mysql视频练习题
2个表:
- order_info_utf.csv
- user_info_utf.csv
导入到mysql数据库。
题目:
1.统计不同月份下单的人数。
⚠️这里的人数是指共有多少名自然人下单,不是指“人次”。所以count()内加上distinct,去重复。
SELECT month(paidTime), count(distinct userId) FROM test1.orderinfo where isPaid = "已支付" group by month(paidTime);
+-----------------+------------------------+ | month(paidTime) | count(distinct userId) | +-----------------+------------------------+ | 3 | 54799 | | 4 | 43967 | | 5 | 6 | +-----------------+------------------------+ 3 rows in set (1.23 sec)
2.统计用户3月的回购率和复购率
2.1复购率:本月消费1次以上的人数/本月消费的总人数。
SELECT userid, count(userid) as ct FROM test1.orderinfo where isPaid = "已支付" and month(paidTime) = 3 group by userid having ct > 1;
得到一个列表:本月消费1次以上的人的id和他的消费次数的集合。
这里使用了having筛选出消费1次以上的人的id。
更好的方法是,查询结果显示2个列,分别储存“本月消费1次以上的人数”, “本月消费的总人数”:
所以,需要外面再加一层,并去掉having:
select count(if(ct > 1, 1, null)), count(1) from ( SELECT userid, count(userid) as ct FROM test1.orderinfo where isPaid = "已支付" and month(paidTime) = 3 group by userid) as t
得到2个数字16916和54799,所以复购率是:30.87%
2.2回购率:3月消费的人,又在4月进行了消费。这是一次回购:x。x除以3月消费的人数= 3月回购率。
3月消费的人数: 54799人
select count(1) from ( select userid from test1.orderinfo where isPaid = "已支付" and month(paidTime) = 3 group by userid) as user
3月消费的人,又在4月进行了消费的人数: 13119人
select count(1) from ( select userid from test1.orderinfo where isPaid = "已支付" and month(paidTime) = 3 group by userid) as user_3 inner join ( select userid from test1.orderinfo where isPaid = "已支付" and month(paidTime) = 4 group by userid) as user_4 on user_3.userid = user_4.userid;
因此最后: 13119/54799 =23.94%, 所以3月回购率是23.94%。
2.3计算所有月份的回购率
需要对2.2的代码进行修改。
select * from ( select userid, date_format(paidTime, "%Y-%m-01") as m, count(isPaid) from test1.orderinfo where isPaid = "已支付" group by userid, m)) as a left join ( select userid, date_format(paidTime, "%Y-%m-01") as m, count(isPaid) from test1.orderinfo where isPaid = "已支付" group by userid, m) as b on a.userid = b.userid

上面的代码把两个完全相同的表连接,解释:
1.子查询使用userid和date_format(paidTime, "%Y-%m-01")列进行分组。即得到的记录是用户在一个月内的消费次数。
2.使用date_format()函数,改变格式,把日设为01,以便进行后面的DATE_SUB(start_date,INTERVAL expr unit)计算。
然后,见完整代码:
3.⚠️使用的是左连接left join
4.因为使用左连接,所以可以这么增加一个筛选条件:and a.m = date_sub(b.m, interval 1 month)
- 即让a的月份=b的月份-1. 这样就可以把:每条记录按照同一用户在3月消费记录和4月消费记录连接起来,同样4月和5月,6月和7月等等,即相邻月份进行关联,以便计算回购率。
