什么是模块?
常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀。
但其实import加载的模块分为四个通用类别:
1 使用python编写的代码(.py文件)
2 已被编译为共享库或DLL的C或C++扩展
3 包好一组模块的包
4 使用C编写并链接到python解释器的内置模块
为何要使用模块?
# 分类 管理方法
# 节省内存
# 提供更多的功能
如果你退出python解释器然后重新进入,那么你之前定义的函数或者变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时就通过python test.py方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用,
模块的分类:
内置模块
安装python解释器的时候跟着装上的那些方法
第三方模块/扩展模块
没在安装python解释器的时候安装的那些功能
自定义模块
你写的功能如果是一个通用的功能,那你就把它当做一个模块
模块的创建和导入import
# import 要导入一个py文件的名字,但是不加.py的后缀名
import my_module 右键>>>run 结果:饿了吗 注:my_module.py文件中的内容 print("饿了吗")
# import这个语句相当于什么???
答: import这个模块相当于执行了这个模块所在的py文件
模块可以被多次导入么?
import my_module import my_module 右键>>>run 结果:饿了吗
答案是肯定的,一个模块是不会被重复导入
如何使用模块?
import my_module my_module.login() 右键>>>run 结果:登录函数 注:my_module.py文件中的内容: def login(): print("登录函数")
结论:# 模块的名字必须要满足变量的命名规范
# 一般情况下 模块都是小写字母开头的名字
# import my_module # def login(): # print("函数登录") # my_module.login() # # 结果:登录函数 # import my_module # def login(): # print("函数登录") # login() # 结果:函数登录 # 同理: # import my_module # name="babbb" # print(my_module.name) # 结果:aaaaa
那么,在导入一个模块的过程中到底发生了哪些事情?如图:

模块的重命名
import my_module as m m.login() <==> my_module.login()
导入多个模块import....
例如:import os , sys , my_module需要用逗号隔开
PEP8规范
所有的模块导入都应该尽量放在这个文件的开头
模块的导入也是有顺序的
先导入内置模块
再导入第三方模块
最后导入自定义模块
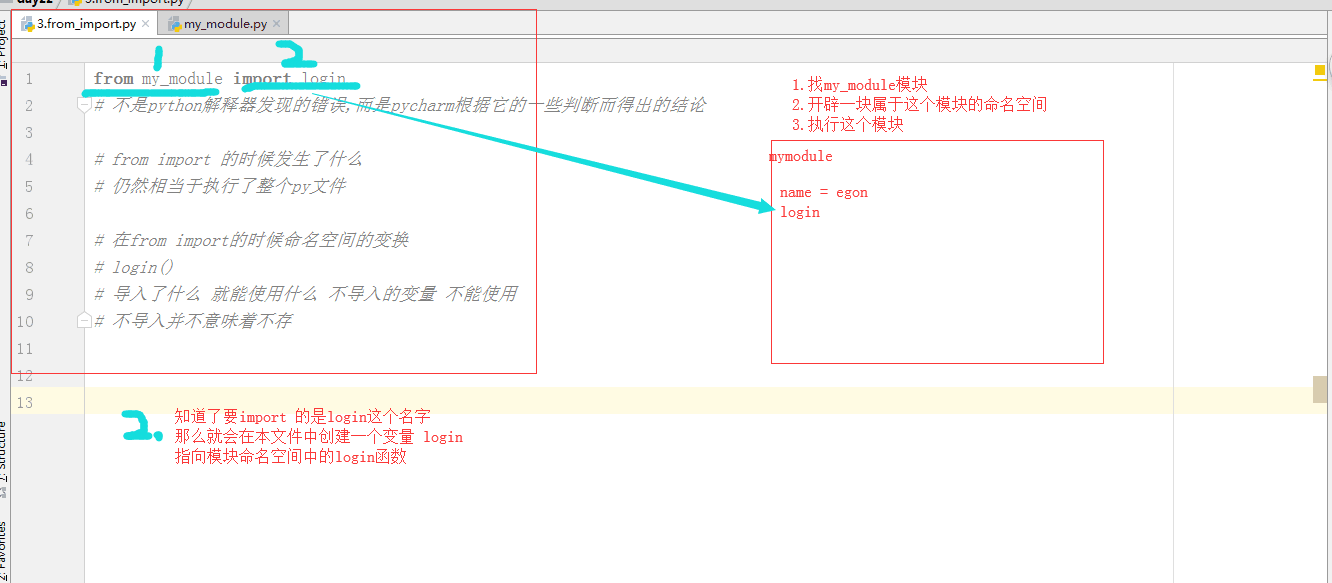
from ... import ...
