Pika
pika是360奇虎公司开源的一款类redis存储系统,主要解决的是用户使用 Redis 的内存大小超过 50G、80G 等等这样的情况,会遇到启动恢复时间长,一主多从代价大,硬件成本贵,缓冲区容易写满等问题。
Pika 就是针对这些场景的一个解决方案:
- Pika 的单线程的性能肯定不如 Redis,Pika 是多线程的结构,因此在线程数比较多的情况下,某些数据结构的性能可以优于 Redis;
- Pika 肯定不是完全优于 Redis 的方案,只是在某些场景下面更适合,DBA 可以根据业务的场景挑选合适的方案。
Pika架构
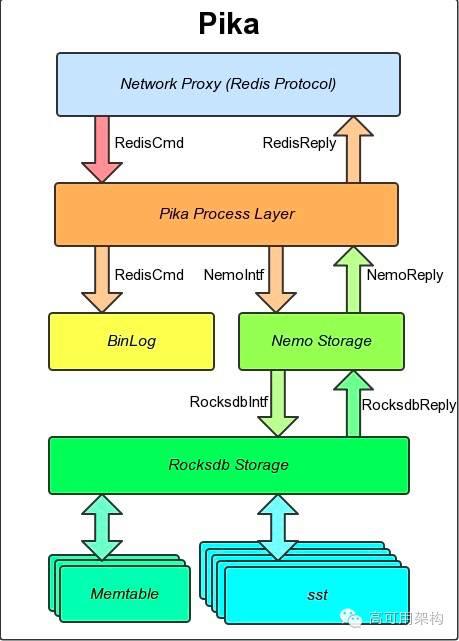
主要组成
- 网络模块 pink,对网络编程的封装,用户实现一个高性能的 server 只需要实现对应的 DealMessage 函数即可,支持单线程模型、多线程 worker 模型;
- 线程模块,见下文;
- 存储引擎 nemo,基于 Rocksdb 修改,封装 Hash, List, Set, Zset 等数据结构;
- 日志模块 binlog,解决了同步缓冲区太小的问题;
线程模块
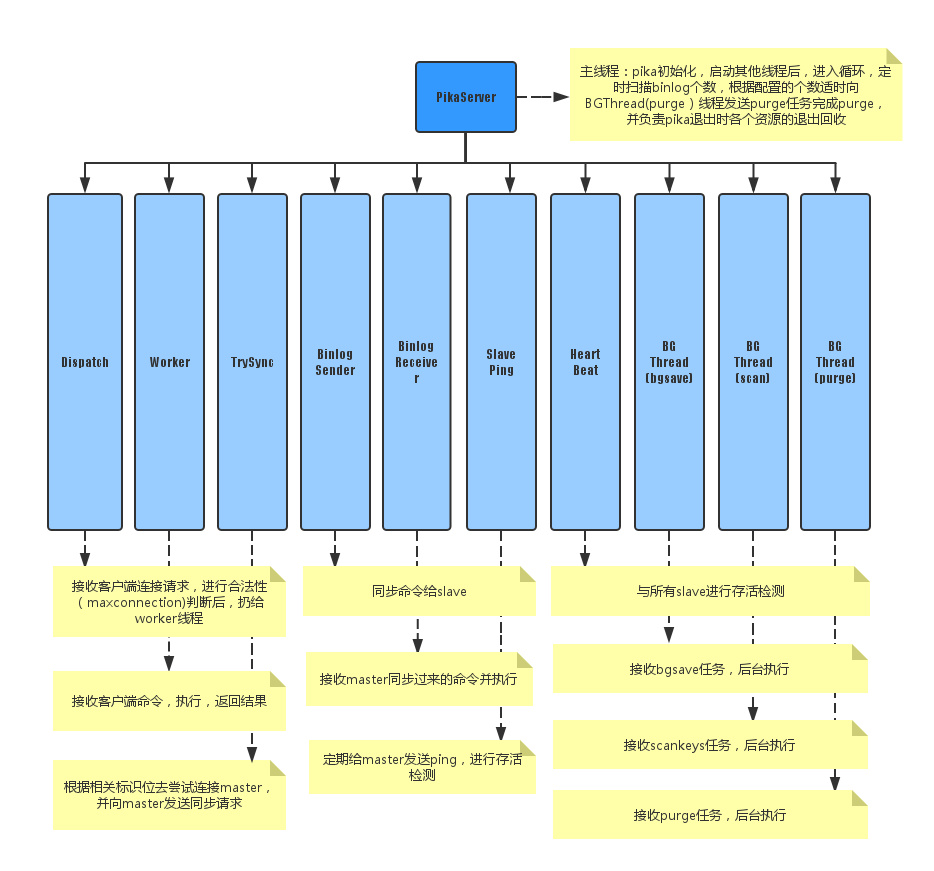
Pika 基于 pink 对线程进行封装,使用多个工作线程来进行读写操作,由底层 nemo 引擎来保证线程安全,线程分为 11 种:
- PikaServer:主线程
- DispatchThread:监听 1 个端口,接收用户连接请求
- ClientWorker:存在多个(用户配置),每个线程里有若干个用户客户端的连接,负责接收处理用户命令并返回结果,每个线程执行写命令后,追加到 binlog 中
- Trysync:尝试与 master 建立首次连接,并在以后出现故障后发起重连
- ReplicaSender:存在多个(动态创建销毁,本 master 节点挂多少个 slave 节点就有多少个),每个线程根据 slave 节点发来的同步偏移量,从 binlog 指定的偏移开始实时同步命令给 slave 节点
- ReplicaReceiver:存在 1 个(动态创建销毁,一个 slave 节点同时只能有一个 master),将用户指定或当前的偏移量发送给 master 节点并开始接收执行 master 实时发来的同步命令,在本地使用和 master 完全一致的偏移量来追加 binlog
- SlavePing:slave 用来向 master 发送心跳进行存活检测
- HeartBeat:master 用来接收所有 slave 发送来的心跳并恢复进行存活检测
- bgsave:后台 dump 线程
- scan:后台扫描 keyspace 线程
- purge:后台删除 binlog 线程
nemo存储引擎
