【数据库问题】
select Sno,gmark,(select count(Gmark) from grade where gmark>= (select gmark
from grade where Sno = '2000101' order by gmark desc limit 1)) as rank from grade where Sno = '2000101'
类似这种语句都是如何制造的!
1.主键顺序为数据的物理顺序
2.主键不能空,唯一索引可以为空
3.主键每个表只能有一个,而唯一索引可以有多个
4.主键:默认将是聚簇索引 唯一索引:默认将是非聚簇索引
查询每个成绩的分布统计
SELECT Gmark ,COUNT(Gmark) count FROM grade GROUP BY Gmark;
这样只是查询成绩个数,然后获得是第一个成绩,所以count要和group by 一起合用
SELECT Gmark ,COUNT(Gmark) count FROM grade
查询成绩的排名情况:
SELECT
s.Gmark,
(
SELECT
count(Gmark) + 1
FROM
grade sc
WHERE
sc.Gmark > s.Gmark
) AS mingci /*分数相同,名次并列*/
FROM
grade s
ORDER BY
mingci
像这种的意味是有逻辑的执行顺序http://www.cnblogs.com/qanholas/archive/2010/10/24/1859924.html
左连接应用
【意义:让左边为组成行】
查出每门课程的平均成绩,并以成绩升序【默认】
SELECT cname ,AVG(gmark)AS avg_gmark FROM course c LEFT JOIN grade g ON (c.Cno=g.Cno) GROUP BY Cname ORDER BY AVG(gmark)
#做外连接时都是被连接表值不匹配连接表则为空,如果真的是这样就意味着关系完整性被破坏
#将上面的AVG(gmark)改为avg_gmark 也是对的,这有点类似course c
查询01311班选修了1号课程并且成绩不合格的学生的学号、姓名、出生年份。
SELECT * FROM class cl LEFT JOIN student s ON (s.Clno=cl.Clno) LEFT JOIN grade g ON (s.Sno=g.Sno) WHERE g.Cno=1 AND g.Gmark<60 AND cl.Clno='01311'
以要查的字段在第一张表class 因此class要向其他通过外键关联进行查询!
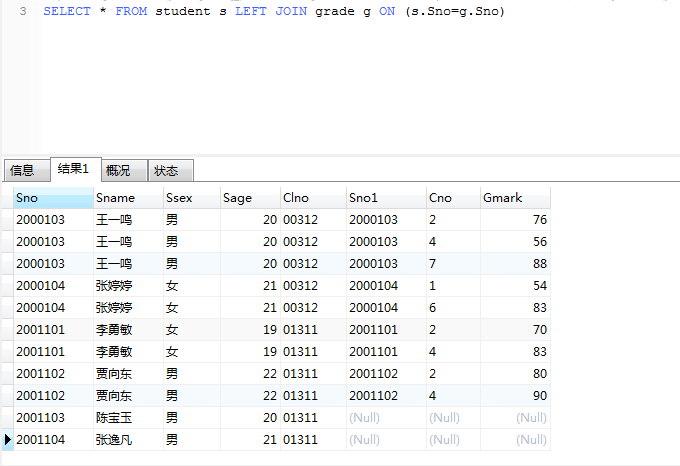
有两个没有选择课程和成绩,这样结果集也能得到谁没有选择课程
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面(重要)
例如,有如下数据库表:
A B
1 abc
1 bcd
1 asdfg
如果有如下查询语句(该语句是错误的,原因见前面的原则)
select A,B from table group by A
该查询语句的意图是想得到如下结果(当然只是一相情愿)
A B
abc
1 bcd
asdfg
右边3条如何变成一条,所以需要用到聚合函数,如下(下面是正确的写法):
select A,count(B) as 数量 from table group by A
这样的结果就是
A 数量
1 3
2. Having
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
having 子句被限制子已经在SELECT语句中定义的列和聚合表达式上。通常,你需要通过在HAVING子句中重复聚合函数表达式来引用聚合值,就如你在SELECT语句中做的那样。例如:
SELECT A COUNT(B) FROM TABLE GROUP BY A HAVING COUNT(B)>2
3.使用compute和compute by
使用compute子句允许同时观察查询所得到各列的数据的细节以及统计各列数据所产生的汇总列
select * from work [查询所得到的各列的数据的细节]
compute max(基本工资),min(基本工资) [统计之后的结果]
这个例子中没有使用by关键字,返回的结果是最后添加了一行基本工资的最大值和最小值,也可增加by关键字.
例:select * from work order by 学历
compute max(基本工资),min(基本工资) by 学历
比较:select 学历,max(基本工资),min(基本工资) from work group by 学历
说明:1:compute子句必须与order by子句用在一起
2:compute子句可以返回多种结果集.一种是体现数据细节的数据集,可以按分类要求进行正确的分类;另一种在分类的基础上进行汇总产生结果.
3:而group by子句对每一类数据分类之后只能产生一个结果,不能知道细节
示例学习Northwind数据库:
非相关查询:
1:返回每个美国员工都为其处理过订单的所有客户
--思路:1:Employees表中获取美国员工总数2:Orders表中查询美国员工处理的Order,对CustomerID分组后,统计其不同的EmployeeID正好等于美国员工总数
Select CustomerID From Orders Where EmployeeID In --得到美国员工服务 的客户
(Select EmployeeID From Employees Where Country=N'USA') -- 得到全部美国员工id
group by CustomerID --按客户分组
Having Count(Distinct EmployeeID)= --为其处理订单的distinct 员工数等于美国总员工数
(Select Count(*) From Employees Where Country=N'USA')--美国员工总数
2:
返回在每月最后实际订单日期发生的订单(每月最后订单日期可能不是每月最后一天)
--思路:子查询按月分组得到每月最近订单日期
Select OrderID,CustomerID,EmployeeID,OrderDate
From Orders
Where OrderDate In
(Select Max(OrderDate) From Orders Group by Convert(char(6),OrderDate,112))--112表示YYYYMMDD char(6)提取YYYYMM
3.
Select字句在逻辑上是SQL语句最后进行处理的最后一步,所以,以下查询会发生错误:
SELECT OrderYear, COUNT(DISTINCT CustomerID) AS NumCusts
FROM (SELECT YEAR(OrderDate) AS OrderYear, CustomerID
FROM dbo.Orders) AS D
GROUP BY OrderYear
;因为group by是在Select之前进行的,那个时候orderYear这个列并没有形成。
如果要查询成功,可以像下面进行修改:
SELECT OrderYear, COUNT(DISTINCT CustomerID) AS NumCusts
FROM (SELECT YEAR(OrderDate) AS OrderYear, CustomerID
FROM dbo.Orders) AS D
GROUP BY OrderYear;还有一种很特殊的写法:
SELECT OrderYear, COUNT(DISTINCT CustomerID) AS NumCusts
FROM (SELECT YEAR(OrderDate), CustomerID
FROM dbo.Orders) AS D(OrderYear, CustomerID)
GROUP BY OrderYear;在作者眼里,他是非常喜欢这种写法的,因为更清晰,更明确,更便于维护。
在查询中使用参数定向产生一批结果,这个技巧没有什么好说的。
嵌套查询,在处理逻辑上是从里向外进行执行的。