spark算子集合
文章目录
- spark算子集合
- 1.Transformation算子
- map/mapToPair
- mapPartitions
- mapPartitionWithIndex
- flatMap/flatMapToPair
- filter
- sample
- reduceByKey
- sortByKey/sortBy
- join
- leftOuterJoin
- rightOuterJoin
- fullOuterJoin
- union
- intersection
- subtract
- distinct
- cogroup
- zip
- zipWithIndex
- repartition
- coalesce
- groupByKey
- 2.Action算子
- 3.持久化算子
- reduce和reduceByKey的区别
- reduceByKey()和groupByKey()的区别
算子:Spark中,RDD的方法就叫算子(也叫函数)如flatMap,map,reduceByKey,foreach
Spark中的算子分为三类:
-
Transformation转换算子 [懒执行的,需要Action算子触发才执行]
map,flatMap,reduceByKey,sortBy(java不存在这个),sortByKey,filter,sample
-
Action行动算子 [触发Transformation类算子执行,有一个Action算子,就有一个job(任务)]
foreach,take,first,count,collect
-
持久化算子

1.Transformation算子
又叫转换算子,懒执行,需要Action算子触发执行
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行(需要Action算子触发才能执行)。
map/mapToPair
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
Scala只有map,Java中有map,mapToPair
Java中map输出的不能输出kv格式,要想输出kv格式数据要是用mapToPair
mapToPair会将一个长度为N的、每个元素都是T类型的对象,转换成另一个长度为N的、每个元素都是<K2,V2>类型的对象
mapPartitions
- 与map类似,遍历的单位是每个partition上的数据。
- 一个分区一个分区的数据来处理
- 传入的参数是一个partition的数据
- 单位按分区来处理数据节省某些操作需要的时间
mapPartitionWithIndex
类似于mapPartitions,除此之外还会携带分区的索引值。可获取每个分区的索引
flatMap/flatMapToPair
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
scala只有flatMap
java有flatMap和flatMapToPair,flatMapToDouble
Java中flatMap输出的不能输出kv格式,要想输出kv格式数据要是用flatMapToPair
filter
保留符合条件的记录数,true保留,false过滤掉。
sample
随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。
第一个参数:是否有放回 第二个参数:抽样抽多少数据(百分比),第三个参数:种子
对RDD进行抽样,其中参数withReplacement为true时表示抽样之后还放回,可以被多次抽样,false表示不放回;fraction表示抽样比例;seed为随机数种子,比如当前时间戳
reduceByKey
将相同的Key根据相应的逻辑进行处理。
reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
sortByKey/sortBy
作用在K,V格式的RDD上,对key进行升序或者降序排序。
join
作用在K,V格式的RDD上。根据K进行连接,对(K,V)join(K,W)返回(K,(V,W))
- 必须是两个k、v格式的RDD进行join,且key必须相同
- 只返回相同key的
- join后的分区数默认与父RDD分区数多的那一个相同。
- 如果join指定了分区数则按照指定的分区进行
- 注: 不设置的话分区数默认为1.
leftOuterJoin
显示左边RDD所有的key和value,右边RDD对应不上的用optional
rightOuterJoin
显示右边RDD所有的key和value,左边RDD对应不上的用optional
fullOuterJoin
两边RDD均显示,不存在用optional,显示None
union
合并两个数据集。两个数据集的类型要一致。
- 返回新的RDD的分区数是合并RDD分区数的总和。
- 逻辑上合并,不会有实际的数据传输
intersection
取两个数据集的交集,返回新的RDD与父RDD分区多的一致
subtract
- 取两个数据集的差集,结果RDD的分区数与subtract前面的RDD的分区数一致。
- 取左边RDD中右边RDD没有的元素
distinct
去重
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
cogroup
将两个RDD中相同key的合在一起
当调用类型(K,V)和(K,W)的数据上时,返回一个数据集(K,(Iterable<V>,Iterable<W>)),子RDD的分区与父RDD多的一致。
zip
zip函数用于将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,**两个RDD的每个分区元素个数必须相同。
zipWithIndex
该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对。
repartition
增加或减少分区。宽依赖的算子,默认产生shuffle。(多个分区分到一个分区不会产生shuffle)
repartition底层其实就是coalesce指定了开启shuffle,变成宽依赖
repartition()一般用于增加分区
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
coalesce
重分区,可以将RDD的分区增大,也可以减少,默认不产生shuffle.