nemo本质上是对rocksdb的改造和封装,使其支持多数据结构的存储(rocksdb只支持kv存储)。总的来说,nemo支持五种数据结构类型的存储:KV键值对、Hash结构、List结构、Set结构和ZSet结构。因为rocksdb的存储方式只有kv一种结构,所以以上所说的5种数据结构的存储最终都要落盘到rocksdb的kv存储方式上。
1、KV键值对
KV存储没有添加额外的元信息,只是在value的结尾加上8个字节的附加信息(前4个字节表示version,后 4个字节表示ttl)作为最后落盘kv的值部分。具体如下图:
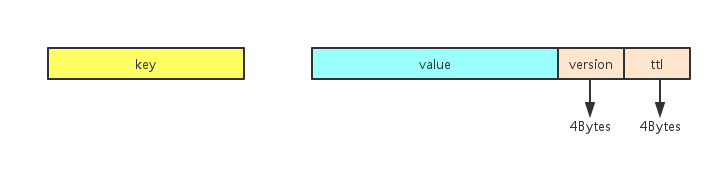
version字段用于对该键值对进行标记,以便后续的处理,如删除一个键值对时,可以在该version进行标记,后续再进行真正的删除,这样可以减少删除操作所导致的服务阻塞时间。
2、Hash结构
对于每一个Hash存储,它包括hash键(key),hash键下的域名(field)和存储的值 (value)。nemo的存储方式是将key和field组合成为一个新的key,将这个新生成的key与所要存储的value组成最终落盘的kv键值对。同时,对于每一个hash键,nemo还为它添加了一个存储元信息的落盘kv,它保存的是对应hash键下的所有域值对的个数。下面的是具体的实现方式:
每个hash键的元信息的落盘kv的存储格式:

前面的横条代表的存储每个hash键的落盘kv键值对的键部分,它有两字段组成:
- 第一个字段是一个’H’字符,表示这存储时hash键的元信息;
- 第二个字段是对应的hash键的字符串内容;
后面的横条代表的该元信息的值,它表示对应的hash键中的域值对(field-value)的数量,大小为8个字节(类型是int64_t)。
每个hash键、field、value到落盘kv的映射转换:

前面的横条对应落盘kv键值对的键部分:
- 第一个字段是一个字符’h’,表示的是hash结构的key;
- 第二个字段是hash键的字符串长度,用一个字节(uint8_t类型)来表示;
- 第三个字段是hash键的内容,因为第二个字段是一个字节,所以这里限定hash键的最大字符串长度是254个字节;
- 第四个字段是field的内容。
后面的横条代表的是落盘kv键值对的值部分,和KV结构存储一样,它是存入的value值加上8个字节的version字段和8个字节的ttl字段得到的。
3、List结构
每个List结构的底层存储也是采用链表结构来完成的。对于每个List键,它的每个元素都落盘为一个kv键值对,作为一个链表的一个节点,称为元素节点。和hash一样,每个List键也拥有自己的元信息。
每个元信息的落盘kv的存储格式
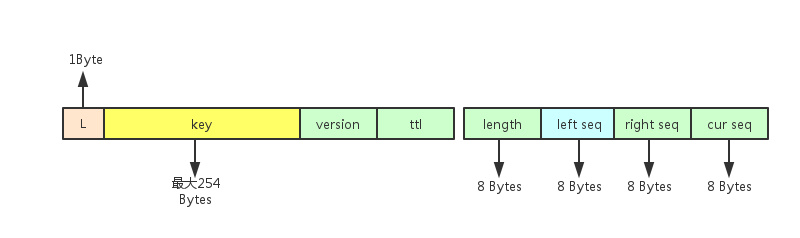
