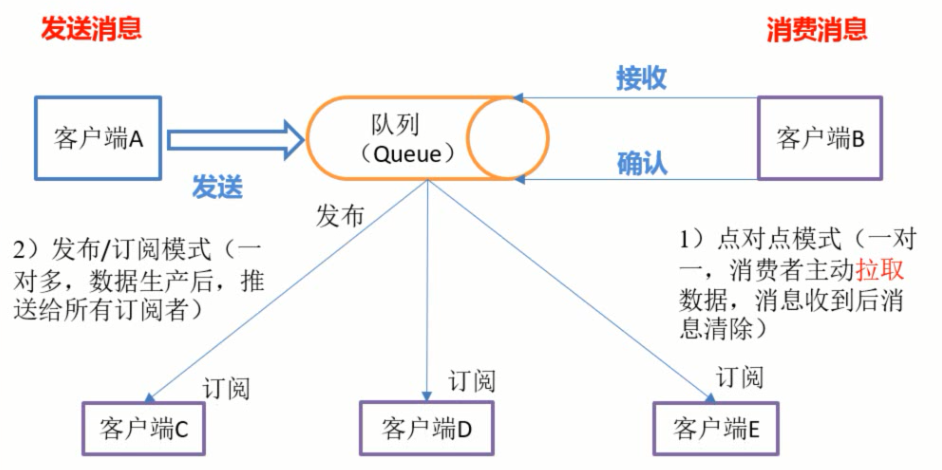
Kafka有两种模式:
点对点模式:消费者主动从Kafka中定时轮询的拉取数据,一条数据只会发送给customer group中的一个customer进行消费。
发布订阅者模式:kafka主动推送数据到所有订阅了该类信息的客户端。
Kafka中通过控制Customer的参数{group.id}来决定kafka是什么数据消费模式,如果所有消费者的该参数值是相同的,那么此时的kafka就是队列模式,数据只会发送到一个customer,此时Kafka类似于负载均衡;否则就是发布订阅模式; 在队列模式下,可能会触发Kafka的Consumer Rebalance
kafka是依赖Zookeeper的,kafka中节点的状态信息和消费者的消费消息的状态信息会保存在zookeeper中,且zookeeper只保存这两点信息
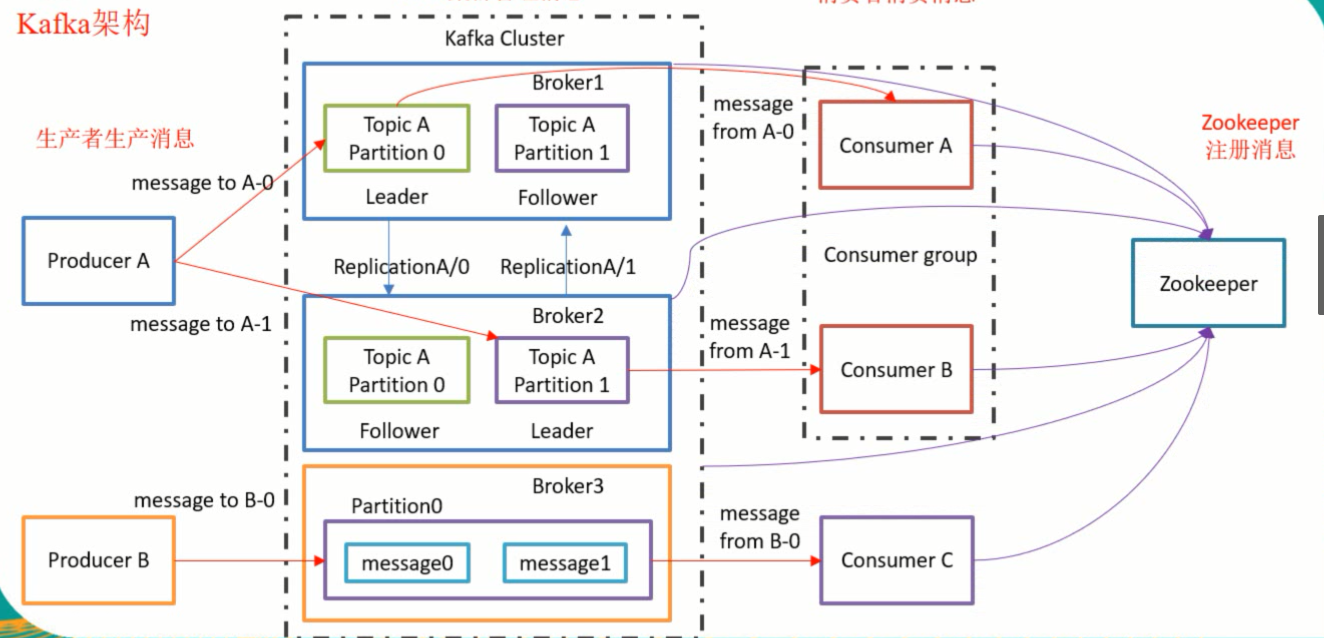
kafka中存在几个概念:Broker、Topic、Partition
Broker:为一个节点,每开启一个kafka服务就会有一个Broker
Topic:为主题。kafka中消息是分类别的,kafka是通过topic来为消息分类的,每一个topic代表着一种消息类型。同一个topic可以存在于多个Broker中
Partition:为分区,分区存在于topic中,每个topic中会存在多个分区。在Kafka中分区是操作的最小单元,生产者生产的消息必须存储在topic中的某一个分区上。消息存放在哪个分区是根据消息的Key的哈希值来确定的。分区本身是以队列的形式保存消息的。
每个分区的消息是有序的,多个分区间的消息是无序的。
冗余机制replication
Partition分区分主从即Leader和Follower,Follower不会进行任何与客户端的交互,即不会与生产者或消费者沟通,它的唯一的作用是实时的从Leader角色的Partition中同步备份数据,起到高可用的作用。如果作为Leader角色的broker节点宕机了,Follower会自动升级为Leader继续同生产者、消费者沟通。