coalesce常用来减少分区,第二个参数是减少分区的过程中是否产生shuffle。true为产生shuffle,false不产生shuffle。默认是false。
Coalesec()一般用于减少分区。Coalesec()方法不产生shuffle的话增加分区就不起作用,但如果指定产生shuffle的话那就是repartition()。
如果coalesce设置的分区数比原来的RDD的分区数多的话,第二个参数设置为false时不会起作用,分区情况不会变化,如果设置成true,效果和repartition一样。即repartition(numPartitions) = coalesce(numPartitions,true)
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
groupByKey
作用在K,V格式的RDD上。根据Key进行分组,将相同key的聚合到一起。作用在(K,V),返回(K,Iterable <V>)。会产生shuffle
对每个key对应的多个value进行操作,但是只是汇总生成一个sequence,本身不能自定义函数,只能通过额外通过map(func)来实现。
2.Action算子
Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。
Transformations类算子是延迟执行,Action类算子触发Transformations类算子执行。
一个application应用程序中有几个Action类算子执行,就有几个job运行。
count
返回数据集中的元素数。会在结果计算完成后回收到Driver端。
foreach
循环遍历数据集中的每个元素,运行相应的逻辑。
take
take(n)返回一个包含数据集前n个元素的集合。
first
first=take(1),返回数据集中的第一个元素。
collect
将计算结果回收到Driver端。
foreachPartition
遍历的数据是每个partition的数据。
以分区为单位进行遍历 可以避免重复建立连接等
foreach以每一条数据为单位遍历
没有返回值(mapPartitions有返回RDD)
countByKey
必须作用到K,V格式的RDD上,根据Key计数相同Key的数据集元素。
def countByKey(): Map[K, Long] = self.withScope {
self.mapValues(_ => 1L).reduceByKey(_ + _).collect().toMap
}
countByValue
根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。(不必作用在kv格式上)
countByValue()方法将整个元组看做value,不是将逗号后面的内容看做value
def countByValue()(implicit ord: Ordering[T] = null): Map[T, Long] = withScope {
map(value => (value, null)).countByKey()
}
reduce
根据聚合逻辑聚合数据集中的每个元素。
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
3.持久化算子
持久化有三个算子:
- Cache
- Persist
- checkpoint
以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
cache
默认将数据存于内存中,相当于指定了只是用内存存储策略的persist
默认将RDD的数据持久化到内存中。**cache是懒执行。**需要Action算子触发执行
cache和persist不需要指定目录,spark集群会默认为cache,persist创建目录
cache和persist的目录在application执行完后会清空
cache()=persist()=persist(StorageLevel.MEMORY_ONLY)
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)//只用内存
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
注意:cache和persist算子后不能立即紧跟action算子。(如:lines.cache().collect()是不行的)
var lines = sc.textFile("./data/words")
//如果赋值给变量,后面不能紧跟action算子
// lines = lines.cache().foreach()
lines = lines.cache()
lines = lines.persist()
persist
可以手动指定持久化级别.最常用的是MEMORY_ONLY和MEMORY_AND_DISK。”_2”表示有副本数。
cache和persist不需要指定目录,spark集群会默认为cache,persist创建目录
cache和persist的目录在application执行完后会清空
持久化级别如下:
class StorageLevel private(
private var _useDisk: Boolean,//是否使用磁盘
private var _useMemory: Boolean,//是否使用内存
private var _useOffHeap: Boolean,//是否使用堆外内存(一般不会使用)
private var _deserialized: Boolean,//是否不序列化
private var _replication: Int = 1)//副本
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)//先往内存中放,不够了再往磁盘放,以块为单位
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
常用级别:
- MEMORY_ONLY
- MEMORY_ONLY_SER
- MEMORY_AND_DISK 先往内存中放,不够了再往磁盘(放磁盘的数据一定会序列化)放,以块为单位
- MEMORY_AND_DISK_SER
尽量避免使用"_2"的级别和DISK_ONLY级别
放磁盘的数据一定会序列化
堆外内存:不归JVM管的内存就是堆外内存
Spark存储数据可以指定副本个数
checkpoint
当RDD的lineage非常长,计算逻辑复杂时,可以对某个RDD进行checkpoint,会将当前的数据持久化到指定的磁盘目录上.