前面横条表示存储元信息的落盘kv的键部分,和前面的hash结构是类似的;
后面的横条表示存储List键的元信息,它有四个字段,从前到后分别为该List键内的元素个数、最左边的元素节点的sequence(相当于链表头)、最右边的元素节点的sequence(相当于链表尾)、下一个要插入元素节点所应该使用的sequence。
每个元素节点对应的落盘kv存储格式
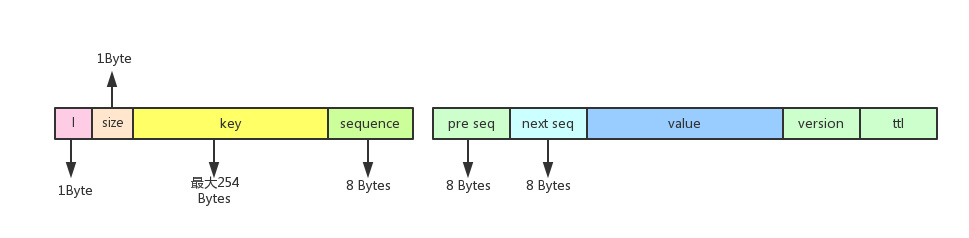
前面横条代表的是最终落盘kv结构的键部分,总共4个字段,前面三个字符段分别为一个字符’l’(表明是List结构的结存),List键的字符串长度(1个字节)、List键的字符串内容(最多254个字节),第四个字段是该元素节点所对应的索引值,用8个字节表示(int64_t类型),对于每个元素节点,这个索引(sequence)都是唯一的,是其他元素节点访问该元素节点的唯一媒介;往一个空的List键内添加一个元素节点时,该添加的元素节点的sequence为1,下次一次添加的元素节点的sequence为2,依次顺序递增,即使中间有元素被删除了,被删除的元素的sequence也不会被之后新插入的元素节点使用,这就保证了每个元素节点的sequence都是唯一的。
后面的横条代表的是具体落盘kv结构的值,它有5个字段,后面的三个字段分别为存入的value值、version、ttl,这和前面的hash结构存储是类似的;前两个字段分别表示的是前一个元素节点的sequence、和后一个元素节点的sequence、通过这两个sequence,就可以知道前一个元素节点和后一个元素节点的罗盘kv的键内容,从而实现了一个双向链表的结构。
4、Set结构
每个Set键的元信息对应的落盘kv存储格式
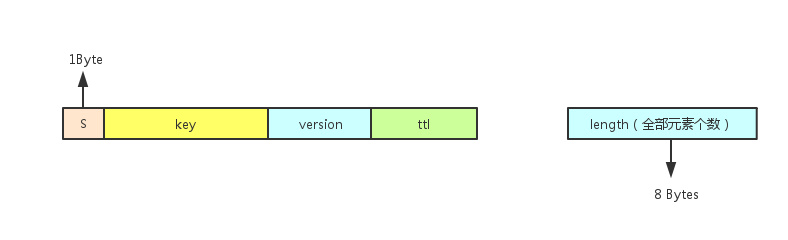
每个元素节点对应的落盘kv存储格式
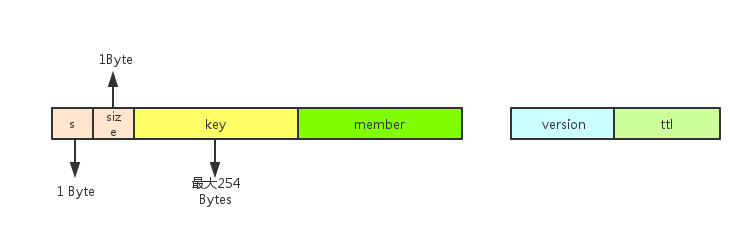
值的部分只有version和ttl,没有value字段。
5、ZSet结构
ZSet存储结构是一个有序Set,所以对于每个元素,增加了一个落盘kv,在这个增加的罗盘 kv的键部分,把该元素对应的score值整合进去,这样便于依据Score值进行排序(因为从rocksdb内拿出的数据时按键排序的),下面是落盘kv的存储形式。
存储元信息的落盘kv的存储格式
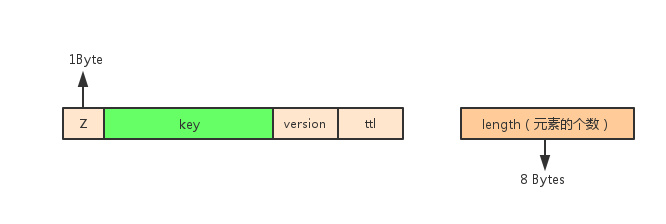
score值在value部分的落盘kv存储格式
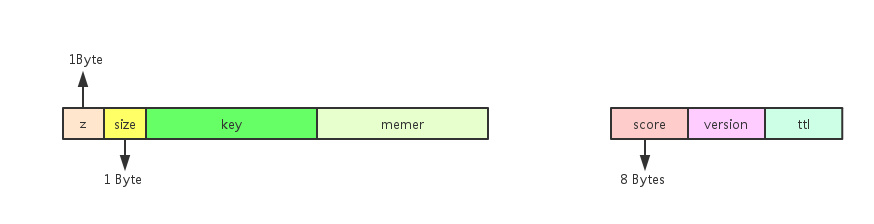
score值在key部分的落盘kv存储格式

score是从double类型转变过来的int64_t类型,这样做是为了可以让原来的浮点型的score直接参与到字符串的排序当中(浮点型的存储格式与字符串的比较方式不兼容)。
