HTTP/2 协议
HTTP/2是由google的SPDY协议衍生而来的。
HTTP/2 没有改动 HTTP 的应用语义。 HTTP 方法、状态代码、URI 和标头字段等核心概念一如往常。 不过,HTTP/2 修改了数据格式化(分帧)以及在客户端与服务器间传输的方式。这两点统帅全局,通过新的分帧层向我们的应用隐藏了所有复杂性。 因此,所有现有的应用都可以不必修改而在新协议下运行。
二进制分帧
HTTP/2 采用二进制格式传输数据,而非 HTTP/1.x 的文本格式。 HTTP/2 中,同域名下所有通信都在单个连接上完成,该连接可以承载任意数量的双向数据流。连接数量减少对提升 HTTPS 部署的性能来说是一项特别重要的功能:可以减少开销较大的 TLS 连接数、提升会话重用率,以及从整体上减少所需的客户端和服务器资源。
每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。多个帧之间可以乱序发送,根据帧首部的流标识可以重新组装。
HTTP/2 仍是对之前 HTTP 标准的扩展,而非替代。 HTTP 的应用语义不变,提供的功能不变,HTTP 方法、状态代码、URI 和标头字段等这些核心概念也不变。
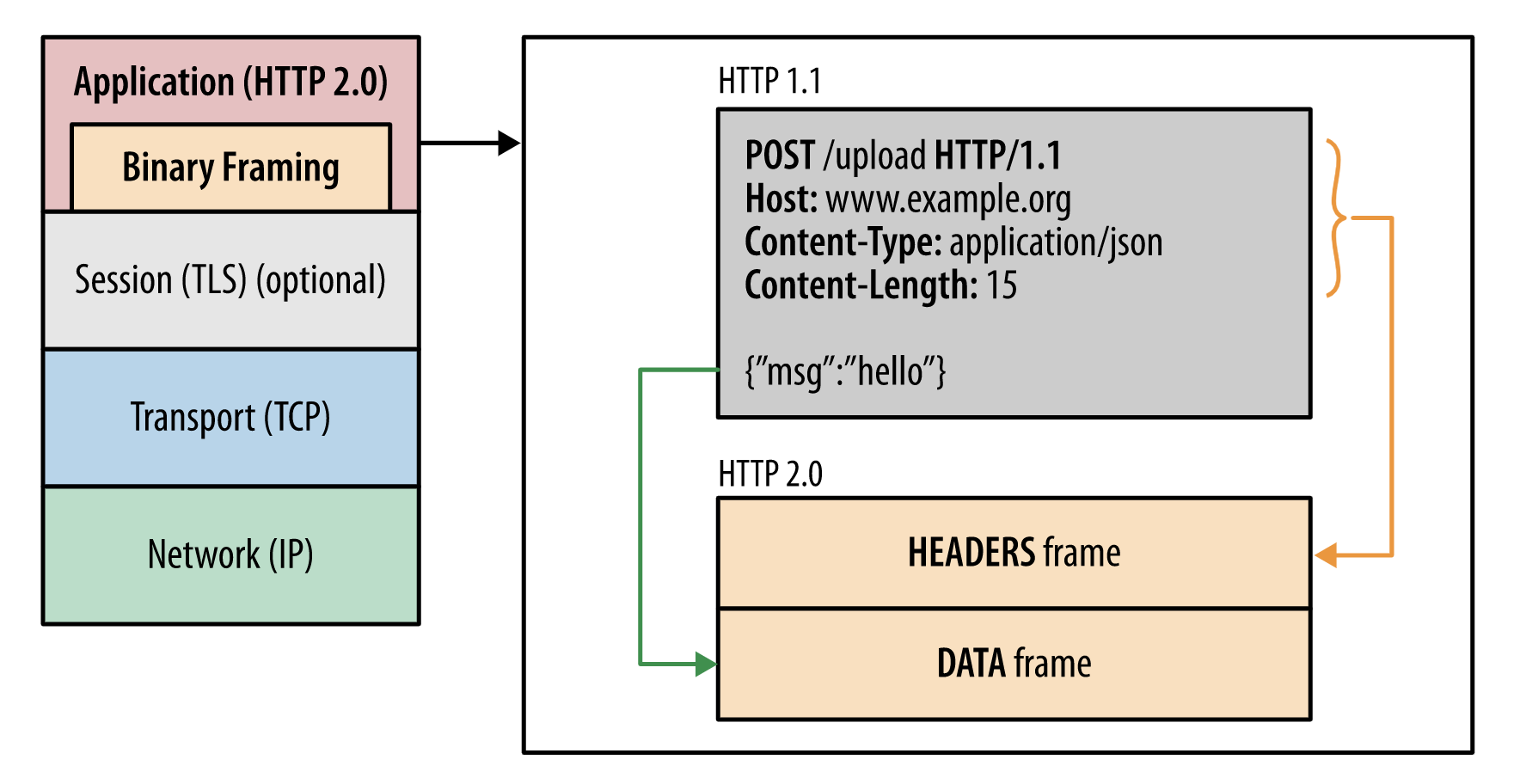
这里所谓的“层”,指的是位于套接字接口与应用可见的高级 HTTP API 之间一个经过优化的新编码机制:HTTP 的语义(包括各种动词、方法、标头)都不受影响,不同的是传输期间对它们的编码方式变了。 HTTP/1.x 协议以换行符作为纯文本的分隔符,而 HTTP/2 将所有传输的信息分割为更小的消息和帧,并采用二进制格式对它们编码。
新的二进制分帧机制改变了客户端与服务器之间交换数据的方式。 为了说明这个过程,我们需要了解 HTTP/2 的三个概念:
- 数据流 (stream):已建立的连接内的双向字节流,可以承载一条或多条消息。
- 消息 (message):与逻辑请求或响应消息对应的完整的一系列帧。
- 帧 (frame):HTTP/2 通信的最小单位,每个帧都包含帧头,至少也会标识出当前帧所属的数据流。
这些概念的关系总结如下:
- 所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流。
- 每条stream都有一个唯一的标识符和可选的优先级信息,用于承载双向消息。
- 每个message都是一条逻辑 HTTP 消息(例如请求或响应),包含一个或多个帧。
- frame是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载等等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
简言之,HTTP/2 将 HTTP 协议通信分解为二进制编码帧的交换,这些帧对应着特定数据流中的消息。所有这些都在一个 TCP 连接内复用。
http2.0的frame格式与http1.x的消息对比:

- length定义了整个frame的开始到结束,
- type定义frame的类型(一共10种);
- flags用bit位定义一些重要的参数;
- stream id用作流控制,一个request对应一个stream并分配一个id,这样一个连接上可以有多个stream,每个stream的frame可以随机的混杂在一起,接收方可以根据stream id将frame再归属到各自不同的request里面;
- payload就是request的正文了;
多路复用
连接无法复用
- 基于TCP的长连接,现在很多移动端app(不止是IM类应用)都会自己建立一条自己的长连接通道(基于TCP),使信息的上报和推送可以变得更及时;
- http long polling,可以参考https://www.cnblogs.com/chenny7/p/3954396.html;
- websocket协议,提供双向数据传输通道;
- http chunked传输编码,通过在response header增加"Transfer Encoding: chunked" 来告诉客户端后续还会有新的数据到来。但这个方式无法按照请求来做分割,客户端收到的每块数据都需要自己做协议解析;
head-of-line blocking(线头阻塞)
会导致带宽无法被充分利用,以及后续健康请求被阻塞。假设有5个请求同时发出,如下图
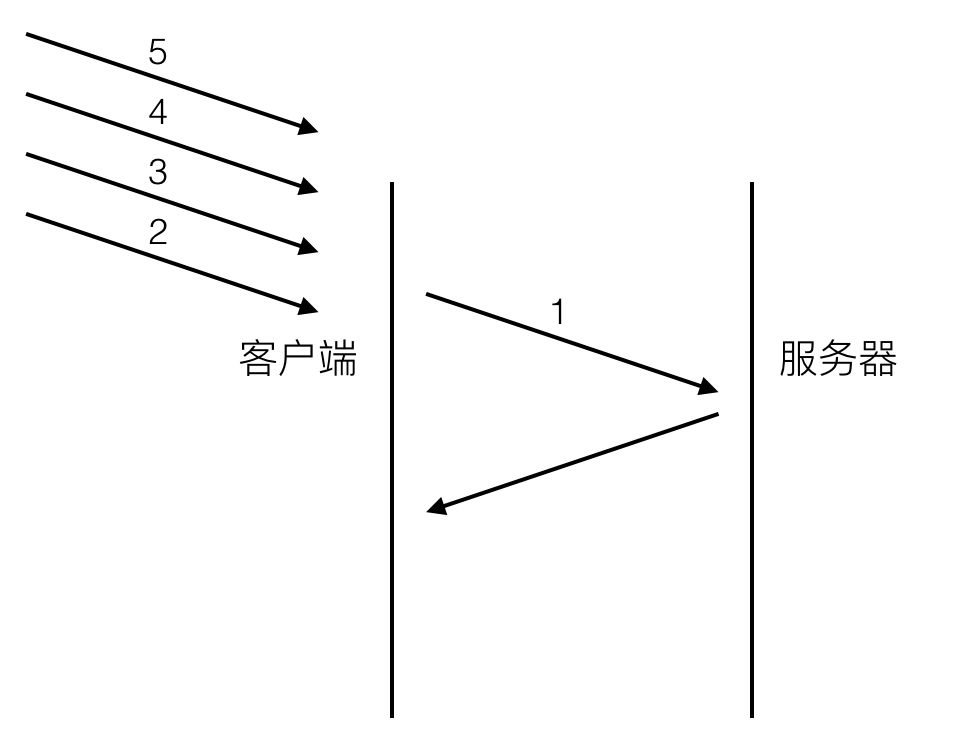
对于http1.0的实现,在第一个请求没有收到回复之前,后续从应用层发出的请求只能排队,请求2,3,4,5只能等请求1的response回来之后才能逐个发出。
在http1.1中,引入了pipeline来解决head of line blocking,如下图
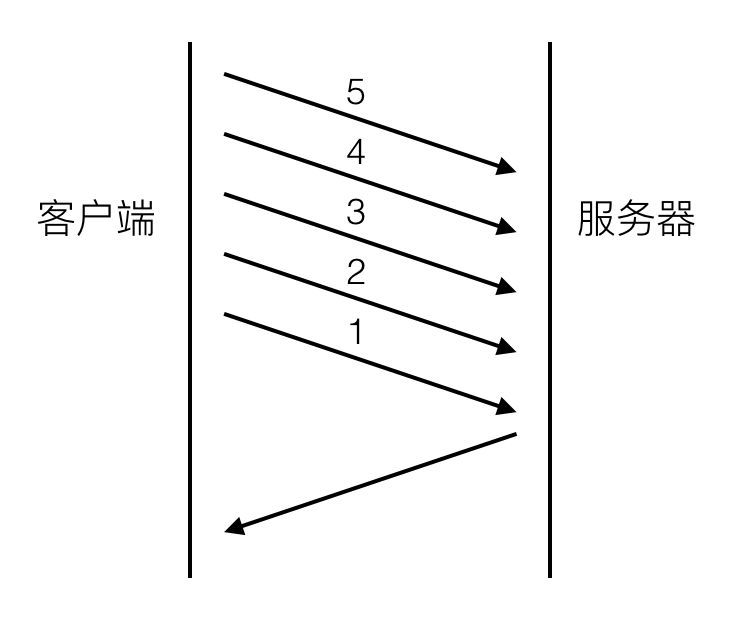
请求2,3,4,5不用等请求1的response返回之后才发出,而是几乎在同一时间把request发向了服务器。
下图可以看到pipeline机制对延迟的改变效果:
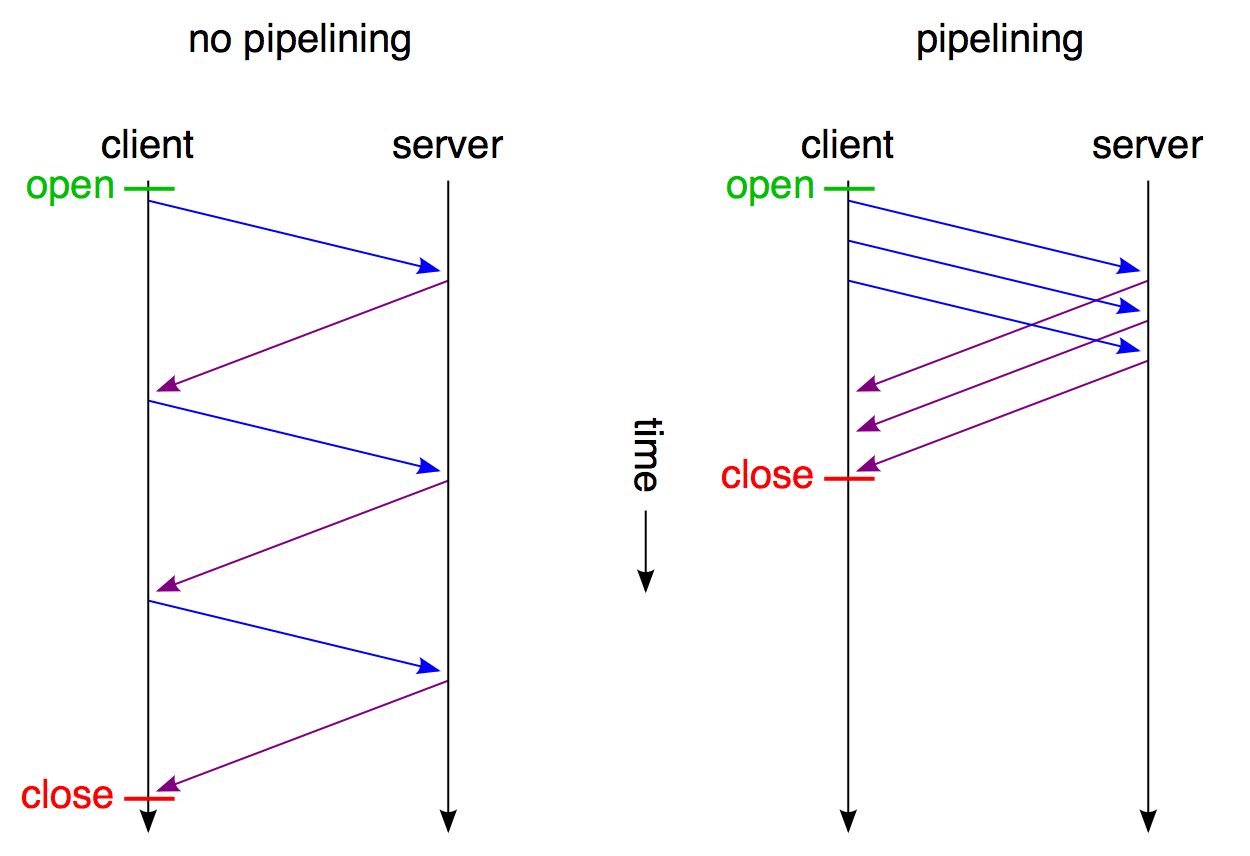
pipeline提高了性能,但head of line blocking并没有完全得到解决,server的response还是要求依次返回,遵循FIFO(first in first out)原则。也就是说如果请求1的response没有回来,2,3,4,5的response也不会被送回来。
HTTP2 Multiplexing
直白的说就是所有的请求都是通过一个 TCP 连接并发完成。HTTP/1.x 虽然通过 pipeline 也能并发请求,但是多个请求之间的响应会被阻塞的,所以 pipeline 至今也没有被普及应用,而 HTTP/2 做到了真正的并发请求。同时,流还支持优先级和流量控制。当流并发时,就会涉及到流的优先级和依赖。优先级高的流会被优先发送。
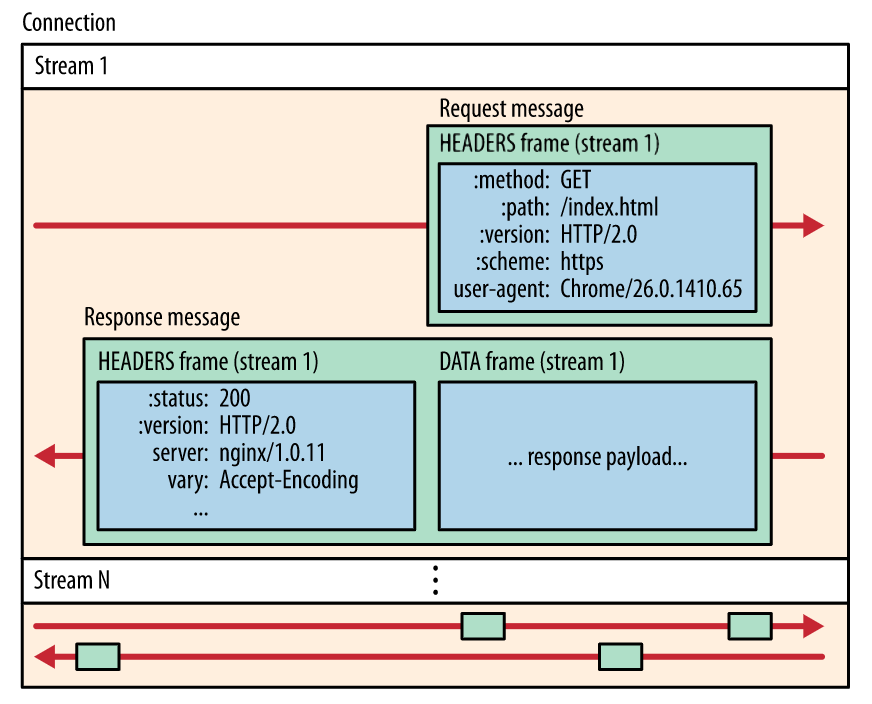
下图快照捕捉了同一个连接内并行的多个数据流。 客户端正在向服务器传输一个 DATA 帧(数据流 5),与此同时,服务器正向客户端交错发送数据流 1 和数据流 3 的一系列帧。因此,一个连接上同时有三个并行数据流。
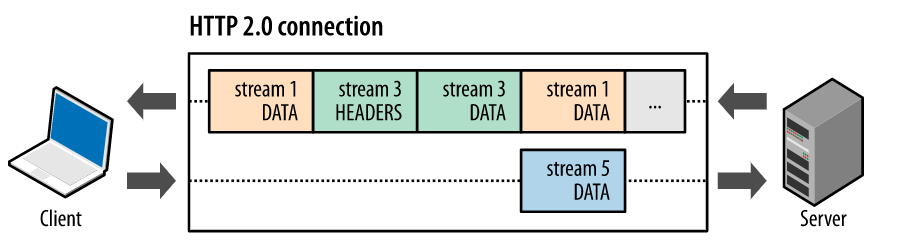
将 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装是 HTTP 2 最重要的一项增强:
- 并行交错地发送多个请求,请求之间互不影响。
- 并行交错地发送多个响应,响应之间互不干扰。
- 使用一个连接并行发送多个请求和响应。
- 不必再为绕过 HTTP/1.x 限制而做很多工作(例如级联文件、image sprites和域名分片)
- 消除不必要的延迟和提高现有网络容量的利用率,从而减少页面加载时间。
HTTP/2 中的新二进制分帧层解决了 HTTP/1.x 中存在的队首阻塞问题,也消除了并行处理和发送请求及响应时对多个连接的依赖。
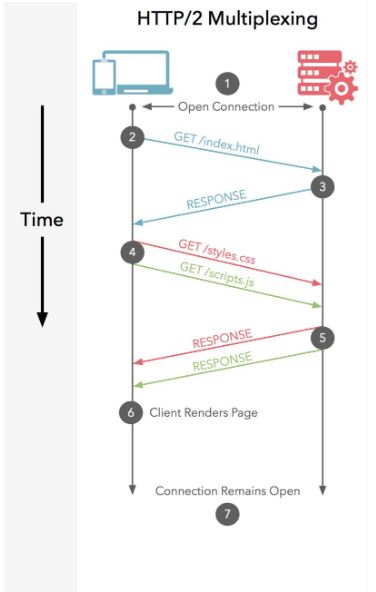
stream priority
将 HTTP 消息分解为很多独立的帧之后,我们就可以复用多个数据流中的帧,客户端和服务器交错发送和传输这些帧的顺序就成为关键的性能决定因素。 为了做到这一点,HTTP/2 标准允许每个数据流都有一个关联的权重和依赖关系:
- 可以向每个数据流分配一个介于 1 至 256 之间的整数。
- 每个数据流与其他数据流之间可以存在显式依赖关系,数据流依赖关系通过将另一个数据流的唯一标识符作为父项引用进行声明;如果忽略标识符,相应数据流将依赖于“根数据流”。
数据流依赖关系和权重的组合让客户端可以构建和传递“优先级树”,表明它倾向于如何接收响应。 反过来,服务器可以使用此信息通过控制 CPU、内存和其他资源的分配设定数据流处理的优先级,在资源数据可用之后,带宽分配可以确保将高优先级响应以最优方式传输至客户端。
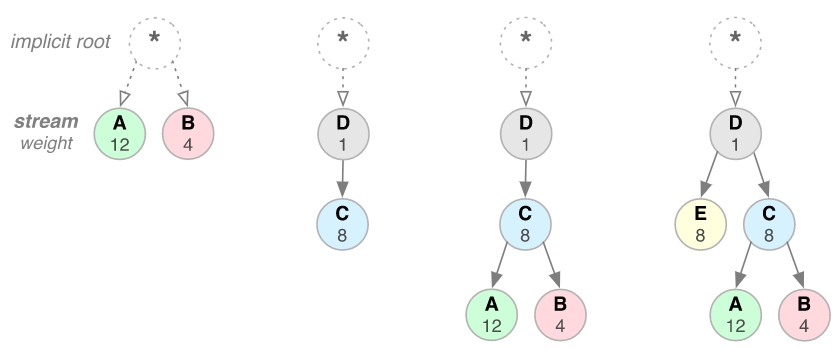
数据流依赖关系和权重的组合明确表达了资源优先级:
- 应尽可能先向父数据流分配资源,然后再向其依赖项分配资源;
- 共享相同父项的数据流(即,同级数据流)应按其权重比例分配资源。
我们来看一下上图中的其他几个操作示例。 从左到右依次为:
- 数据流 A 和数据流 B 都没有指定父依赖项,依赖于显式“根数据流”;A 的权重为 12,B 的权重为 4。因此,根据比例权重:数据流 B 获得的资源是 A 所获资源的三分之一。
- 数据流 D 依赖于根数据流;C 依赖于 D。 因此,D 应先于 C 获得完整资源分配。 权重不重要,因为 C 的依赖关系拥有更高的优先级。
- 数据流 D 应先于 C 获得完整资源分配;C 应先于 A 和 B 获得完整资源分配;数据流 B 获得的资源是 A 所获资源的三分之一。
- 数据流 D 应先于 E 和 C 获得完整资源分配;E 和 C 应先于 A 和 B 获得相同的资源分配;A 和 B 应基于其权重获得比例分配。
注:数据流依赖关系和权重表示传输优先级,而不是要求,因此不能保证特定的处理或传输顺序。 即,客户端无法强制服务器通过数据流优先级以特定顺序处理数据流。 尽管这看起来违反直觉,但却是一种必要行为。 我们不希望在优先级较高的资源受到阻止时,还阻止服务器处理优先级较低的资源。
flow control
流控制是一种阻止发送方向接收方发送大量数据的机制,以免超出后者的需求或处理能力。 例如,客户端可能请求了一个具有较高优先级的大型视频流,但是用户已经暂停视频,客户端现在希望暂停或限制从服务器的传输,以免提取和缓冲不必要的数据。
- 流控制具有方向性。 每个接收方都可以根据自身需要选择为每个数据流和整个连接设置任意的窗口大小。
- 流控制基于信用。 每个接收方都可以公布其初始连接和数据流流控制窗口(以字节为单位),每当发送方发出
DATA帧时都会减小,在接收方发出WINDOW_UPDATE帧时增大。 - 流控制无法停用。 建立 HTTP/2 连接后,客户端将与服务器交换
SETTINGS帧,这会在两个方向上设置流控制窗口。 流控制窗口的默认值设为 65,535 字节,但是接收方可以设置一个较大的最大窗口大小(2^31-1字节),并在接收到任意数据时通过发送WINDOW_UPDATE帧来维持这一大小。 - 流控制为逐跃点控制,而非端到端控制。 即,可信中介可以使用它来控制资源使用,以及基于自身条件和启发式算法实现资源分配机制。
Server Push
服务端能够更快的把资源推送给客户端。例如服务端可以主动把 JS 和 CSS 文件推送给客户端,而不需要客户端解析 HTML 再发送这些请求。当客户端需要的时候,它已经在客户端了。

HTTP/2 打破了严格的请求-响应语义,支持一对多和服务器发起的推送工作流。
所有服务器推送数据流都由 PUSH_PROMISE 帧发起,表明了服务器向客户端推送所述资源的意图,并且需要先于请求推送资源的响应数据传输。 这种传输顺序非常重要:客户端需要了解服务器打算推送哪些资源,以免为这些资源创建重复请求。 满足此要求的最简单策略是先于父响应(即,DATA 帧)发送所有 PUSH_PROMISE 帧,其中包含所承诺资源的 HTTP 标头。
假设服务端接收到客户端对 HTML 文件的请求,决定用 server push 推送一个css文件。那么,服务端会构造一个请求,包括请求方法和请求头,填充到一个 PUSH_PROMISE 帧里发送给客户端,来告知客户端它已经代劳发了这个请求。当客户端收到这个 PUSH_PROMISE 帧的时候,它就知道服务端将要推送一个CSS文件回来。如果此时客户端需要请求这个文件,即便服务端还没推完,它也不会往服务端发送对CSS文件的请求。在这个例子中,必须先发送 PUSH_PROMISE,再发送 HTML 的内容。这是因为 HTML 中存在对CSS的引用,一旦客户端发现了这个引用却还没收到 PUSH_PROMISE,它就会发起获取CSS文件请求。
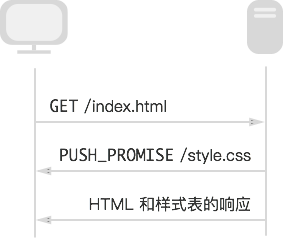
在客户端接收到 PUSH_PROMISE 帧后,它可以根据自身情况选择拒绝数据流(通过 RST_STREAM 帧)。 (例如,如果资源已经位于缓存中,便可能会发生这种情况。) 这是一个相对于 HTTP/1.x 的重要提升。 相比之下,使用资源内联(一种受欢迎的 HTTP/1.x“优化”)等同于“强制推送”:客户端无法选择拒绝、取消或单独处理内联的资源。
使用 HTTP/2,客户端仍然完全掌控服务器推送的使用方式。 客户端可以限制并行推送的数据流数量;调整初始的流控制窗口以控制在数据流首次打开时推送的数据量;或完全停用服务器推送。 这些优先级在 HTTP/2 连接开始时通过 SETTINGS 帧传输,可能随时更新。
推送的每个资源都是一个数据流,与内嵌资源不同,客户端可以对推送的资源逐一复用、设定优先级和处理。 浏览器强制执行的唯一安全限制是,推送的资源必须符合原点相同这一政策:服务器对所提供内容必须具有权威性。
HPACK头部压缩
在 HTTP/1.x 中,此元数据始终以纯文本形式,通常会给每个传输增加 500–800 字节的开销。如果使用 HTTP Cookie,增加的开销有时会达到上千字节。
为了减少此开销和提升性能,HTTP/2 使用 HPACK 压缩格式压缩请求和响应标头元数据,这种格式采用两种简单但是强大的技术:
- 这种格式支持通过静态霍夫曼代码对传输的标头字段进行编码,从而减小了各个传输的大小。
- 这种格式要求客户端和服务器同时维护和更新一个包含之前见过的标头字段的索引列表(换句话说,它可以建立一个共享的压缩上下文),此列表随后会用作参考,对之前传输的值进行有效编码。
利用霍夫曼编码,可以在传输时对各个值进行压缩,而利用之前传输值的索引列表,我们可以通过传输索引值的方式对重复值进行编码,索引值可用于有效查询和重构完整的标头键值对。
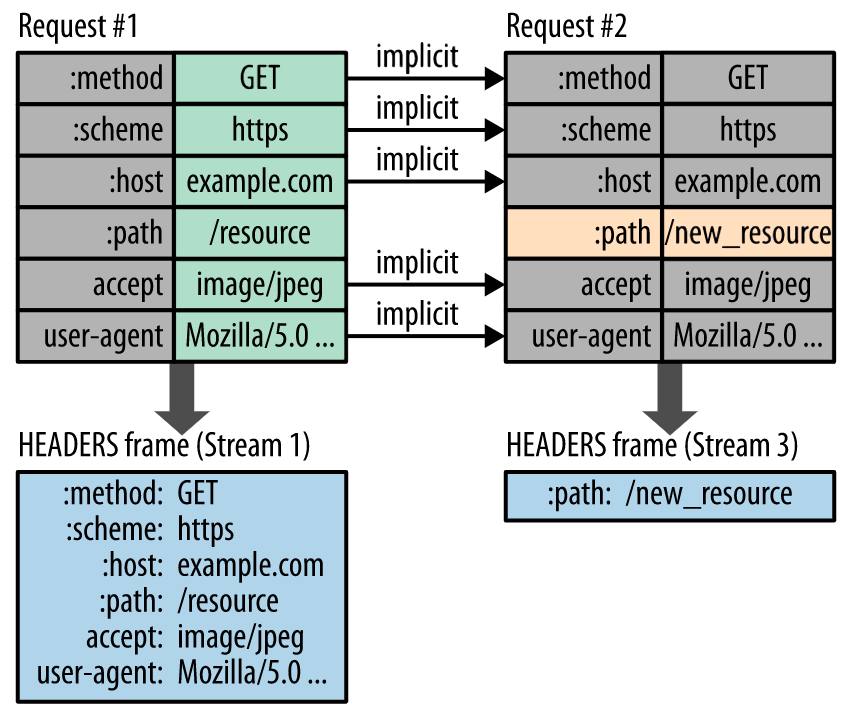
HPACK 压缩上下文包含一个静态表和一个动态表:静态表在规范中定义,并提供了一个包含所有连接都可能使用的常用 HTTP 标头字段(例如,有效标头名称)的列表;动态表最初为空,将根据在特定连接内交换的值进行更新。 因此,为之前未见过的值采用静态 Huffman 编码,并替换每一侧静态表或动态表中已存在值的索引,可以减小每个请求的大小。
注:在 HTTP/2 中,请求和响应标头字段的定义保持不变,仅有一些微小的差异:所有标头字段名称均为小写,请求行现在拆分成各个 :method、:scheme、:authority 和 :path 伪标头字段。
更安全的SSL
因为客户端和server之间在确立使用http1.x还是http2.0之前,必须要要确认对方是否支持http2.0,所以这里必须要有个协商的过程。最简单的协商也要有一问一答,客户端问server答,即使这种最简单的方式也多了一个RTT的延迟,我们之所以要修改http1.x就是为了降低延迟,显然这个RTT我们是无法接受的。
google制定SPDY的时候也遇到了这个问题,他们的办法是强制SPDY走https,在SSL层完成这个协商过程。ssl层的协商在http协议通信之前,所以是最适合的载体。google为此做了一个tls的拓展,叫NPN(Next Protocol Negotiation),从名字上也可以看出,这个拓展主要目的就是为了协商下一个要使用的协议。
HTTP2虽然没有强制要走ssl层,但大部分浏览器厂商(除了IE)却只实现了基于https的2.0协议。HTTP2.0没有使用NPN,而是另一个tls的拓展叫ALPN(Application Layer Protocol Negotiation)。此外,HTTP2.0对tls的安全性做了近一步加强,通过黑名单机制禁用了几百种不再安全的加密算法,一些加密算法可能还在被继续使用。如果在ssl协商过程当中,客户端和server的cipher suite没有交集,直接就会导致协商失败,从而请求失败。