# from my_module import login
#标红 不是python解释器发现的错误,而是pycharm根据它的一些判断而得出的结论
from my_module import login login() 右键>>>run 结果:登录函数 # # 注:my_module.py文件中的内容 # def login(): # print("登录函数")
# from import 的时候发生了什么
# 仍然相当于执行了整个py文件
# 导入了什么 就能使用什么 不导入的变量 不能使用
# 不导入并不意味着不存 而是没有建立文件到模块中其他名字的引用
from my_module import login def login(): print('in my login') login() 结果:in my login # 注:my_module.py文件中的内容 # def login(): # print("登录函数")

当模块中导入的方法或者变量 和 本文件重名的时候,那么这个名字只代表最后一次对它赋值的哪个方法或者变量
from my_module import login login() from my_module import name print(name) 结果: login bbbbbb bbbbbb 注:my_module.py文件中的内容 name = 'aaaaaa' def login(): print('login',name) name="bbbbbb"
from my_module import login name="cccccc" login() 结果:login bbbbbb 注:my_module.py文件中的内容 name = 'aaaaaa' def login(): print('login',name) name="bbbbbb"
from my_module import login name="cccccc" login() 结果:报错 注:my_module.py文件中的内容 def login(): print('login',name)
原因:只能正向导入关系,不能反向导入,被导入的模块永远不能运用导入它的模块中的内容
在本文件中对全局变量的修改是完全不会影响到模块中的变量引用的
重命名
from my_module import login as l l()
导入多个
from my_module import login,name逗号隔开 login() print(name)
from my_module import login,name login() print(name) name = 'cccccc' login() 结果: login bbbbbb bbbbbb login bbbbbb 注:my_module.py文件中的内容 name = 'aaaaaa' def login(): print('login',name) name="bbbbbb"
导入多个之后再重命名
from my_module import login as l,name as n
from 模块 import *
from my_module import * ## *<==>login,name login() name print(name)
注:所有的名字都可以引用
__all__可以控制*导入的内容
from my_module import * login() from my_module import name print(name) 结果: login bbbbbb bbbbbb 注:my_module.py文件中的内容 __all__=["login"] #[]内必须是字符串 name = 'aaaaaa' def login(): print('login',name) name="bbbbbb"
把模块当成脚本运行
# 运行一个py文件的两种方式
# 1.以模块的形式运行
# import my_module
# 2直接pycharm运行或cmd运行(右键==>run)
# 以脚本的形式运行,即在my_module.py文件中运行
print(__name__) 结果:__main__ 数据类型: print(type(__name__)) 结果:<class 'str'> import my_module 结果: my_module <class 'str'> 注:my_module.py文件中的内容 print(__name__) print(type(__name__))
结论:如果(以脚本形式)直接执行my_module.py文件中的__new__得到的是__main__
如果以模块形式运行得到的是my_module
导入import my_module(以模块形式执行)不应打印信息,就如import os等但是在本文件中需要执行
需要在本文件中直接打印的代码上加上
if __name__ == '__main__':
即: import my_module 右键>>>run 结果:没有打印信息 注:my_module.py文件中的内容 def login(): print("登录函数") if __name__ =="__main__": print("aaaaaa")
# 结论:
# 在编写py文件的时候
# 所有不在函数和类中封装的内容都应该写在
# if __name__ == '__main__':下面
import sys print(sys.modules["__main__"]) <module '__main__' from 'E:/chenwei/陈伟learning/week5/day5.py'> 以模块导入运行: import my_module 结果: # <module '__main__' from 'E:/chenwei/陈伟learning/week5/day5.py'> 注:my_module.py文件中的内容 import sys print(sys.modules["__main__"]) import sys print(sys.modules[__name__]) 结果:<module '__main__' from 'E:/chenwei/陈伟learning/week5/day5.py'> 以模块导入运行: import my_module 结果:<module 'my_module' from 'E:\chenwei\陈伟learning\week5\my_module.py'> 注:my_module.py文件中的内容 import sys print(sys.modules[__name__])
