以房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5)
关于这两个特征向量的代价函数如下图所示:
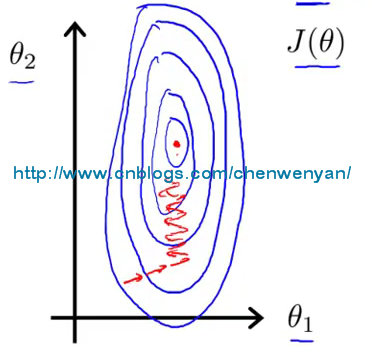
从上图可以看出,代价函数是一个又瘦又高的椭圆形轮廓图,如果用这个代价函数来运行梯度下降的话,得到最终的梯度值,可能需要花费很长的时间,甚至可能来回震动,最终才能收敛到全局最小值。为了减少梯度下来花费的时间,最好的办法就是对特征向量进行缩放(feature scaling)。
特征向量缩放(feature scaling):具体来说,还是以上面的房屋价格为例,假设有两个特征向量:X1:房子大小(1-2000 feets), X2:卧室数量(1-5),现在将它们转化为如下公式:

即将房子大小除以2000,卧室的数量除以5.
这个时候代价函数就会变得比较圆,计算最终梯度值的速度也会随之变快,如下图所示:

一般情况下,我们进行特征向量缩放的目的是将特征的取值约束到[-1 ,1]之间,而特征X0恒等于1,[-1,1]这个范围并不是很严格的,事实上,假如存在特征向量X1,其缩放以后为[0,3]或者[-2,0.5]之间,这也是允许的。但是如果是在[-100,100]或者[-0.0001,0.0001]之间,则是不允许的,跟[-1,1]差距太大了。
将特征向量除以最大值是特征缩放的其中一种方式,还有另一种方式是均值归一化(mean normalization),其思想如下:
假设将特征向量Xi用Xi-μi代替,使其均值接近0,假设房子平均大小为1000 feets,平均卧室数量为2,则特征向量可以转化为如下公式:
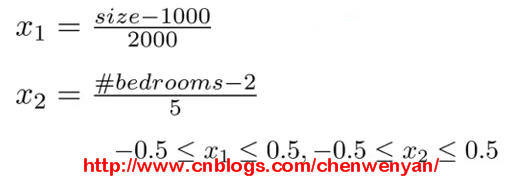
一般情况下,可以用X1来代替原来的特征X1,具体公式如下:
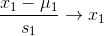
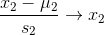
x1,x2指的是原来的特征向量,u1,u2指的是在训练集中,特征向量x1,x2分别的平均值,s1,s2指的是该特征值的范围(即最大值减去最小值),也可以把s1,s2改为变量的标准差