同一个分区可以存在于多个broker节点中,同一个Topic主题存在多个分区,每个分区会有主(Leader)有备(Follower),主分区和备分区会交错的存在于不同的broker节点。如上图所示有主题topicA存在于节点broker1和broker2中,topicA中存有分区Partition0和Partition1,broker1中的分区Partition0作为leader,
Zookeeper的作用
kafka集群依赖zookeeper,zookeeper在kafka集群中起者两点作用
1、zookeeper会保存整个集群中broker节点的状态信息。当作为leader的broker节点宕机时,作为Follower的broker节点会自动升级为Leader,然而Follower是如何知道Leader已经挂掉呢,这个时候zookeeper会通过心跳包检测Leader的状态,当接收不到心跳后便会认为它挂掉了,然后选举一个Follower作为Leader重新开始与生产者、消费者保持通信。
2、zookeeeper会保存消费者的消费消息状态。kafka中每一个分片都是一个队列,当Consumer消费消息时,队列的下标(也叫偏移量offset)会移动,当集群因为某些原因关机了或挂掉了,我们再次重启集群进行消费时怎么知道上次消费到什么位置了,怎么确定队列的偏移量。这个时候zookeeper就起作用了。zookeeper保存了这些状态信息,Consumer可从zookeeper中读取到上次消费的位置,继续未完成的消费。当然也可以重置偏移量offset从头开始消费,因为kafka中的消息会持久化到磁盘中,默认会保存7天。
消费者group组:创建消费者的时候可指定属于哪个组,group组有几个特点:
1、同一时刻一个group组只能有一个消费者去消费数据
2、同一个group组中的消费者是不会重复消费消息的
