) # 前向传播 def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.conv3(x) # 数据扁平化 x = x.view(x.shape[0], -1) y = self.fc(x) return y
参数解析:
输入通道数in_channels,输出通道数(即卷积核的通道数)out_channels,卷积核大小kernel_size,步长stride,对称填0行列数padding。
第一层卷积:input:(bitch_size, 1, 48, 48), output(bitch_size, 64, 24, 24)
第二层卷积:input:(bitch_size, 64, 24, 24), output(bitch_size, 128, 12, 12)
第三层卷积:input:(bitch_size, 128, 12, 12), output:(bitch_size, 256, 6, 6)
四、模型训练
损失函数使用交叉熵,优化器是随机梯度下降SGD,其中weight_decay为正则项系数,每轮训练打印损失值,每5轮训练打印准确率。
def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay): # 载入数据并分割batch train_loader = data.DataLoader(train_dataset, batch_size) # 构建模型 model = FaceCNN() # 损失函数 loss_function = nn.CrossEntropyLoss() # 优化器 optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay) # 逐轮训练 for epoch in range(epochs): # 记录损失值 loss_rate = 0 # scheduler.step() # 学习率衰减 model.train() # 模型训练 for images, labels in train_loader: # 梯度清零 optimizer.zero_grad() # 前向传播 output = model.forward(images) # 误差计算 loss_rate = loss_function(output, labels) # 误差的反向传播 loss_rate.backward() # 更新参数 optimizer.step() # 打印每轮的损失 print('After {} epochs , the loss_rate is : '.format(epoch + 1), loss_rate.item()) if epoch % 5 == 0: model.eval() # 模型评估 acc_train = validate(model, train_dataset, batch_size) acc_val = validate(model, val_dataset, batch_size) print('After {} epochs , the acc_train is : '.format(epoch + 1), acc_train) print('After {} epochs , the acc_val is : '.format(epoch + 1), acc_val) return model


1 """ 2 CNN_face.py 基于卷积神经网络的面部表情识别(Pytorch实现) 3 """ 4 import torch 5 import torch.utils.data as data 6 import torch.nn as nn 7 import torch.optim as optim 8 import numpy as np 9 import pandas as pd 10 import cv2 11 12 13 # 参数初始化 14 def gaussian_weights_init(m): 15 classname = m.__class__.__name__ 16 # 字符串查找find,找不到返回-1,不等-1即字符串中含有该字符 17 if classname.find('Conv') != -1: 18 m.weight.data.normal_(0.0, 0.04) 19 20 21 # 验证模型在验证集上的正确率 22 def validate(model, dataset, batch_size): 23 val_loader = data.DataLoader(dataset, batch_size) 24 result, num = 0.0, 0 25 for images, labels in val_loader: 26 pred = model.forward(images) 27 pred = np.argmax(pred.data.numpy(), axis=1) 28 labels = labels.data.numpy() 29 result += np.sum((pred == labels)) 30 num += len(images) 31 acc = result / num 32 return acc 33 34 35 class FaceDataset(data.Dataset): 36 # 初始化 37 def __init__(self, root): 38 super(FaceDataset, self).