-
checkpoint默认将RDD数据持久化到磁盘,还可以切断RDD之间的依赖关系。
可以保存数据到外部存储系统。(可以解决宕机问题,宕机时保存状态,数据执行到哪里了的问题),切断依赖关系。
-
checkpoint需要自己指定目录
-
checkpoint主要用在元数据保存上
-
checkpoint目录数据当application执行完之后不会被清除,不手动删除就会一直存在。
第二次再次访问同一个RDD时,就会从上次持久化的checkpoint持久化数据中获取。
-
checkpoint相比cache和persist多了一个功能:存储元数据.checkpoint真正用在持久化数据上用的其实并不多
checkpoint特点
可以对RDD进行checkpoint,将数据存储在外部的文件存储系统,当spark application执行完成之后,数据不会被清除.正是这个特点,我们可以使用checkpoint保存状态.在sparkstreaming中应用多
作用:
- 将数据持久化到磁盘
- 保存程序运行状态
设置了checkpoint之后,会将这个RDD向前切断RDD的依赖关系
一定要避免对RDD进行多次checkPoint。千万不要经常的对RDD进行checkpoint,因为每次checkpoint一次就会存到磁盘一次,过多存储就会和mapreduce在磁盘存储一样了,这样会让性能下降
checkpoint流程
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
- 回溯完成后,Spark框架会自动启动一个新的job,重新计算这个checkpoint RDD的数据,将数据持久化到HDFS的指定目录上。
- 下一步会向前切断RDD的依赖关系,下次如果checkpoint标记的RDD后的RDD数据丢了后,可以使用checkpoint这个目录去恢复后面的RDD的数据,不用再向前去找了,节省了时间
比如,要计算打五角星的这个RDD的数据,在这个job执行完成之后,会重新从数据的源头重新计算一遍之前的一个RDD中的数据并存放于程序中指定的外部存储目录。默认是将数据持久化到磁盘。
当下次重新计算五角星的RDD中的数据时,会直接从checkPoint的RDD中恢复数据,而不会从之前的有依赖关系的RDD中计算数据
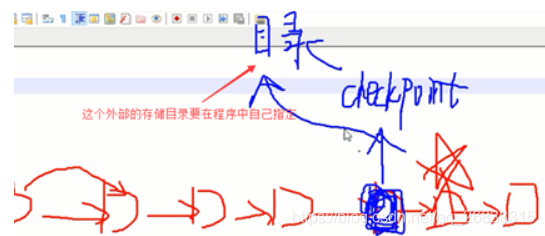