3、消费者消费消息是以Partition为单元的。消费者会和某一个Partition建立连接,一旦这个连接建立成功,该Partition中的消息都由这个消费者消费,而不会交给同组的其他消费者。
二、生产者写入流程
1、生产者发送消息如何存储的
切换到/tmp/kafka-logs,也就是我们在server.properties文件中配置的log.dirs
cd /tmp/kafka-logs
可以查看到如下内容:

first-0为我们的Partition分区文件,first为我们添加的主题,0为分区,每一个分区被分配为一个文件,存储生产者发送的消息
2、分区原则
发布到Kafka集群的消息体分为三部分:key(键值)、partition(分区号)、value(数据值)
(1)如果指定partition,则直接使用该分区,key会被忽略
(2)未指定partition但指定key,通过key的值进行hash选一个分区
(3)如果不指定key和partition,kafka会采用默认的平均轮询将数据平均分配到每一个分区上。
3、发送消息过程
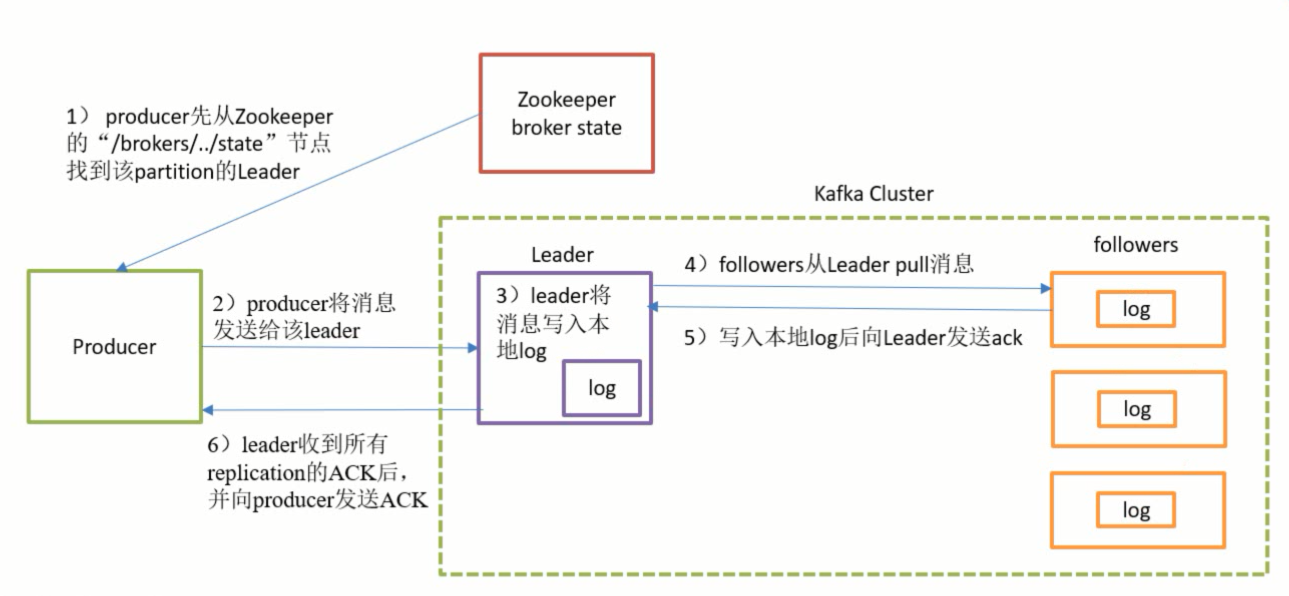
(1)Producer从Zookeeper获取Kafka集群各节点状态,找出Leader节点
(2)发送消息给Leader节点,持久化消息到log文件中
(3)Follower主动拉取Leader的数据 ,实现数据同步
(4)Follower发送ack确认响应 注:在所有follower同步数据完成之前,这些数据对Consumer是不可见的、不能消费的
三、消费流程
消息消费的模式有两种:推送模式(push)和 拉取模式(pull)
- 推送模式:kafka集群主动推送数据到Consumer,推送模式不保证消息推送成功,它不管Consumer的资源使用情况,可能会由于Cousumer正处理其它事情,导致数据丢失
- 拉取模式:由Cousumer主动拉取,可以控制最高水位,消息消费完成后处于等待状态,推荐使用。