__init__() 39 self.root = root 40 df_path = pd.read_csv(root + '\dataset.csv', header=None, usecols=[0]) 41 df_label = pd.read_csv(root + '\dataset.csv', header=None, usecols=[1]) 42 self.path = np.array(df_path)[:, 0] 43 self.label = np.array(df_label)[:, 0] 44 45 # 读取某幅图片,item为索引号 46 def __getitem__(self, item): 47 # 图像数据用于训练,需为tensor类型,label用numpy或list均可 48 face = cv2.imread(self.root + '\' + self.path[item]) 49 # 读取单通道灰度图 50 face_gray = cv2.cvtColor(face, cv2.COLOR_BGR2GRAY) 51 # 直方图均衡化 52 face_hist = cv2.equalizeHist(face_gray) 53 """ 54 像素值标准化 55 读出的数据是48X48的,而后续卷积神经网络中nn.Conv2d() API所接受的数据格式是(batch_size, channel, width, higth), 56 本次图片通道为1,因此我们要将48X48 reshape为1X48X48。 57 """ 58 face_normalized = face_hist.reshape(1, 48, 48) / 255.0 59 face_tensor = torch.from_numpy(face_normalized) 60 face_tensor = face_tensor.type('torch.FloatTensor') 61 label = self.label[item] 62 return face_tensor, label 63 64 # 获取数据集样本个数 65 def __len__(self): 66 return self.path.shape[0] 67 68 69 class FaceCNN(nn.Module): 70 # 初始化网络结构 71 def __init__(self): 72 super(FaceCNN, self).__init__() 73 74 # 第一次卷积、池化 75 self.conv1 = nn.Sequential( 76 nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1), # 卷积层 77 nn.BatchNorm2d(num_features=64), # 归一化 78 nn.RReLU(inplace=True), # 激活函数 79 nn.MaxPool2d(kernel_size=2, stride=2), # 最大值池化 80 ) 81 82 # 第二次卷积、池化 83 self.conv2 = nn.Sequential( 84 nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), 85 nn.BatchNorm2d(num_features=128), 86 nn.RReLU(inplace=True), 87 nn.MaxPool2d(kernel_size=2, stride=2), 88 ) 89 90 # 第三次卷积、池化 91 self.conv3 = nn.Sequential( 92 nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), 93 nn.BatchNorm2d(num_features=256), 94 nn.RReLU(inplace=True), 95 nn.MaxPool2d(kernel_size=2, stride=2), 96 ) 97 98 # 参数初始化 99 self.conv1.apply(gaussian_weights_init) 100 self.conv2.apply(gaussian_weights_init) 101 self.conv3.apply(gaussian_weights_init) 102 103 # 全连接层 104 self.fc = nn.Sequential( 105 nn.Dropout(p=0.2), 106 nn.Linear(in_features=256 * 6 * 6, out_features=4096), 107 nn.RReLU(inplace=True), 108 nn.Dropout(p=0.5), 109 nn.Linear(in_features=4096, out_features=1024), 110 nn.RReLU(inplace=True), 111 nn.Linear(in_features=1024, out_features=256), 112 nn.RReLU(inplace=True), 113 nn.Linear(in_features=256, out_features=7), 114 ) 115 116 # 前向传播 117 def forward(self, x): 118 x = self.conv1(x) 119 x = self.conv2(x) 120 x = self.conv3(x) 121 # 数据扁平化 122 x = x.view(x.shape[0], -1) 123 y = self.fc(x) 124 return y 125 126 127 def train(train_dataset, val_dataset, batch_size, epochs, learning_rate, wt_decay): 128 # 载入数据并分割batch 129 train_loader = data.DataLoader(train_dataset, batch_size) 