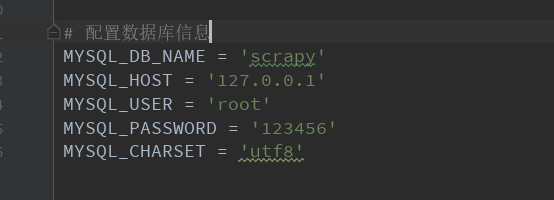
1.操作mysql
items.py

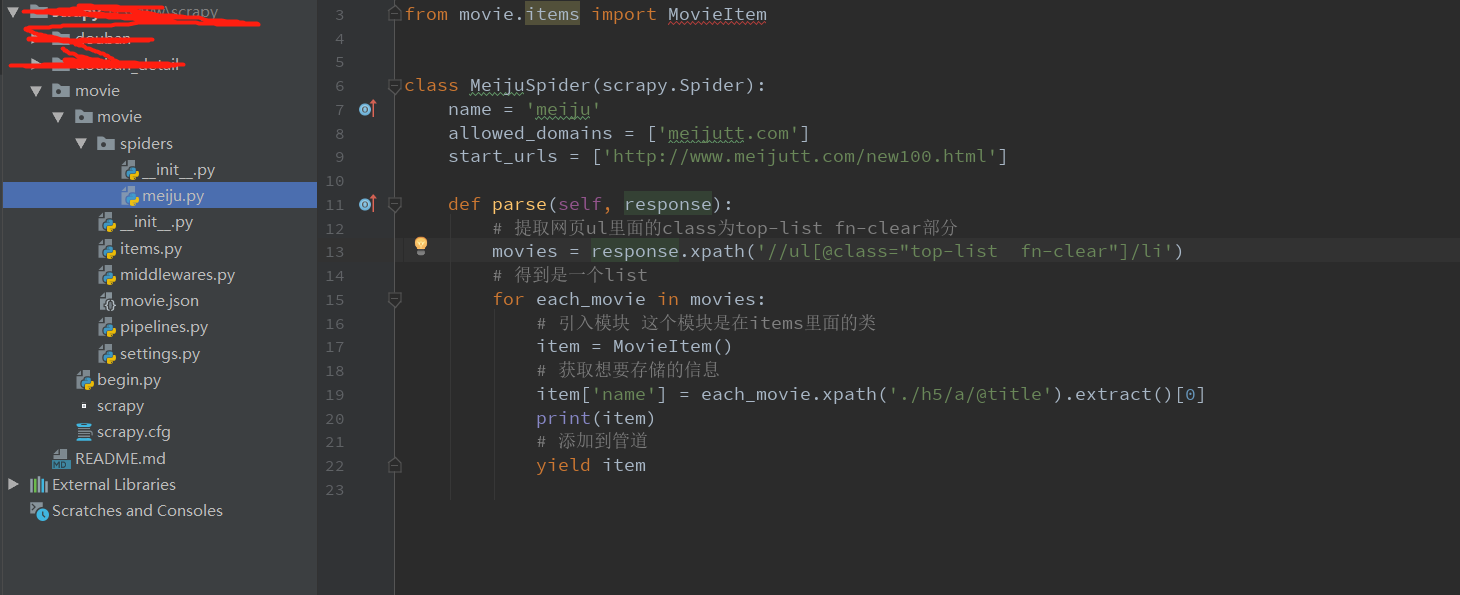
meiju.py
3.piplines.py

4.settings.py
--------------------------------------------------------------------------------------------------------------------------
批量下载图片。分类
网站:https://movie.douban.com/top250
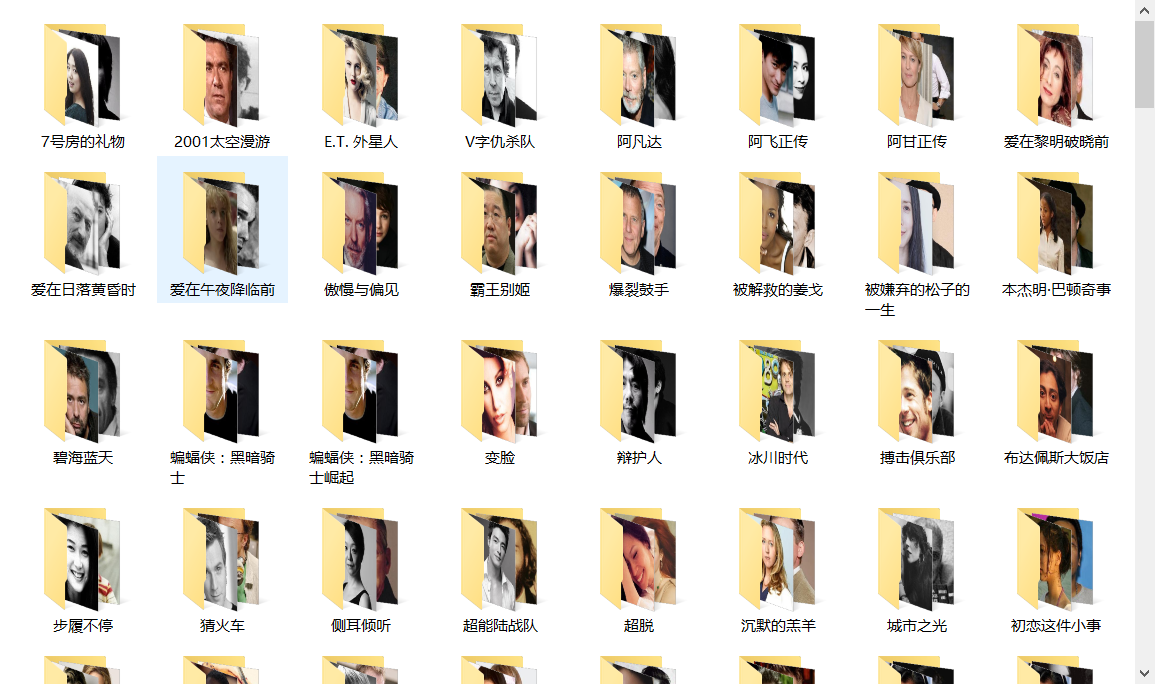
需求:按电影分类,获取里面的演职员图片。并存入各自的分类当中
效果:
代码
因为我们主要工作是下载。不存入数据库。存入数据库的话可以参考上面部分。
现在只需要修改spiders/xxx_spiders.py文件。就是开启项目适合生成的文件
我的是这个
以下是这个文件夹的代码。
# -*- coding: utf-8 -*- import scrapy import os import urllib.request import re class DoubanDetailSpidersSpider(scrapy.Spider): name = 'douban_detail_spiders' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/top250'] file_path = "D:\www\scrapy\douban_detail\image\" def parse(self, response): movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li") for i_item in movie_list: # 封面图 master_pic_path = i_item.xpath(".//div[@class='pic']//a//img/@src").extract_first() # 文件名 name = i_item.xpath(".//div[@class='info']//a/span[1]/text()").extract_first() # 创建文件夹 self.fileIsBeing(name) # 详情连接 detail_url = i_item.xpath(".//div[@class='hd']//a/@href").extract_first() # 获取详情里面内容 # detail_link = response.xpath(".//div[@class='hd']//a/@href").extract() # for link in detail_link:
# 这里是进入二级页面操作,在for循环里面。 