sys.modules存储了所有导入的文件的名字和这个文件的内存地址
{'__main__':当前直接执行文件所在的地址}
使用反射自己模块中的内容的时候 name="aaaaa" def login(): print('login',name) import sys my_module = sys.modules["__main__"] getattr(my_module,'login')() # 结果:login aaaaa 以模块导入运行: import my_module 结果:module '__main__' has no attribute 'login' 注:my_module.py文件中的内容 name="aaaaa" def login(): print('login',name) import sys my_module = sys.modules["__main__"] getattr(my_module,'login')() 所以:只需将main改成name就可以 import my_module 结果:login aaaaa 注:my_module.py文件中的内容 name="aaaaa" def login(): print('login',name) import sys my_module = sys.modules[__name__] getattr(my_module,'login')()
结论:字符串main会随着执行过程会改变,而name不会,无论是当成本脚本执行还是当成模块执行,都会随着程序变化而适应变化
模块搜索路径
python解释器在启动时会自动加载一些模块,可以使用sys.modules查看
在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用
如果没有,解释器则会查找同名的内建模块,如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。
所以总结模块的查找顺序是:内存中已经加载的模块->内置模块->sys.path路径中包含的模块
# 模块没导入之前在哪儿?
# 在硬盘上
# 安装python
# python整个包的结构不变
# 它会记录一个安装目录
# 其他所有目录都是根据安装目录来写死的
# 剩余所有都是python内置的目录
# 内置模块的导入
# 第三方模块的导入
# 内置模块的导入和第三方模块的导入都不需要你操心了
# 自定义的模块能否被导入
# 总结
# 模块的搜索路径全部存储在sys.path列表中
# 导入模块的顺序,是从前到后找到一个符合条件的模块就立即停止不再向后寻找
# 如果要导入的模块和当前执行的文件同级
# 直接导入即可
# 如果要导入的模块和当前执行的文件不同级
# 需要把要导入模块的绝对路径添加到sys.path列表中
pyc编译文件和重新加载模块
为了提高加载模块的速度,强调强调强调:提高的是加载速度而绝非运行速度。python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,my_module.py模块会被缓存成__pycache__/my_module.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
Python检查源文件的修改时间与编译的版本进行对比,如果过期就需要重新编译。这是完全自动的过程。并且编译的模块是平台独立的,所以相同的库可以在不同的架构的系统之间共享,即pyc使一种跨平台的字节码,类似于JAVA火.NET,是由python虚拟机来执行的,但是pyc的内容跟python的版本相关,不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
import aaa 模块导入的时候 python的执行 解释 - 编译
当一个文件作为一个脚本被导入的时候 就会在这个文件所在的目录的__pycache__下生成一个编译好的文件 为了之后导入这个文件的时候直接读这个编译好的pyc文件就可以
可以节省一些导入时候的时间
重新加载模块
import aaa import time aaa.login() time.sleep(10) aaa.login() 结果: 456 456 注意:第二456在10秒后打印 注:aaa.py文件中的内容: def login(): print(456) import aaa import time import importlib aaa.login() time.sleep(10) importlib.reload(aaa) # 表示重新加载 aaa.login() 结果: 456 123 注意:123在10秒后打印 注:起初aaa.py文件中的内容: def login(): print(456) 更改后 def login(): print(123)
# 结论:
# 如果程序已经执行,将456改成123,输出的结果不会改变
# 因为在import之后 再修改这个被导入的模块程序感知不到
# reload这种方式可以强制程序再重新导入这个模块一次
模块的循环引用
在模块的导入中 不要产生循环引用问题如果发生循环导入了就会发现明明写在这个模块中的方法,确偏显示找不到
包
什么是包?
集合了一组py文件 提供了一组复杂功能的
为什么要有包?
当提供的功能比较复杂,一个py文件写不下的时候
包中都有什么?