- 不符合条件的b表的value都是null表示。
5. 最后的外层表用a.m进行分组,然后使用聚合函数统计a表每个月的消费人数,以及b.表每个月的消费人数。因为通过条件合并了相邻月份。所以最后得到回购率的分母和分子。
select a.m, count(a.m),count(b.m) from ( select userid, date_format(paidTime, "%Y-%m-01") as m, count(isPaid) from test1.orderinfo where isPaid = "已支付" group by userid, m) as a left join ( select userid, date_format(paidTime, "%Y-%m-01") as m, count(isPaid) from test1.orderinfo where isPaid = "已支付" group by userid, m) as b on a.userid = b.userid and a.m = date_sub(b.m, interval 1 month) group by a.m
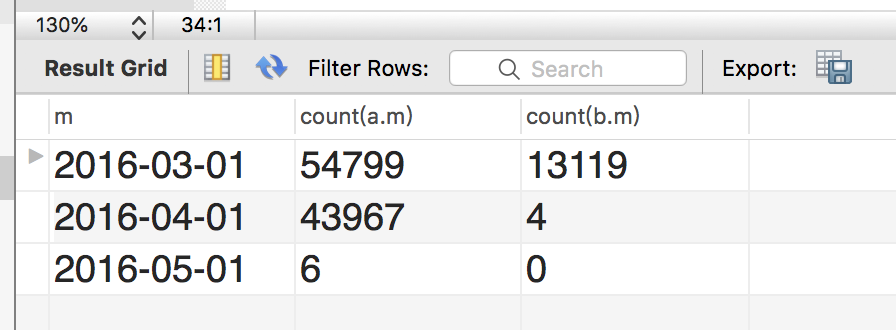
⚠️
6. 这里必须使用and,而不是where,
- 因为where是对left join ...on..后的数据再筛选,不符合条件的就被去掉了。
- 而and是在 on子句的内部,不符合条件的数据会用null表示。
and a.m = date_sub(b.m, interval 1 month)
3.统计男女的消费频次是否有差异
设所有男性消费者为x, 所有男性消费者的合计消费次数是x_order,那么男性消费频次为 x_order/x
select sex, avg(ct) from ( select o.userid, t.sex, count(1) as ct from orderinfo as o inner join ( SELECT * FROM test1.userinfo where sex <> "") t on o.userid = t.userid and o.ispaid = "已支付" group by o.userid, t.sex) t2 group by sex

4.统计多次消费的用户,第一次和最后一次消费间隔是多少
(相当于一个消费者的消费的周期)
首先,查询每个用户第一次消费和最后一次消费的时间,使用max, min函数:
SELECT userid, max(paidtime), min(paidtime) FROM test1.orderinfo where ispaid = "已支付" group by userid having count(1) > 1
然后,让max()减去min()但得到的是秒,所以需要使用datediff()函数,
SELECT userid,max(paidtime), min(paidtime), datediff(max(paidtime), min(paidtime)) as interval_day FROM test1.orderinfo where ispaid = "已支付" group by userid having count(1) > 1
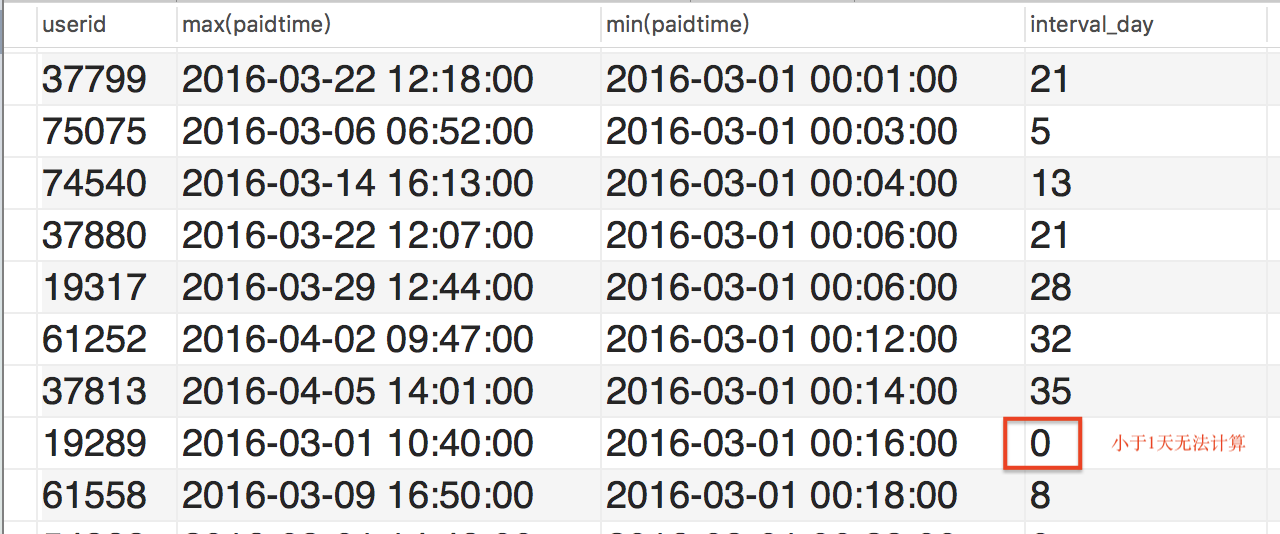
最后,再加上一层:
select avg(df) from ( SELECT userid,max(paidtime), min(paidtime), datediff(max(paidtime), min(paidtime)) as df FROM test1.orderinfo where ispaid = "已支付" group by userid having count(1) > 1) t
得到一个结果:15.6484天。
求平均值,这是不准确的简单计算。根据用户类型,个别高消费频次用户,应该属于统计中的极值,不当算在统计样本中。
或者改求中位数的值。
5统计不同年龄段,用户的消费金额是否有差异?(将消费金额定义为每个年龄段的人均消费金额和总金额。)
首先,得到一个每个用户所在年龄组的表t1
然后,使用orderinfo,得到每个用户的消费总额的表t2。
最后,把t1,t2内连接后,按照age_group分组,并使用聚合函数avg()计算每个年龄组的人均消费金额。
select t1.age_group, cast(avg(t2.price) as decimal(10,2)) as avg_price from (select userid, ceil((year(now())-year(birth))/10) as age_group from userinfo where birth > '1901-01-01') t1 #用'1901-01-01'去除一些脏数据 inner join ( SELECT userid, sum(price) as price FROM test1.orderinfo where isPaid = '已支付' group by userid) t2 on t1.userid = t2.userid group by t1.age_group order by age_group