yield scrapy.Request(detail_url, meta={'name': name}, callback=self.detail_parse, dont_filter=True) # 解析下一页 next_link = response.xpath("//div[@class='article']//div[@class='paginator']//span[@class='next']/link/@href").extract() print(next_link) if next_link: next_link = next_link[0] yield scrapy.Request("https://movie.douban.com/top250" + next_link, callback=self.parse) # 判断文件是否存在 # 不存在则创建 def fileIsBeing(self, name): path = self.file_path + name bool = os.path.exists(path) if not(bool): os.mkdir(path) return path # 解析详情里面的数据 获取二级页面内容操作。主要获取图片 def detail_parse(self, response): name = response.meta['name'] print(name) movie_prople_list = response.xpath("//div[@id='celebrities']//ul[@class='celebrities-list from-subject __oneline']//li") for i_mov_item in movie_prople_list: background_img = i_mov_item.xpath(".//div[@class='avatar']/@style").extract_first() user_name = i_mov_item.xpath(".//div[@class='info']//a/@title").extract_first() img_file_name = "%s.jpg" % user_name # 工作人员 img_url = self.txt_wrap_by('(', ')', background_img) # 图片地址 print(img_file_name) file_path = os.path.join(self.file_path+name, img_file_name) urllib.request.urlretrieve(img_url, file_path) # print(img_file_name) # 截取字符串中间部分 def txt_wrap_by(self, start_str, end, html): start = html.find(start_str) if start >= 0: start += len(start_str) end = html.find(end, start) if end >= 0: return html[start:end].strip()
码云:https://gitee.com/chenrunxuan/scrapy