1.中软国际华南区技术总监曾老师还会来上两次课,同学们希望曾老师讲些什么内容?(认真想一想回答)
可以多讲一些比较重要的知识点,能带我们实操或练习一下就更好了。
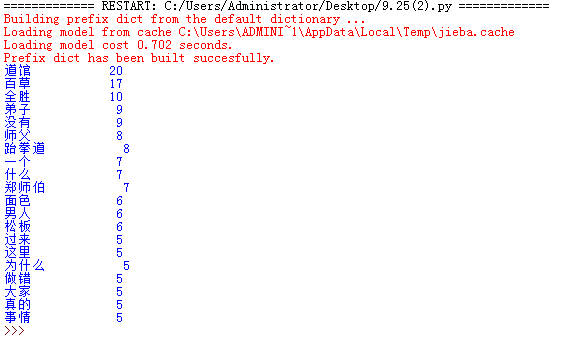
2.中文分词
- 下载一中文长篇小说,并转换成UTF-8编码。
- 使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
- **排除一些无意义词、合并同一词。
- **使用wordcloud库绘制一个词云。
(**两项选做,此次作业要求不能雷同。)
import jieba
xfsn=open("/Users/旋风少女.txt","r",encoding='utf-8').read()
words=jieba.lcut(xfsn)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))