日志模块
Pika 的主从同步是使用 Binlog 来完成的:master 执行完一条写命令就将命令追加到 Binlog 中,ReplicaSender 将这条命令从 Binlog 中读出来发送给 slave,slave 的 ReplicaReceiver 收到该命令,执行,并追加到自己的 Binlog 中。
binlog 本质是顺序写文件,通过 Index + offset 进行同步点检查,支持全同步 + 增量同步;
当发生主从切换以后,slave 仅需要将自己当前的 Binlog Index + offset 发送给 master,master 找到后从该偏移量开始同步后续命令。
为了防止读文件中写错一个字节则导致整个文件不可用,所以Pika采用了类似 leveldb log 的格式来进行存储,具体如下:

主从同步
先说下slave的连接状态:
- No Connect,不尝试成为任何其他节点的slave;
- Connect,Slaveof后尝试成为某个节点的slave,发送trysnc命令和同步点;
- Connecting,收到master回复可以slaveof,尝试跟master建立心跳;
- Connected, 心跳建立成功;
- WaitSync,不断检测是否DBSync完成,完成后更新DB并发起新的slaveof;

全同步
Pika 支持 master/slave 的复制方式,通过 slave 端的 slaveof 命令激发:
- salve 端处理 slaveof 命令,将当前状态变为 slave,改变连接状态;
- slave的trysync线程向 master 发起 trysync,同时将要同步点传给 master;
- master处理trysync命令,发起对slave的同步过程,从同步点开始顺序发送 binlog 或进行全同步;
pika同步依赖于binlog,binlog 文件会自动或手动删除,当同步点对应的 binlog 文件不存在时,需要通过全同步进行数据同步。
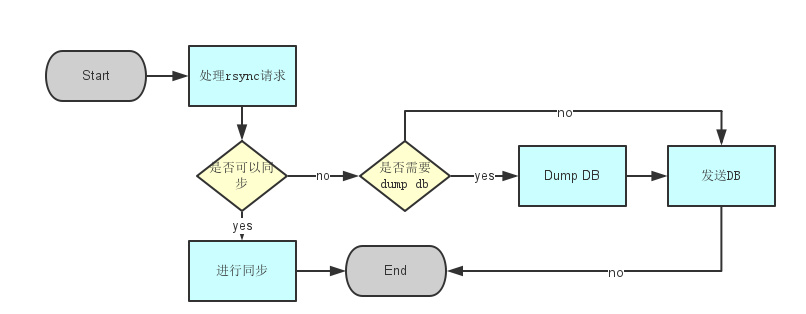
需要进行全同步时,master 会将 db 文件 dump 后发送给 slave(通过 rsync 的 deamon 模式实现 db 文件的传输),实现逻辑:
- slave 向 master 发送trysnc命令(此时需要开启rsync后台服务);
- master 发现需要全同步时,判断是否有备份文件可用,如果没有先 dump 一份;
- master 通过 rsync 向 slave 发送 dump 出的文件;
- slave 用收到的文件替换自己的 db;
- slave 用最新的偏移量再次发起 trysnc;
- 完成同步;
Slave 的流程:

Master 的流程:
增量同步
一主多从的结构master节点也可以给多个slave复用一个Binlog,只不过不同的slave在binglog中有自己的偏移量而已,master执行完一条写命令就将命令追加到Binlog中,ReplicaSender将这条命令从Binlog中读出来发送给slave,slave的ReplicaReceiver收到该命令,执行,并追加到自己的Binlog中。
主要模块:
- WorkerThread:接受和处理用户的命令;
- BinlogSenderThread:负责顺序地向对应的从节点发送在需要同步的命令;
- BinlogReceiverModule: 负责接受主节点发送过来的同步命令
- Binglog:用于顺序的记录需要同步的命令
主要的工作过程:
- 当WorkerThread接收到客户端的命令,按照执行顺序,添加到Binlog里;
- BinglogSenderThread判断它所负责的从节点在主节点的Binlog里是否有需要同步的命令,若有则发送给从节点;
- BinglogReceiverModule模块则做以下三件事情:
-
- 接收主节点的BinlogSenderThread发送过来的同步命令;
- 把接收到的命令应用到本地的数据上;
- 把接收到的命令添加到本地Binlog里 至此,一条命令从主节点到从节点的同步过程完成;
下图是BinLogReceiverModule(在源代码中没有这个对象,这里是为了说明方便,抽象出来的)的组成,从图中可以看出BinlogReceiverModule由一个BinlogReceiverThread和多个BinlogBGWorker组成。
- BinlogReceiverThread: 负责接受由主节点传送过来的命令,并分发给各个BinlogBGWorker,若当前的节点是只读状态(不能接受客户端的同步命令),则在这个阶段写Binlog
- BinlogBGWorker:负责执行同步命令;若该节点不是只读状态(还能接受客户端的同步命令),则在这个阶段写Binlog(在命令执行之前写)
BinlogReceiverThread接收到一个同步命令后,它会给这个命令赋予一个唯一的序列号(这个序列号是递增的),并把它分发给一个BinlogBGWorker;而各个BinlogBGWorker则会根据各个命令的所对应的序列号的顺序来执行各个命令,这样也就保证了命令执行的顺序和主节点执行的顺序一致了 之所以这么设计主要原因是:
- 配备多个BinlogBGWorker是可以提高主从同步的效率,减少主从同步的滞后延迟;
- 让BinlogBGWorker在执行执行之前写Binlog可以提高命令执行的并行度;
- 在当前节点是非只读状态,让BinglogReceiverThread来写Binlog,是为了让Binglog里保存的命令顺序和命令的执行顺序保持一致.