至少拥有一个__init__.py
直接导入模块
# import 包.包.模块
# 包.包.模块.变量
# from 包.包 import 模块 # 推荐 平时写作业的过程
# 模块.变量
导入包 读框架源码的时候
# 如要希望导入包之后 模块能够正常的使用 那么需要自己去完成init文件的开发
# 包中模块的 绝对导入 弊端:路劲更改后无法执行,需要重新改路劲,所以:执行路劲与包的位置是不允许变得
# 包中模块的 相对导入
# 使用了相对导入的模块只能被当做模块执行
# 不能被当做脚本执行
绝对导入:
import glace.api.policy glace.api.policy.get() 结果:from policy.py 注:policy.py文件中的内容: def get(): print('from policy.py') import glace.api.policy as policy policy.get() 结果:from policy.py 注:policy.py文件中的内容: def get(): print('from policy.py') from glace.api import policy policy.get() 结果:from policy.py 注:policy.py文件中的内容: def get(): print('from policy.py') import glace glace.gip 结果:报错 导入包 相当于执行了这个包下面的__init__.py import glace 结果:in glace 注:glace__init__.py文件中的内容: print("in glace") 因此可以设计一下init文件来完成一些模块的导入 import glace glace.api 结果: in glace in api 注:glace__init__.py文件中的内容: print("in glace") from glace import api api__init__.py文件中的内容: print("in api") import glace glace.api.policy.get() 结果: in glace in api from policy.py 注:glace__init__.py文件中的内容: print("in glace") from glace import api api__init__.py文件中的内容: print("in api") from glace.api import policy policy.py文件中的内容: def get(): print('from policy.py')
相对导入:
import glace2 结果: in glace in api 注:glace2__init__.py文件中的内容: print("in glace") from.import api api__init__.py文件中的内容: print("in api") from.import policy import glace2 glace2.api 结果: in glace in api 注:glace2__init__.py文件中的内容: print("in glace") from.import api api__init__.py文件中的内容: print("in api") from.import policy import glace2 glace2.api.policy.get() 结果: in glace in api from policy.py 注:glace2__init__.py文件中的内容: print("in glace") from.import api api__init__.py文件中的内容: print("in api") from.import policy 注:policy.py文件中的内容: def get(): print('from policy.py')
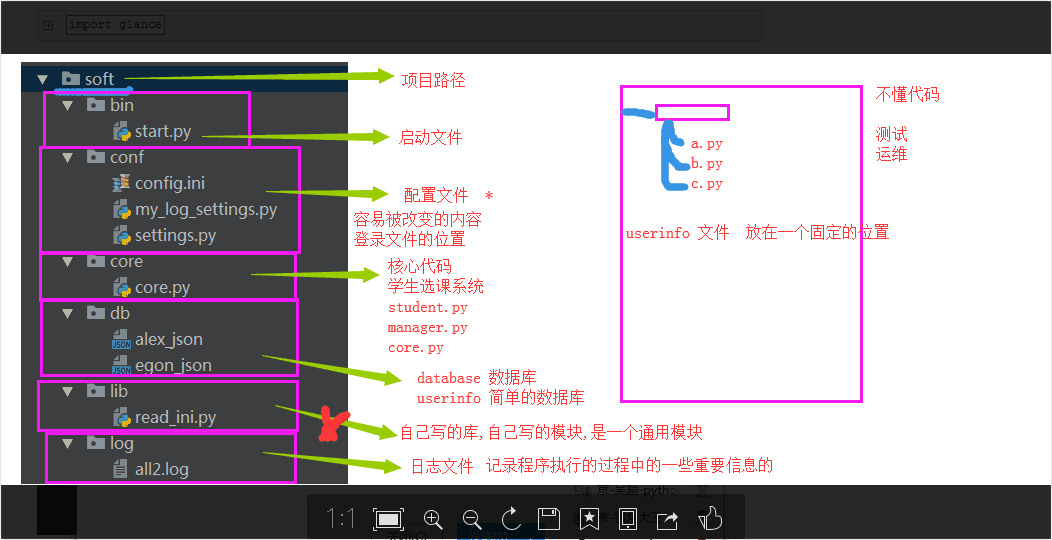
软件开发规范