简单地说,MapReduce就是"任务的分解与结果的汇总"。
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架。MapReduce采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
为什么需要 MapReduce?
◆ 海量数据在单机上处理因为硬件资源限制,无法胜任。
◆ 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度。
◆引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理。
MapReduce核心机制
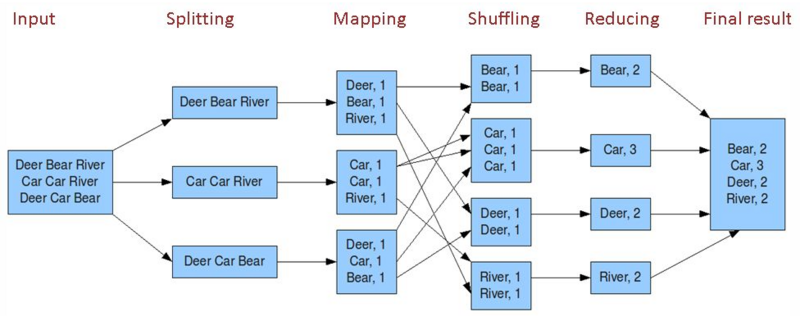
MapReduce核心就是map+shuffle+reducer,首先通过读取文件,进行分片,通过map获取文件的key-value映射关系,用作reducer的输入,在作为reducer输入之前,要先对map的key进行一个shuffle,也就是排个序,然后将排完序的key-value作为reducer的输入进行reduce操作,当然一个MapReduce任务可以不要有reduce,只用一个map。
更多MapReduce的文章阅读:《MapReduce设计及工作原理分析》