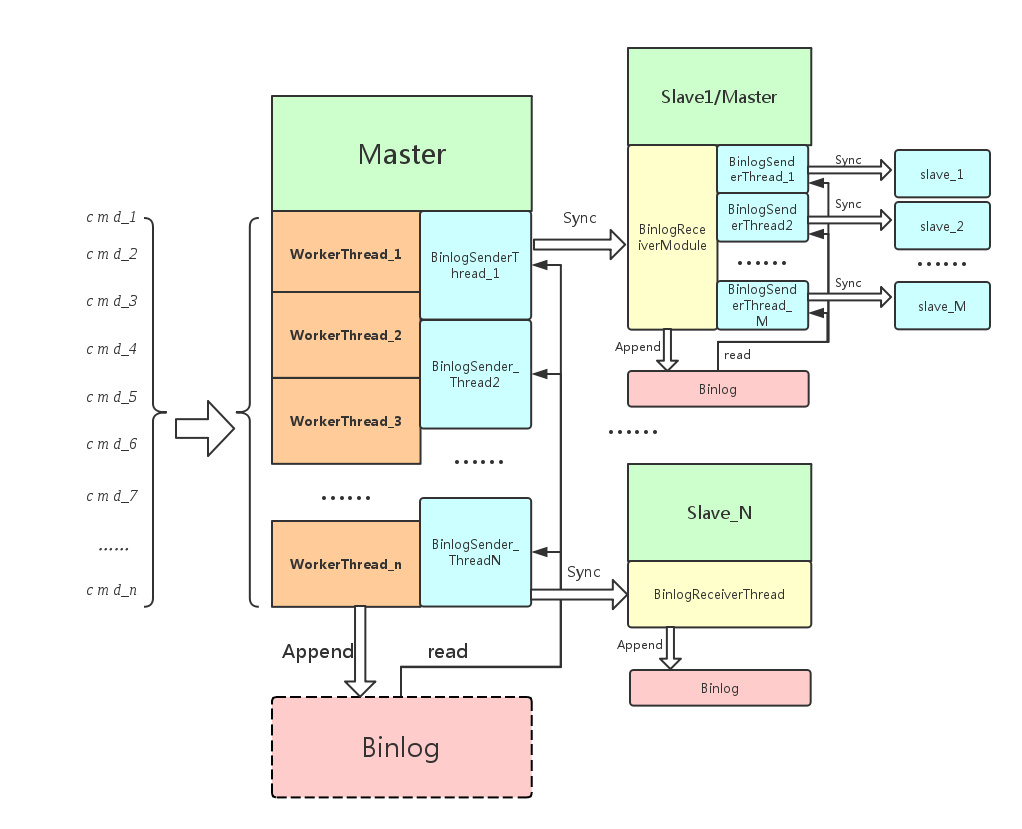
上图是一个主从同步的一个过程(即根据主节点数据库的操作日志,将主节点数据库的改变过程顺序的映射到从节点的数据库上),从图中可以看出,每一个从节点在主节点下都有一个唯一对应的BinlogSenderThread。 (为了说明方便,我们定一个“同步命令”的概念,即会改变数据库的命令,如set,hset,lpush等,而get,hget,lindex则不是)
快照式备份
不同于Redis,Pika的数据主要存储在磁盘中,这就使得其在做数据备份时有天然的优势,可以直接通过文件拷贝实现 实现

快照内容:
- 当前db的所有文件名
- manifest文件大小
- sequence_number
- 同步点
- binlog filenum
- offset
流程
- 打快照:阻写,并在这个过程中或的快照内容
- 异步线程拷贝文件:通过修改Rocksdb提供的BackupEngine拷贝快照中文件,这个过程中会阻止文件的删除
锁的应用
应用挂起指令,在挂起指令的执行中,会添加写锁,以确保,此时没有其他指令执行。其他的普通指令在会添加读锁,可以并行访问。其中挂起指令有:
- trysync
- bgsave
- flushall
- readonly