当最后一个RDD的action执行完时,会重启一个job,从后往前回溯,一直回溯到源头,找到那些被标记成checkpoint的RDD的数据,重新计算该数据,将该数据存放到程序中指定的外部存储目录(一般是HDFS上的某个目录),下一步会向前切断RDD的依赖关系,下次如果checkpoint标记的RDD后的RDD数据丢了后,可以基于checkpoint这个目录去恢复后面的RDD的数据
checkpoint的优化
对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。
对哪个RDD设置了checkPoint就对其进行cache持久化,action类算子触发cache持久化将数据存入内存中。当新建的job进行回溯时发现内存中存在数据,就会直接将内存中数据持久化到外部存储目录中,就省去了重新计算的这一步。
一定要避免对RDD进行多次checkPoint。千万不要经常的对RDD进行checkpoint,因为每次checkpoint一次就会存到磁盘一次,过多存储就会和mapreduce在磁盘存储一样了,这样会让application执行缓慢
注意
-
cache和persist都是懒执行,必须有一个action类算子触发执行,最小单位是partition。
-
cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
-
cache和persist算子后不能立即紧跟action算子。(如:lines.cache().collect()是不行的)
-
cache和persist算子持久化的数据当applilcation执行完成之后会被清除。
-
cache和persist不需要指定目录,spark集群会默认为cache,persist创建目录
cache和persist的目录在application执行完后会清空
错误:rdd.cache().count() 返回的不是持久化的RDD,而是一个数值了。
-
checkpoint相比cache和persist多了一个功能:存储元数据.checkpoint真正用在持久化数据上用的其实并不多,还可以切断RDD之间的依赖关系
-
checkpoint需要指定目录,cache和persist不需要指定目录,spark集群会默认为cache,persist创建目录
cache和persist的数据在application执行完后会自动清空
checkpoint的数据不会被清空
Checkpoint的数据可以由外部的存储系统管理。程序运行结束后,目录仍然不会被删除。
-
checkpoint由外部的存储系统管理,persist是由Spark内部管理
