reduce和reduceByKey的区别
reduce(binary_function)
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
具体过程,RDD有1 2 3 4 5 6 7 8 9 10个元素,
1+2=3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
reduceByKey(binary_function)
reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
那么讲到这里,差不多函数功能已经明了了,而reduceByKey的是如何运行的呢?下面这张图就清楚了揭示了其原理:
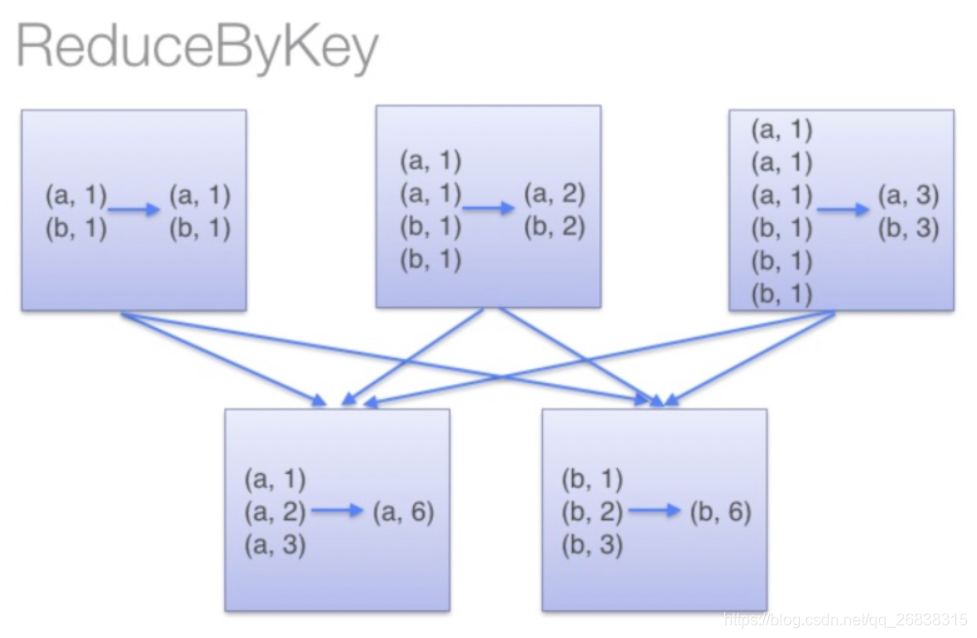
亦即,它会在数据搬移以前,提前进行一步reduce操作。
可以实现同样功能的还有GroupByKey函数,但是,groupbykey函数并不能提前进行reduce,也就是说,上面的处理过程会翻译成这样:
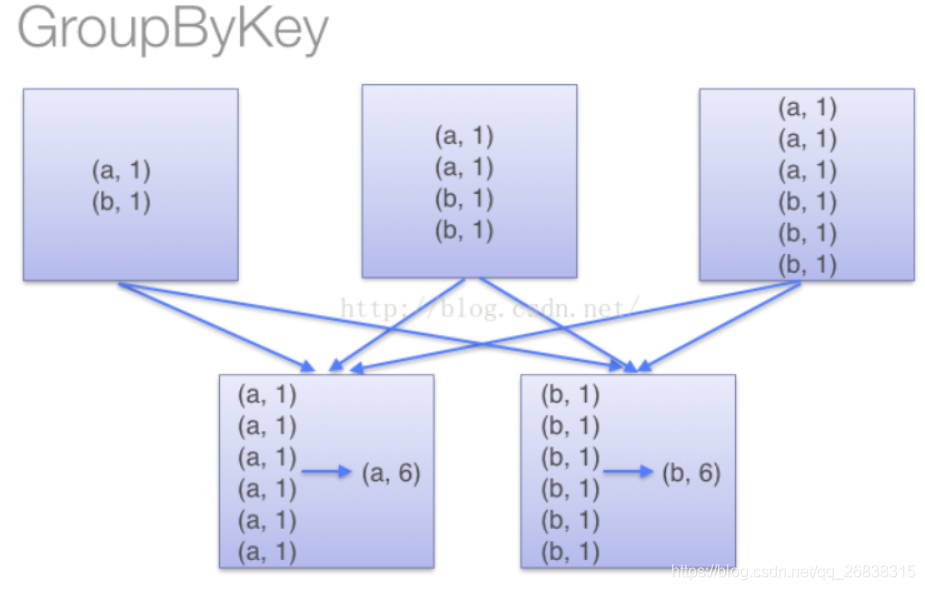
所以在处理大规模应用的时候,应该使用reduceByKey函数。
reduceByKey(func)和groupByKey()的区别
reduceByKey()对于每个key对应的多个value进行了merge操作,最重要的是它能够先在本地进行merge操作。merge可以通过func自定义。
groupByKey()也是对每个key对应的多个value进行操作,但是只是汇总生成一个sequence,本身不能自定义函数,只能通过额外通过map(func)来实现。
[外链图片转存失败(img-apqvvyes-1563674971456)(img/1563672147038.png)]
使用reduceByKey()的时候,本地的数据先进行merge然后再传输到不同节点再进行merge,最终得到最终结果。
而使用groupByKey()的时候,并不进行本地的merge,全部数据传出,得到全部数据后才会进行聚合成一个sequence,
groupByKey()传输速度明显慢于reduceByKey()。
虽然groupByKey().map(func)也能实现reduceByKey(func)功能,但是,优先使用reduceByKey(func)