仅仅为了学习Keras的使用,使用一个四层的全连接网络对MNIST数据集进行分类,网络模型各层结点数为:3072: : 1024 : 512:10;
使用50000张图片进行训练,10000张测试:
precision recall f1-score support
airplane 0.61 0.69 0.65 1000
automobile 0.69 0.67 0.68 1000
bird 0.43 0.49 0.45 1000
cat 0.40 0.32 0.36 1000
dear 0.49 0.50 0.50 1000
dog 0.45 0.48 0.47 1000
frog 0.58 0.65 0.61 1000
horse 0.63 0.60 0.62 1000
ship 0.72 0.66 0.69 1000
truck 0.63 0.58 0.60 1000
micro avg 0.56 0.56 0.56 10000
macro avg 0.56 0.56 0.56 10000
weighted avg 0.56 0.56 0.56 10000
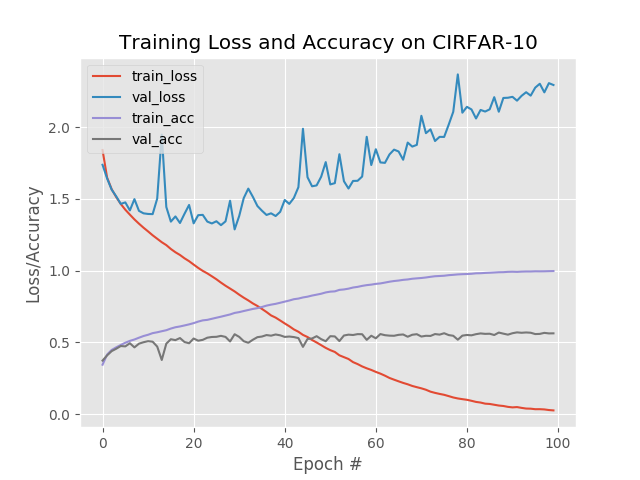
训练过程中,损失和正确率曲线:
可以看到,训练集的损失在一直降低,而测试集的损失出现大范围波动,并趋于上升,说明在一些epoch之后,出现过拟合;
训练集的正确率也在一直上升,并接近100%;而测试集的正确率达到50%就趋于平稳了;
代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 19-5-9
"""
implement classification for CIFAR-10 with Keras
"""
__author__ = 'Zhen Chen'
# import the necessary packages
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
# construct the argument parse and parse the arguments
parser = argparse.ArgumentParser()
parser.add_argument("-o", "--output", default="./Training Loss and Accuracy_CIFAR10.png")
args = parser.parse_args()
# load the training and testing data, scale it into the range [0, 1],
# then reshape the design matrix
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
trainX = trainX.reshape((trainX.shape[0], 3072))
testX = testX.reshape((testX.shape[0], 3072))
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.fit_transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "dear", "dog", "frog", "horse", "ship", "truck"]
# define the 2072-1024-512-10 architecture Keras
model = Sequential()
model.add(Dense(1024, input_shape=(3072,), activation="relu"))
model.add(Dense(512, activation="relu"))
model.add(Dense(10, activation="softmax"))
# train the model using SGD
print("[INFO] training network...")
sgd = SGD(0.01)
model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=["accuracy"])
H = model.fit(trainX, trainY, validation_data=(testX, testY), epochs=100, batch_size=32)
model.save_weights('SGD_100_32.h5')
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(testX, batch_size=32)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1), target_names=labelNames))
# plot the training losss and accuracy
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 100), H.history["acc"], label="train_acc")
plt.plot(np.arange(0, 100), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy on CIRFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args.output)