130 # 构建模型 131 model = FaceCNN() 132 # 损失函数 133 loss_function = nn.CrossEntropyLoss() 134 # 优化器 135 optimizer = optim.SGD(model.parameters(), lr=learning_rate, weight_decay=wt_decay) 136 # 学习率衰减 137 # scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.8) 138 # 逐轮训练 139 for epoch in range(epochs): 140 # 记录损失值 141 loss_rate = 0 142 # scheduler.step() # 学习率衰减 143 model.train() # 模型训练 144 for images, labels in train_loader: 145 # 梯度清零 146 optimizer.zero_grad() 147 # 前向传播 148 output = model.forward(images) 149 # 误差计算 150 loss_rate = loss_function(output, labels) 151 # 误差的反向传播 152 loss_rate.backward() 153 # 更新参数 154 optimizer.step() 155 156 # 打印每轮的损失 157 print('After {} epochs , the loss_rate is : '.format(epoch + 1), loss_rate.item()) 158 if epoch % 5 == 0: 159 model.eval() # 模型评估 160 acc_train = validate(model, train_dataset, batch_size) 161 acc_val = validate(model, val_dataset, batch_size) 162 print('After {} epochs , the acc_train is : '.format(epoch + 1), acc_train) 163 print('After {} epochs , the acc_val is : '.format(epoch + 1), acc_val) 164 165 return model 166 167 168 def main(): 169 # 数据集实例化(创建数据集) 170 train_dataset = FaceDataset(root='D:PyCharm_Projectdeep learningmodelcnn_train') 171 val_dataset = FaceDataset(root='D:PyCharm_Projectdeep learningmodelcnn_val') 172 # 超参数可自行指定 173 model = train(train_dataset, val_dataset, batch_size=128, epochs=100, learning_rate=0.1, wt_decay=0) 174 # 保存模型 175 torch.save(model, 'model_net.pkl') 176 177 178 if __name__ == '__main__': 179 main()
以上程序代码的执行过程需要较长时间,目前我只能在CPU上跑程序,速度慢,算力不足,我差不多用了1天时间训练100轮,训练时间看不同电脑设备配置,如果在GPU上跑会快很多。
下面截取几个训练结果:
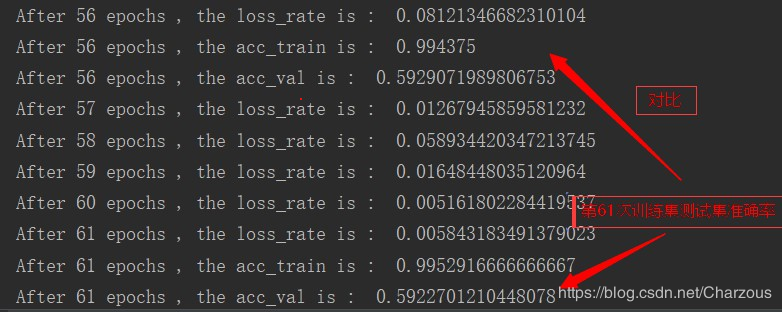
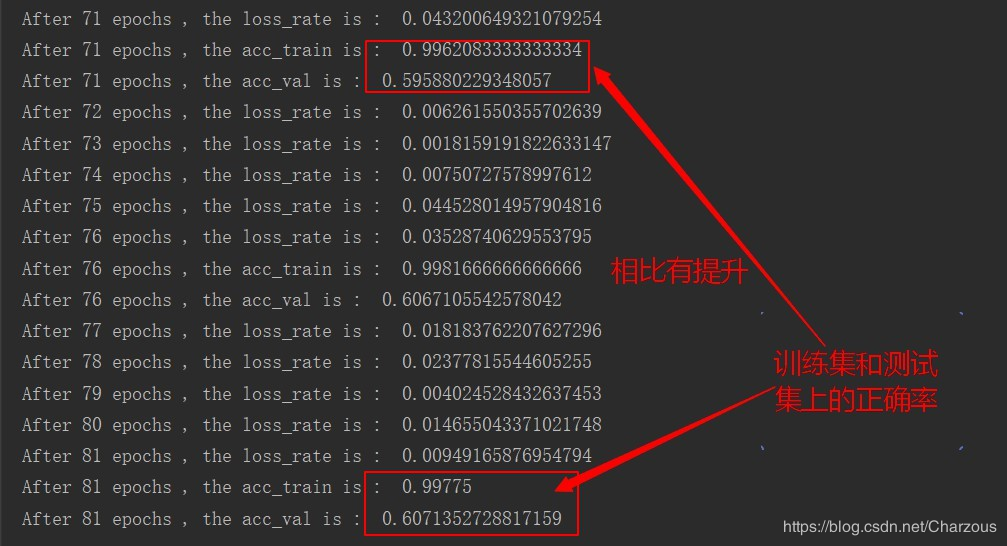
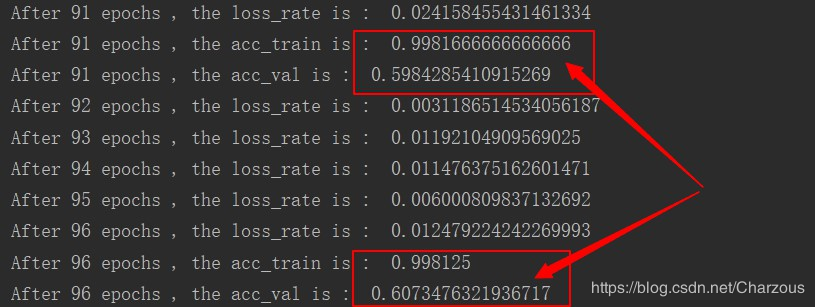
从结果可以看出,训练在60轮的时候,模型在训练集上的准确率达到99%以上,而在测试集上只有60%左右,很明显出现过拟合的情况,还可以进一步优化参数,使用正则等方法防止过拟合。另外,后面几十轮训练的提升很低,还需要找出原因。
这个过程我还在学习中,上面是目前达到的结果,希望之后能够把这个模型进一步优化,提高准确率。
小结:
学习了机器学习和深度学习有一段时间,基本上看的是李宏毅老师讲解的理论知识,还未真正去实现训练一个模型。这篇记录我第一次学习的项目过程,多有不足,还需不断实践。目前遇到的问题是:1、基本的理论知识能够理解,但是在公式推导和模型选择还未很好掌握。2、未具备训练一个模型的经验(代码实现),后续需要学习实战项目。
参考资料:
机器学习-李宏毅(2019)视频
https://ntumlta2019.github.io/ml-web-hw3/
https://www.cnblogs.com/HL-space/p/10888556.html
https://github.com/amineHorseman/facial-expression-recognition-using-cnn
我的博客园:https://www.cnblogs.com/chenzhenhong/p/13381296.html
我的CSDN博客:https://blog.csdn.net/Charzous/article/details/107596506
————————————————
这是我的CSDN博客链接,欢迎交流:
版权声明:本文为CSDN博主「Charzous」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Charzous/article/details/107452464