-
checkpoint可以将状态保存到外部,Spark可以基于外部的存储状态恢复
reduce和reduceByKey的区别
reduce(binary_function)
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
具体过程,RDD有1 2 3 4 5 6 7 8 9 10个元素,
1+2=3
3+3=6
6+4=10
10+5=15
15+6=21
21+7=28
28+8=36
36+9=45
45+10=55
reduceByKey(binary_function)
reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。
那么讲到这里,差不多函数功能已经明了了,而reduceByKey的是如何运行的呢?下面这张图就清楚了揭示了其原理:
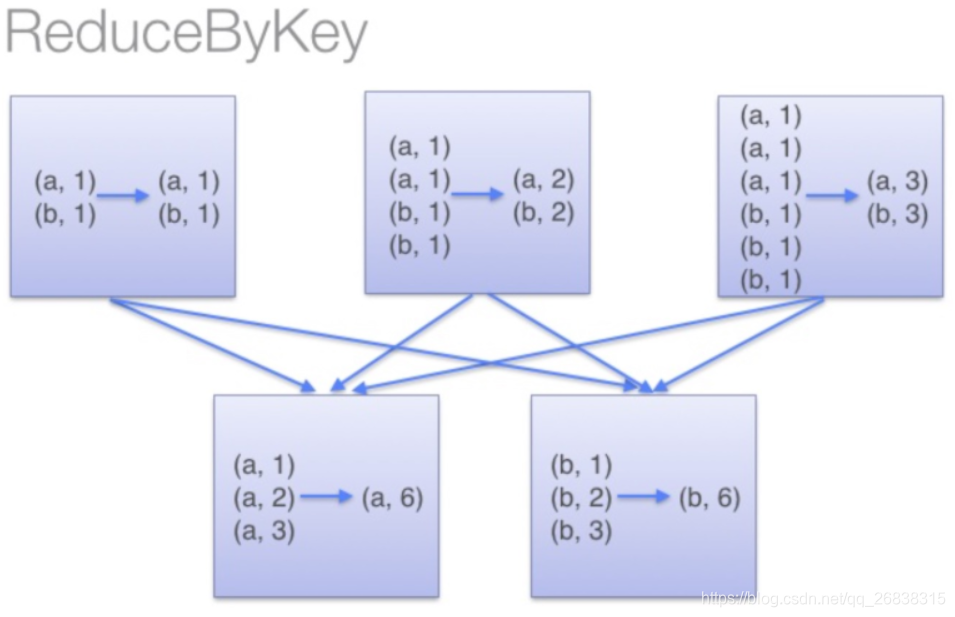
亦即,它会在数据搬移以前,提前进行一步reduce操作。
可以实现同样功能的还有GroupByKey函数,但是,groupbykey函数并不能提前进行reduce,也就是说,上面的处理过程会翻译成这样:
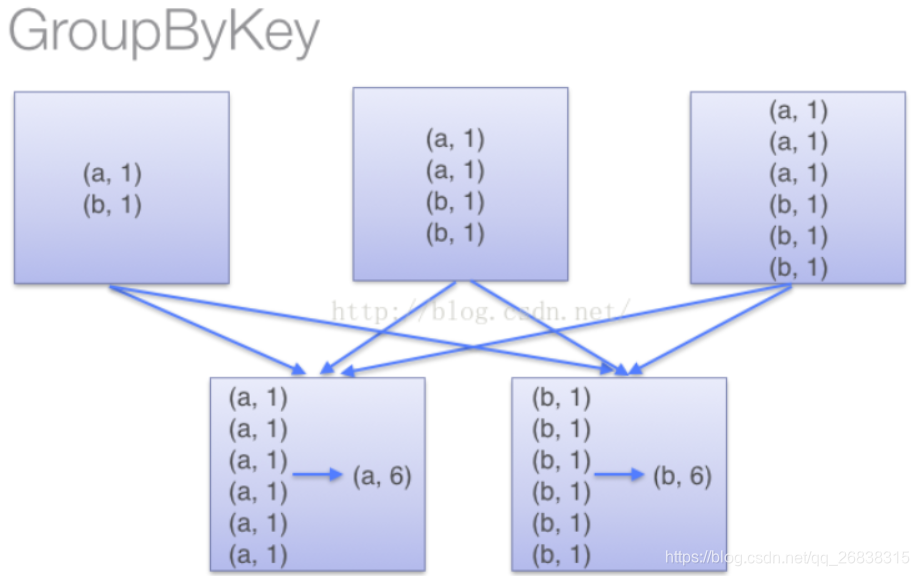
所以在处理大规模应用的时候,应该使用reduceByKey函数。
reduceByKey()和groupByKey()的区别
reduceByKey()对于每个key对应的多个value进行了merge操作,最重要的是它能够先在本地进行merge操作。merge可以通过func自定义。
groupByKey()也是对每个key对应的多个value进行操作,但是只是汇总生成一个sequence,本身不能自定义函数,只能通过额外通过map(func)来实现。
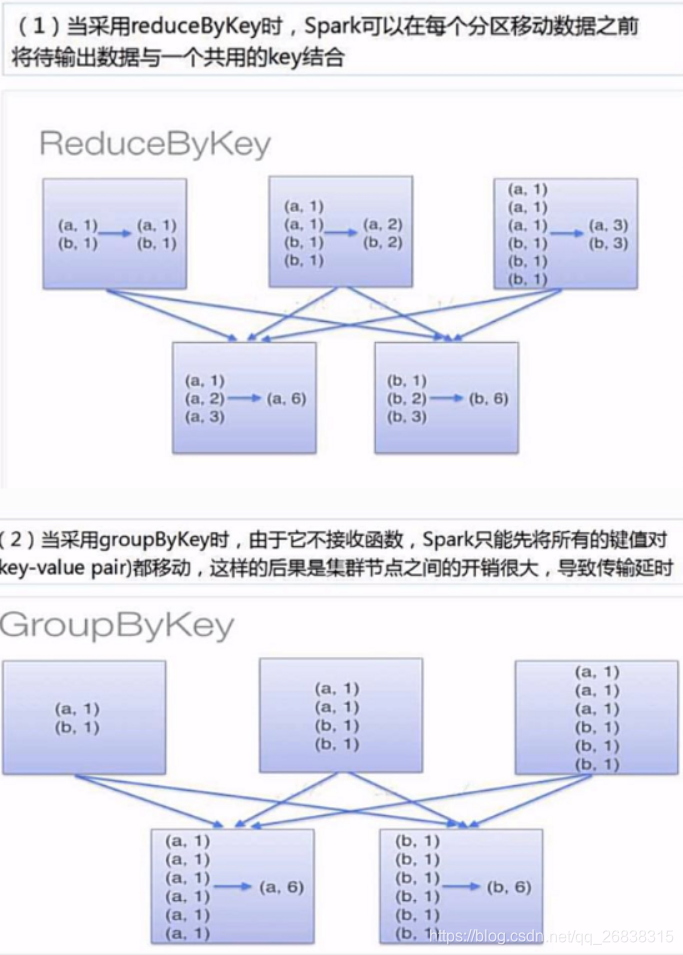
使用reduceByKey()的时候,本地的数据先进行merge然后再传输到不同节点再进行merge,最终得到最终结果。
而使用groupByKey()的时候,并不进行本地的merge,全部数据传出,得到全部数据后才会进行聚合成一个sequence,
groupByKey()传输速度明显慢于reduceByKey()。
虽然groupByKey().map(func)也能实现reduceByKey(func)功能,但是,优先使用reduceByKey(func)