事务处理
让我们用最经典的 Use Case:“A帐号向B帐号汇钱”来说明一下,熟悉RDBMS事务的都知道从帐号A到帐号B需要6个操作:
- 从A帐号中把余额读出来;
- 对A帐号做减法操作;
- 把结果写回A帐号中;
- 从B帐号中把余额读出来;
- 对B帐号做加法操作;
- 把结果写回B帐号中;
为了数据的一致性,这6件事,要么都成功做完,要么都不成功,而且这个操作的过程中,对A、B帐号的其它访问必需锁死,所谓锁死就是要排除其它的读写操作,不然会有脏数据的问题,这就是事务。
如果A帐号和B帐号的数据不在同一台服务器上怎么办?我们需要一个跨机器的事务处理。也就是说,如果A的扣钱成功了,但B的加钱不成功,我们还要把A的操作给回滚回去。这在跨机器的情况下,就变得比较复杂了。
如果不考虑性能的话,保证事务并不困难,系统慢一点就行了;除了考虑性能外,我们还要考虑可用性,也就是说,一台机器没了,数据不丢失,服务可由别的机器继续提供。 于是,我们需要重点考虑下面的这么几个情况:
- 容灾:数据不丢、节点的Failover;
- 数据的一致性:事务处理;
- 性能:吞吐量 、 响应时间
要解决数据不丢,只能通过数据冗余的方法,就算是数据分区,每个区也需要进行数据冗余处理。这就是数据副本:当出现某个节点的数据丢失时可以从副本读到,数据副本是分布式系统解决数据丢失异常的唯一手段。所以在数据冗余情况下考虑数据的一致性和性能的问题:
1)要想让数据有高可用性,就得写多份数据。
2)写多份的问题会导致数据一致性的问题。
3)数据一致性的问题又会引发性能问题
这就是软件开发,按下了葫芦起了瓢。
数据一致性可以简单分为三类:
- 弱一致性(weak),当你写入一个新值后,读操作在数据副本上可能读出来,也可能读不出来。
- 强一致性(strong),新的数据一旦写入,在任意副本任意时刻都能读到新值。
- 最终一致性(eventually),当你写入一个新值后,有可能读不出来,但在某个时间窗口之后保证最终能读出来。
2PC协议
在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,引入一个作为协调者(coordinator)的组件来统一掌控所有节点(称作参与者)的操作结果,并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。

两阶段提交(two phase commit, 2PC)的算法如下:
第一阶段(vote):
- 协调者问所有的参与者,是否可以执行提交操作;
- 各个参与者开始事务执行的准备工作:如:为资源上锁,预留资源,写undo/redo log;
- 参与者响应协调者,如果事务的准备工作成功,则回应“可以提交”,否则回应“拒绝提交”;
第二阶段(commit):
- 如果所有的参与者都回应“可以提交”,那么,协调者向所有的参与者发送“正式提交”的命令。参与者完成正式提交,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个Global Transaction;
- 如果有一个参与者回应“拒绝提交”,那么,协调者向所有的参与者发送“回滚操作”,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个Global Transaction;
2PC实现了强一致性,其最大缺点就是它通过阻塞完成,会极大影响性能;另一个问题则在timeout上:
- 第一阶段中,如果参与者没有收到询问请求,或是参与者的回应没有到达协调者。那么,需要协调者做超时处理,一旦超时,可以当作失败,也可以重试。
- 第二阶段中,正式提交发出后,如果有的参与者没有收到,或是参与者提交/回滚后的确认信息没有返回,一旦参与者的回应超时,要么重试,要么把那个参与者标记为问题结点剔除整个集群,这样可以保证服务结点都是数据一致性的。
- 第二阶段中,如果参与者收不到协调者的commit/fallback指令,参与者将处于“状态未知”阶段,参与者完全不知道要怎么办,比如:如果所有的参与者完成第一阶段的回复后(可能全部yes,可能全部no,可能部分yes部分no),如果协调者在这个时候挂掉了。那么所有的结点完全不知道怎么办(问别的参与者都不行),这个状态会block整个事务,为此,引入了3PC的概念。
3PC协议
3PC是把二段提交的第一个段break成了两段:询问,然后再锁资源。最后真正提交。其核心理念是:在询问的时候并不锁定资源,除非所有人都同意了,才开始锁资源。

理论上来说,如果第一阶段所有的结点返回成功,那么有理由相信成功提交的概率很大。这样一来,可以降低参与者Cohorts的状态未知的概率。也就是说,一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了。这一点很重要。下面我们来看一下3PC的状态迁移图:(注意图中的虚线,那些F,T是Failuer或Timeout,其中的:状态含义是 q – Query,a – Abort,w – Wait,p – PreCommit,c – Commit)
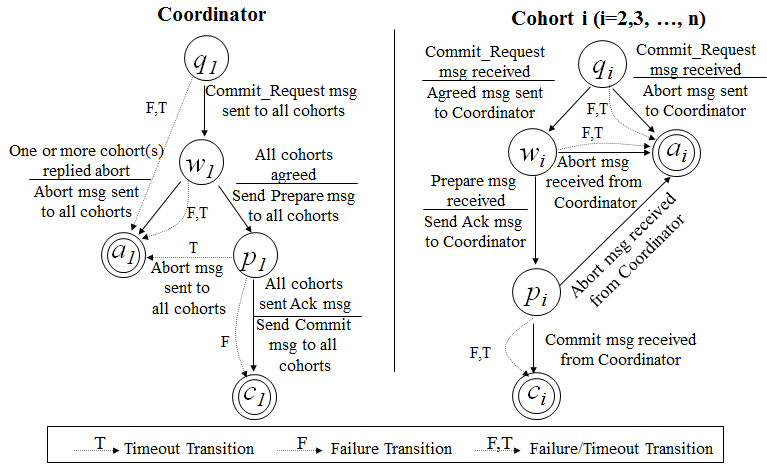
从上图的状态变化图我们可以从虚线(那些F,T是Failuer或Timeout)看到——如果结点处在P状态(PreCommit)的时候发生了F/T的问题,三段提交比两段提交的好处是,三段提交可以继续直接把状态变成C状态(Commit),而两段提交则不知所措。
paxos算法
Paxos是一种民主选举的算法,目的是让整个集群对某个值的变更达成一致,大多数节点的决定会成个整个集群的决定。任何一个点都可以提出要修改某个数据的提案,是否通过这个提案取决于这个集群中是否有超过半数的结点同意(需要集群中的节点是单数)。
这个算法有两个阶段(假设这个有三个结点:A,B,C):
第一阶段:Prepare阶段
A把申请修改的请求Prepare Request发给所有的结点A,B,C。注意,Paxos算法会有一个Sequence Number(提案号,这个数不断递增,而且是唯一的,也就是说A和B不可能有相同的提案号),这个提案号会和修改请求一同发出,任何结点在“Prepare阶段”时都会拒绝其值小于当前提案号的请求。所以,结点A在向所有结点申请修改请求的时候,需要带一个提案号,越新的提案,这个提案号就越是是最大的。
如果接收结点收到的提案号n大于其它结点发过来的提案号,这个结点会回应Yes(本结点上最新的被批准提案号),并保证不接收其它<n的提案。这样一来,结点上在Prepare阶段里总是会对最新的提案做承诺。
优化:在上述 prepare 过程中,如果任何一个结点发现存在一个更高编号的提案,则需要通知 提案人,提醒其中断这次提案。
第二阶段:Accept阶段
如果提案者A收到了超过半数的结点返回的Yes,然后他就会向所有的结点发布Accept Request(同样,需要带上提案号n),如果没有超过半数的话,那就返回失败。
当结点们收到了Accept Request后,如果对于接收的结点来说,n是最大的了,那么,它就会修改这个值,如果发现自己有一个更大的提案号,那么,结点就会拒绝修改。
我们可以看以,这似乎就是一个“两段提交”的优化。其实,2PC/3PC都是分布式一致性算法的残次版本,Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
CAP理论
- 一致性(Consistency),一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致;
- 可用性(Availability),可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间;
- 分区容错性(Partition tolerance),分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务;
CAP理论为:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
对于多数大型互联网应用的场景,主机众多、部署分散,而且现在的集群规模越来越大,所以节点故障、网络故障是常态,而且要保证服务可用性达到N个9,即保证P和A,舍弃C(退而求其次保证最终一致性)。虽然某些地方会影响客户体验,但没达到造成用户流程的严重程度。
但对于银行等金融机构,C必须保证。网络发生故障宁可停止服务,这是保证CA,舍弃P。
ACID理论
数据库事务(Transaction)是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。
一方面,当多个应用程序并发访问数据库时,事务可以在应用程序间提供一个隔离方法,防止互相干扰。另一方面,事务为数据库操作序列提供了一个从失败恢复正常的方法。
事物有下面4个特性:
- 原子性(Atomicity),事务的原子性是指事务中的操作不可拆分,只允许全部执行或者全部不执行;
- 一致性(Consistency),事务的一致性是指事务的执行不能破坏数据库的一致性,一致性也称为完整性。一个事务在执行后,数据库必须从一个一致性状态转变为另一个一致性状态;
- 隔离型(Isolation),事务的隔离型是指并发的事务相互隔离,不能互相干扰;
- 持久性(Durability),事务的持久性是指事务一旦提交,对数据的状态变更应该被永久保存;
实际工作中事务几乎都是并发的,完全做到互相之间不干扰会严重牺牲性能,为了平衡隔离型和性能,SQL92规范定义了四个事务隔离级别:
- 读未提交(Read Uncommitted),另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据(脏读)。脏读是指另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据。
- 读已提交(Read Committed),本事务读取到的是最新的数据(其他事务提交后的)。问题是,在同一个事务里,前后两次相同的SELECT会读到不同的结果(不可重复读)。不可重复读是指同一个事务执行过程中,另外一个事务提交了新数据,因此本事务先后两次读到的数据结果会不一致。
- 可重复读(Repeatable Read),在同一个事务里,SELECT的结果是事务开始时间点的状态,同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象。不可重复读保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。但是,如果另一个事务同时提交了新数据,本事务再更新时,就会发现了这些新数据,貌似之前读到的数据是幻觉,这就是幻读。
- 串行化(Serializable),所有事务只能一个接一个串行执行,不能并发。
事务隔离级别越高,越能保证数据的一致性,但对并发性能影响越大,一致性和高性能必须有所取舍或折中。
一般情况下,多数应用程序可以选择将数据库的隔离级别设置为读已提交,这样可以避免脏读,也可以得到不错的并发性能。尽管这个隔离级别会导致不可重复度、幻读,但这种个别场合应用程序可以通过主动加锁进行并发控制。
BASE理论
BASE理论是对CAP理论的延伸,核心思想是即使无法做到强一致性(Strong Consistency,CAP的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性(Eventual Consitency)。
- 基本可用(Basically Available),基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用;
- 软状态( Soft State),软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现;
- 最终一致性( Eventual Consistency),最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
BASE支持的是大型分布式系统,提出通过牺牲强一致性获得高可用性。