更好的方法是使用case when:
select t1.age_group, cast(avg(t2.price) as decimal(10,2)) as avg_price from ( select userid, case when (year(now())-year(birth)) <=10 then "<=10 " when (year(now())-year(birth)) between 11 and 20 then "10 to 20" when (year(now())-year(birth)) between 21 and 30 then "20 to 30" when (year(now())-year(birth)) between 31 and 40 then "30 to 40" when (year(now())-year(birth)) between 41 and 50 then "40 to 50" when (year(now())-year(birth)) between 51 and 70 then "50 to 70" when (year(now())-year(birth)) >=71 then ">=71" end as age_group from userinfo where birth > '1901-01-01') t1 inner join ( SELECT userid, sum(price) as price FROM test1.orderinfo where isPaid = '已支付' group by userid) t2 on t1.userid = t2.userid group by t1.age_group order by t1.age_group
结果:
+-----------+-----------+ | age_group | avg_price | +-----------+-----------+ | 10 to 20 | 846.63 | | 20 to 30 | 1003.96 | | 30 to 40 | 1178.61 | | 40 to 50 | 1183.59 | | 50 to 70 | 1099.86 | | <=10 | 1322.29 | | >=71 | 3269.92 | +-----------+-----------+
6统计消费的2/8法则,消费的top20%的用户,贡献了多少额度
首先,计算出每个用户的消费额度@total, 和总共有多少消费用户。
然后,计算前20%的用户数量,使用limit得到这个用户范围的表格t
最后,对t计算消费总额@top20_price,这个数值除以@total,得到0.85。即前20%的用户,贡献了85%的额度。
select @count := count(userid), @total := sum(price) as total from ( SELECT userid, sum(price) as price FROM test1.orderinfo where isPaid = '已支付' group by userid order by price desc) t; #total 318503081.54, count = 85649 select @top20_percent := ceil(@count*0.2); #17130 select @top20_price :=sum(t.price) from ( SELECT userid, sum(price) as price FROM test1.orderinfo where isPaid = '已支付' group by userid order by price desc limit 17130) t # 272203711.45 select @top20_price/@total; #0.85
或者:
select @count := count(userid), @total := sum(price) as total from ( SELECT userid, sum(price) as price FROM test1.orderinfo where isPaid = '已支付' group by userid order by price desc) t; #total 318503081.54, count = 85649 -- select @top20_percent := ceil(@count*0.2); #17130 select sum(price)/@total from ( select row_number() over(order by price desc ) as rk, userid, price from ( SELECT userid, sum(price) as price FROM test1.orderinfo where isPaid = '已支付' group by userid order by price desc) as t1 ) as t2 where t2.rk < @top20_percent
这里使用row_numbe()计算函数,得到一个排名,然后用where子句得到前20%的用户的表t2,最后t2进行计算。