
Sqoop:SQL-to-Hadoop (点击查看官方英文文档)
这个链接是简洁的中文教程:https://www.yiibai.com/sqoop/sqoop_import_all_tables.html
Sqoop连接传统关系型数据库 和 Hadoop 的工具
Sqoop是一个转换工具,用于在关系型数据库与Hive等之间进行数据转换
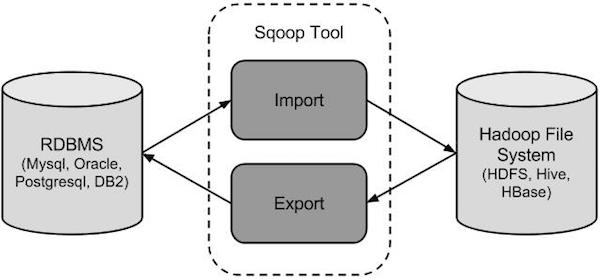
Sqoop导入
导入工具从RDBMS到HDFS导入单个表。表中的每一行被视为HDFS的记录。所有记录被存储在文本文件的文本数据或者在Avro和序列文件的二进制数据。
Sqoop导出
导出工具从HDFS导出一组文件到一个RDBMS。作为输入到Sqoop文件包含记录,这被称为在表中的行。那些被读取并解析成一组记录和分隔使用用户指定的分隔符。
我的git(点击3实现hive数据仓库)
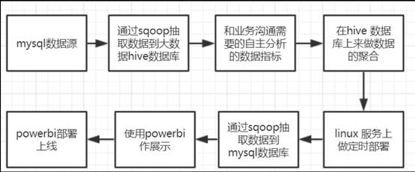
步骤:
- Sqoop抽取mysql数据到hive
- 和业务沟通需要的自主分析的数据指标,
- 在hive上做数据的聚合.
- linux服务器上的定时部署
- sqoop抽取数据到mysql
- 使用bi做展示,线上部署
Sqoop 工具的命令格式
Sqoop是一系列相关工具的集合,它的基本命令格式:
$ sqoop tool-name [tool-arguments]
帮助方法:
$ sqoop help [tool-name] 或者 $sqoop [tool-name] --help
Sqoop的导入
$ sqoop import (generic-args) (import-args)
例子:
$ sqoop import --connect jdbc:mysql://localhost/db --username foo --table TEST $ sqoop --options-file /users/homer/work/import.txt --table TEST ⚠️import.txt内包括:
import
--connect
jdbc:mysql://localhost/db
--username
foo
⚠️jdbc是Java数据库连接,Java Database Connectivity,简称JDBC。
重要的参数
表1常用参数:
| Argument | Description |
|---|---|
--connect <jdbc-uri> |
Specify JDBC connect string |
--connection-manager <class-name> |
Specify connection manager class to use |
--driver <class-name> |
Manually specify JDBC driver class to use |
--hadoop-mapred-home <dir> |
Override $HADOOP_MAPRED_HOME |
--help |
Print usage instructions |
--password-file |
Set path for a file containing the authentication password |
-P |
Read password from console |
--password <password> |
Set authentication password |
--username <username> |
Set authentication username |
--driver参数:
Sqoop可以使用任何JDBC数据库,但首先要下载相对应的JDBC驱动,并安装。
例如: Mysql的驱动com.mysql.jdbc.Driver
--connect <jdbc-uri> 的参数对儿看:https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-configuration-properties.html
附加:

useUnicode=true #To use 3-byte UTF8 with Connector/J characterEncoding=utf-8 #What character encoding should the driver use when dealing with strings? (defaults is to 'autodetect') zeroDateTimeBehavior=convertToNull #当遇到datetime数据:0000-00-00这样全是0的,转化为null tinyInt1isBit=false #TINYINT(1) as the BIT type默认是true,改成false的话,就是数字1了。 dontTrackOpenResources=true# 防止内存泄露的。会自动close(), 默认false。 defaultFetchSize=50000 #和下面的useCursorFetch配合使用的。每次最多取n行数据。原因大概如下: # 简单说就是大数据,小内存放不下,就用这个2个参数 useCursorFetch=true #使用cursor这种方式得到row,不是很理解。
选择导入的数据
--table employees #导入表
--columns "列名,列名, ..." #选择要导入的列
--where "条件" #设置导入条件
自由表格的查询导入
--query “标准的select语句”
配套的参数:
--target-dir "HDFS绝对路径"
是否用并行的方式导入数据:
如果是,则每个map任务将需要执行这个query的副本,结果由绑定的conditions分组。
- query内需要包括$conditions变量
- 还必须使用参数--split-by 列名, 即选择一个分隔列。
如果不是,这个query只被执行一次,使用参数-m 1
迁移过程使用1个map(开启一个线程)
$ sqoop import
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS'
-m 1 --target-dir /user/foo/joinresults
⚠️嵌套引号的写法: "SELECT * FROM x WHERE a='foo' AND $CONDITIONS"
关于Parallelims并行机制
You can specify the number of map tasks (parallel processes) to use to perform the import by using the -m or --num-mappers argument.
默认都是4个map task。
当你执行一个并行导入,Sqoop需要一个规则,来分割载入的工作workload。Sqoop使用一个被分割的列来分割这个workload。
默认,会使用一个表中的主键key列作为分割列。这个列的最小/大值是边界。
比如,一个表的主键是id,范围0~1000,Sqoop会被使用4个task, 运行4个进程。每个进程执行SQL语句:
SELECT * FROM sometable WHERE id >= lo AND id < hi
在不同的task中,(lo, hi) 被设置为 (0, 250), (250, 500), (500, 750), and (750, 1001)
使用参数--split-by,用于指定被分割的列名,这在缺少主键或又多重主键key时最有效。
7.29增量导入(Incremental imports)
Sqoop提供这周导入模式,用于之前已经导入,后来表的数据发生了改变的情况。无需全表重新导入,提高效率。
--check-column (col) |
Specifies the column to be examined when determining which rows to import. 指定被检查的列。 |
--incremental (mode) |
Specifies how Sqoop determines which rows are new. append and lastmodified.明确新的变化是来自新增row,还是原有row的数据变更了。 |
--last-value (value) |
Specifies the maximum value of the check column from the previous import. 明确之前导入的数据中,被检查的列的最后一个值。 |
用上面的3个参数:来明确检查方法。