在pika系统中,对于数据库的操作都需要添加行锁,主要在应用于两个地方,在系统上层指令过程中和在数据引擎层面。在pika系统中,对于写指令(会改变数据状态,如SET,HSET)需要除了更新数据库状态,还涉及到pika的增量同步,需要在binlog中添加所执行的写指令,用于保证master和slave的数据库状态一致。故一条写指令的执行,主要有两个部分:
- 更改数据库状态
- 将指令添加到binlog中
其加锁情况,如下图:
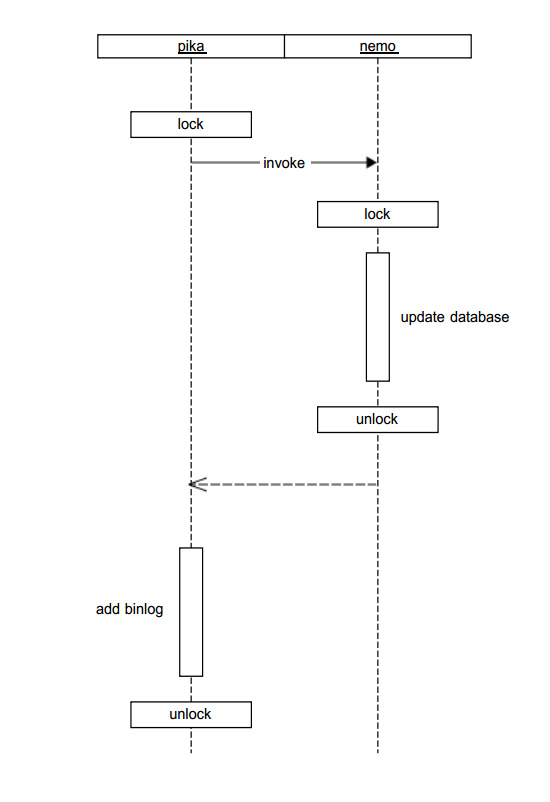
在图中可以看到,对同一个key,加了两次行锁,在实际应用中,pika上所加的锁就已经能够保证数据访问的正确性。如果只是为了pika所需要的业务,nemo层面使用行锁是多余的,但是nemo的设计初衷就是通过对rocksdb的改造和封装提供一套完整的类redis数据访问的解决方案,而不仅仅是为pika提供数据库引擎。这种设计思路也是秉承了Unix中的设计原则:Write programs that do one thing and do it well。
这样设计大大降低了pika与nemo之间的耦合,也使得nemo可以被单独拿出来测试和使用,在pika中的数据迁移工具就是完全使用nemo来完成,不必依赖任何pika相关的东西。另外对于nemo感兴趣或者有需求的团队也可以直接将nemo作为数据库引擎而不需要修改任何代码就能使用完整的数据访问功能。
参考文档:
http://toutiao.com/a6283628736621461761/
https://github.com/Qihoo360/pika/wiki