要参与C语言项目,于是作者只好重拾C语言(之前都是C++,还是C++方便)。
看到大家都推荐看看 C陷阱与缺陷(C traps and pitfalls),于是好奇的开始了这本书的读书之旅。
决定将书中重要的知识点和易错点记录下来方便自己复习和他人学习~~不多说了,下面开始。
第一章:词法陷阱
- 在C语言中,符号(程序文字)之间的空白(包括空格符、制表符、换行符)将被忽略。书中举了一例:
1 if (x > big) big = x; 2 可以写成: 3 if 4 ( 5 x 6 > 7 big 8 ) 9 big 10 = 11 x 12 ;
其实我们编码的时候已经涉及到了,比如C标准规范就要求多用空格符来对齐;过长的判断式也会分为两行书写等。
这些所谓的空白当然是被忽略了,不然编译器没法理解程序意图了。。。
2. 在词法分析中,作者指出:如果/是为判断下一个符号而读入的第一个字符,而/之后紧挨*,那么无视上下文,这两个字符都被当做一个符号/*,表示一段注释的开始。
由此可能会出现以下问题:
y = x/*p;
语句想用x除以p说指向的值,结果赋给y。但是/*被解释为注释,于是语句直接将x赋给y。
其实这样写(*p)就可以很好避免。y = x/(*p);
这种错误是有可能出现的,好在现在的IDE注释都会变色,应该容易察觉。
3. 字符和字符串:
学C语言都知道单引号表示字符,双引号表示字符串。
其实单引号引起的单字符实际上代表一个整数,该整数值对应于该字符在编译器采用的字符集的序列值。
一般采用ASCII字符集,即’a’与97(十进制)含义严格一致。
而双引号引起的字符串,代表的是一个指向无名数组起始字符的指针,该数组被双引号之间的字符串+一个额外的二进制值为0的字符’�’(C中常用来表示结束)初始化。
书中举例:
1 printf(“hello world ”); 2 与 3 char hello[] = { ‘h’, ’e’, ‘l’, ‘l’, ‘o’, ‘ ’, ‘w’, ‘o’, ‘r’, ‘l’, ‘d’, ‘ ’, 0 }; 4 printf(hello); 是等效的
上面代码跑了下确实是对的,但其实将hello[]写成如下形式更有可读性。
char hello[] = {‘h’, ’e’, ‘l’, ‘l’, ‘o’, ‘ ’, ‘w’, ‘o’, ‘r’, ‘l’, ‘d’, ‘ ’, '�'};
4. 书中还提到整型数(16/32位)的存储空间可容纳多个字符(8位),那么有的编译器允许一个字符串常量中包括
多个字符。如'yes'代替“yes”。
按照单字符的整数本质,作者做了个实验:
1 int t1='a'; 2 printf("%d ", t1); 3 int t11='aa'; 4 printf("%d ", t11);
输出结果:
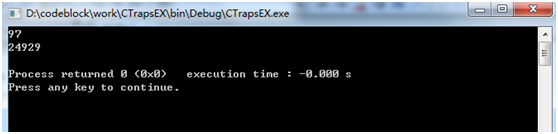
97就是'a'的asc码值好理解,但是'aa'的值24929可能就是和编译器与存储方式有关系,作者暂时也没懂,有大神可以评论讲解下~~
第一章也就这些注意点了,期待第二章!