本人是张杰的小迷妹,所以用杰哥的微博为例,之前一直看的是网页版,然后在知乎上看了一个抓取沈梦辰的微博评论的帖子,然后得到了这样的网址
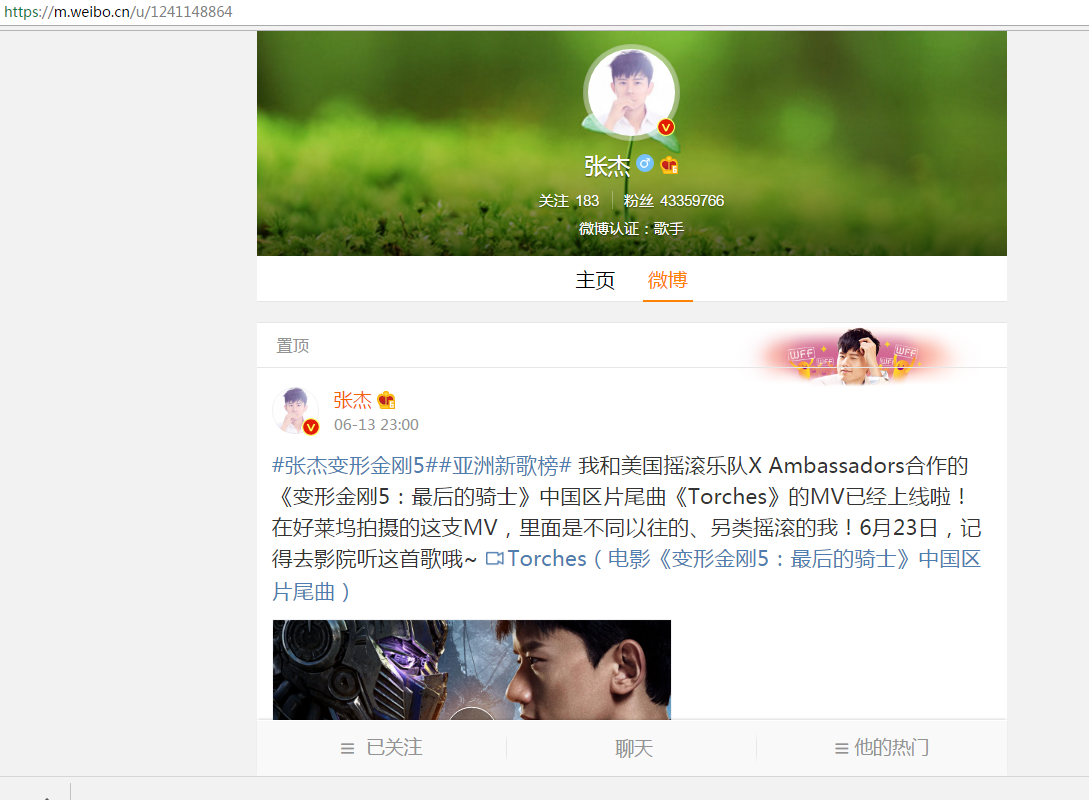
然后就用m.weibo.cn进行网站的爬取,里面的微博和每一条微博里面的评论都是ajax加载的,通过分析加载的数据分析可以得到,每次动态加载都是通过一个xhr进行加载的

表单提交的数据除了这是第页加载的微博之外,其他都是一样的。并且response信息里面有本条xhr信息返回当前xhr包括的所有信息的标识,一个xhr包含9条微博,然后会返回这9条微博的标识,标识是蓝框中的,

然后每条微博的就是https://m.weibo.cn/status/ + 标识
对于每条微博的标识,还没有弄明白...各位大佬知道了告诉我下.谢了
例如:
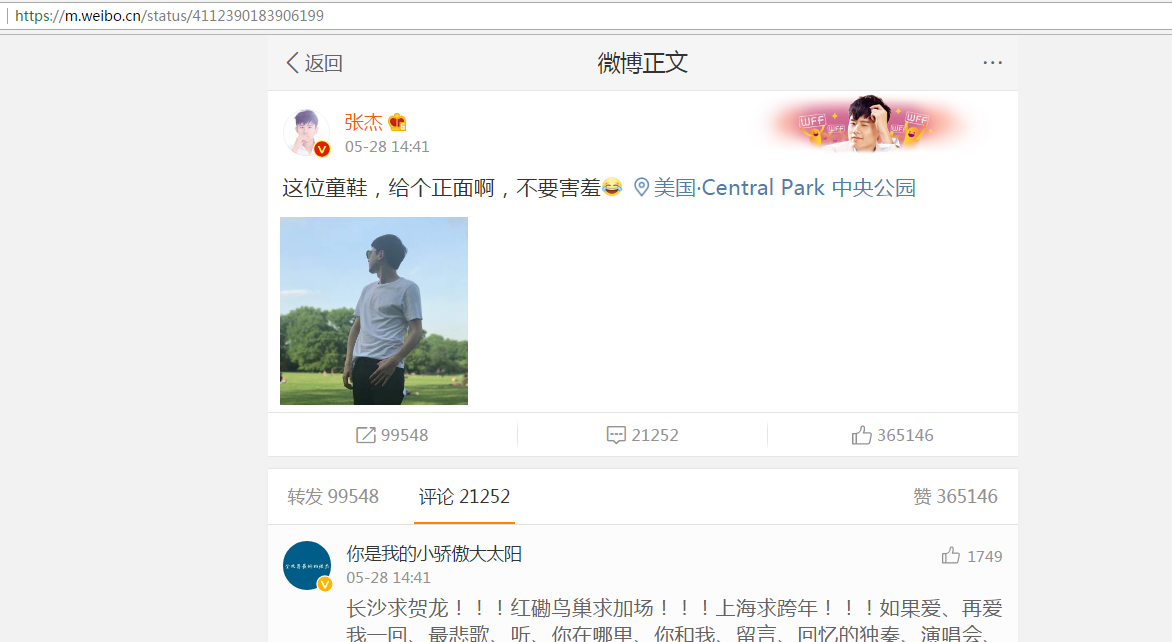
然后ajax加载评论,通过分析加载评论的url只是在后面的page值发生改变,如图:

并且里面的请求头之类的都很容易构造,不同处是当前的page页和当前微博的标识。
有些偷懒没有把每条微博的评论数抓出来,直接是固定多少的评论。
代码如下,不足请指出:
# -*- coding: utf-8 -*- import re import urllib import urllib2 import os import stat import itertools import re import sys import requests import json import time import socket import urlparse import csv import random from datetime import datetime, timedelta import lxml.html from wordcloud import WordCloud import jieba import PIL import matplotlib.pyplot as plt import numpy as np from zipfile import ZipFile from StringIO import StringIO from downloader import Downloader from bs4 import BeautifulSoup from HTMLParser import HTMLParser from itertools import product import sys reload(sys) sys.setdefaultencoding('utf8') import json,urllib2 textmod={"uid":".....", "luicode":"10000011", "lfid":"100103type=3&q=张杰", "featurecode":"20000180", "type":"uid", "value":"....", "containerid":"....." } textmod = json.dumps(textmod) header_dict = {'Connection':'keep-alive', 'Cookie':'', 'Accept-Language':'zh-CN,zh;q=0.8', 'Host':'m.weibo.cn', 'Referer':'............', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36', 'X-Requested-With':'XMLHttpRequest' } def wordcloudplot(txt): path = 'C:UsersAdministratorDownloadsmsyh.ttf' path = unicode(path, 'utf8').encode('gb18030') alice_mask = np.array(PIL.Image.open('E:\aa.jpg')) wordcloud = WordCloud(font_path=path, background_color="white", margin=5, width=1800, height=800, mask=alice_mask, max_words=2000, max_font_size=60, random_state=42) wordcloud = wordcloud.generate(txt) wordcloud.to_file('E:\aa1.jpg') plt.imshow(wordcloud) plt.axis("off") plt.show() def main(): a = [] f = open(r'E:commentqq.txt', 'r').read() words = list(jieba.cut(f)) for word in words: if len(word) > 1: a.append(word) txt = r' '.join(a) wordcloudplot(txt) def get_comment(que): f = open('E:commentqq.txt', 'w') for each in que: for i in range(1,1000): textmood = {"id": each, "page": i} textmood = json.dumps(textmood) uu = 'https://m.weibo.cn/status/' + str(each) header = {'Connection': 'keep-alive', 'Cookie': '.....', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Host': 'm.weibo.cn', 'Referer':uu, 'User-Agent': '......', 'X-Requested-With': 'XMLHttpRequest' } url = 'https://m.weibo.cn/api/comments/show?id=%s&page=%s'%(str(each),str(i)) print url #f.write(url) req = urllib2.Request(url=url, data=textmood, headers=header) res = urllib2.urlopen(req) res = res.read() contents = res d = json.loads(contents, encoding="utf-8") if 'data' in d: data = d['data'] if data != "": for each_one in data: if each_one != "": if each_one['text'] != "": mm = each_one['text'].split('<') if r'回复' not in mm[0]: index = mm[0]#filter(lambda x: x not in '0123456789', mm[0]) print index #index = index.decode("gbk") f.write(index.encode("u8")) def get_identified(): que = [] url = 'https://m.weibo.cn/api/container/getIndex?uid=1241148864&luicode=10000011&lfid=100103type%3D3%26q%3D%E5%BC%A0%E6%9D%B0&featurecode=20000180&type=uid&value=1241148864&containerid=1076031241148864' for i in range(1,10): if i > 1: url = 'https://m.weibo.cn/api/container/getIndex?uid=1241148864&luicode=10000011&lfid=100103type%3D3%26q%3D%E5%BC%A0%E6%9D%B0&featurecode=20000180&type=uid&value=1241148864&containerid=1076031241148864&page='+str(i) print url req = urllib2.Request(url=url, data=textmod, headers=header_dict) res = urllib2.urlopen(req) res = res.read() content = res d = json.loads(content, encoding="utf-8") data = d['cards'] if data != "": for each in data: print each['itemid'] mm = each['itemid'] if mm != "": identity = mm.split('-') num = identity[1][1:] que.append(num) #fd.write(num) #fd.write(' ') print num get_comment(que) if __name__ == '__main__': get_identified() main()
成效:

