也是最近的一个需求, 将一个 Excel 表, 多列转多行, 就把那种行的, 业务人员经常搞的那种垃圾表,给它转为咱熟悉的数据库表的形式, 多列转多行. 还要帮他们处理数据, 恶心得一批, 其实也不一定非要用什么 Pandas , 就循环遍历二维数据而已, 可能是, Pandas 比较很好, 就总是会将它作为我的第一选择, 事实证明, 它确实无敌强, 理论上能处理任何数据的骚操作.
需求
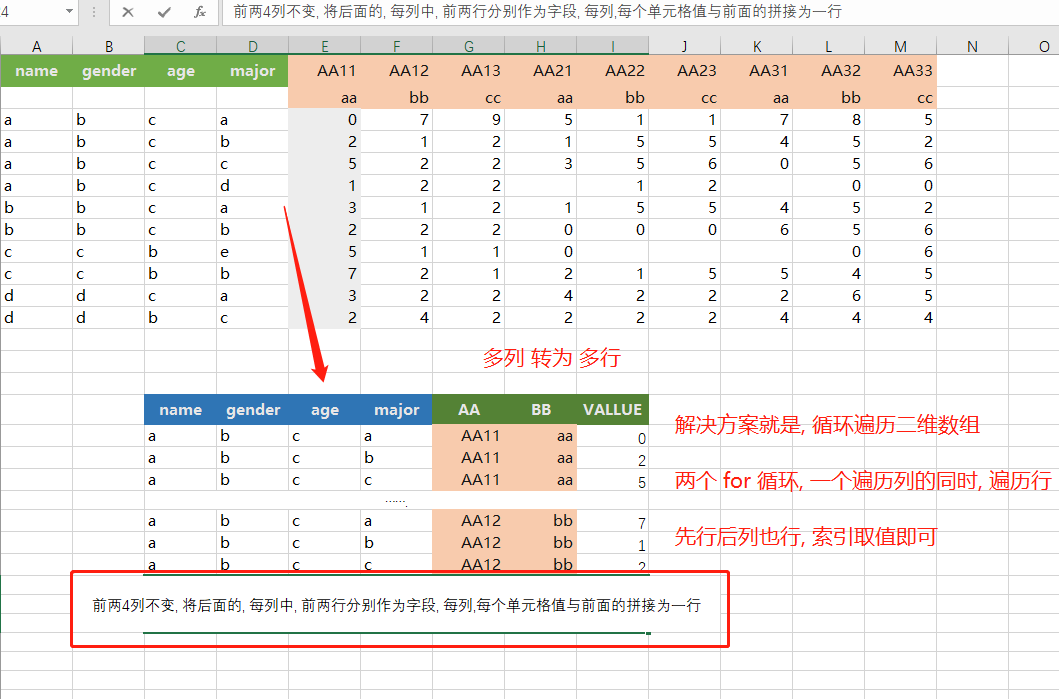
注: 写错字了, 木有 "两", 就是 前 4 列, 尴尬得一批.
方案
- 读取数据为一个数据, 用 Pandas 来读, iloc 来索引值, 根据下标
- 两个 for 循环, 分别代表两个方向 (垂直 和 水平) 谁先谁后, 无所谓的, 结果不变, 只是顺序变了.
- 假设我们, 外层循环为水平方向, 内层则为 垂直方向. (外层每移动 1 列, 内层则移动 n 行)
- 最后把所有的结果, 拼接起来, 存为 Excel 即可
实现
这里我用我小伙伴的代码吧, 自己就不写了, 写啥代码, 要什么自行车.. 会搬砖, 收藏, 还有模仿, 这才是代码成功之道
核心代码
df = pd.read_excel(file_path)
columns = df.columns.values
# 需要转置的那部分 DF
row_n = df.shape[0] -1
col_n = df.shape[1] - 4
ret = [] # 大列表来存储所有的
# 外层水平向右1列, 内层垂直向下遍历移多行
for i in range(col_n):
for j in range(row_n):
# 索引取值 iloc[行索引,列索引] 即可
lst = [
# 先取前四列, j+1 是为了跳过第 2 行
df.iloc[j+1, 0], df.iloc[j+1, 1],
df.iloc[j+1, 2], df.iloc[j+1, 3],
# 再取当前列的, 前两行, 和 对应的值 (i,j) 再来3个字段
columns[i+4], # 当前的列名, columns 是列字段列表
df.iloc[0, i+4], # 第一行,当前列的那个值, 即字段下面那个
df.iloc[j+1, i+4] # j 是不断往下走, 边走边取值
]
# 每一次取值, 则作为新数据的一行
ret.append(lst)
# 最后再将这个新的二维数据变为 DataFrame, cols 自定义, 存 Excel 即可
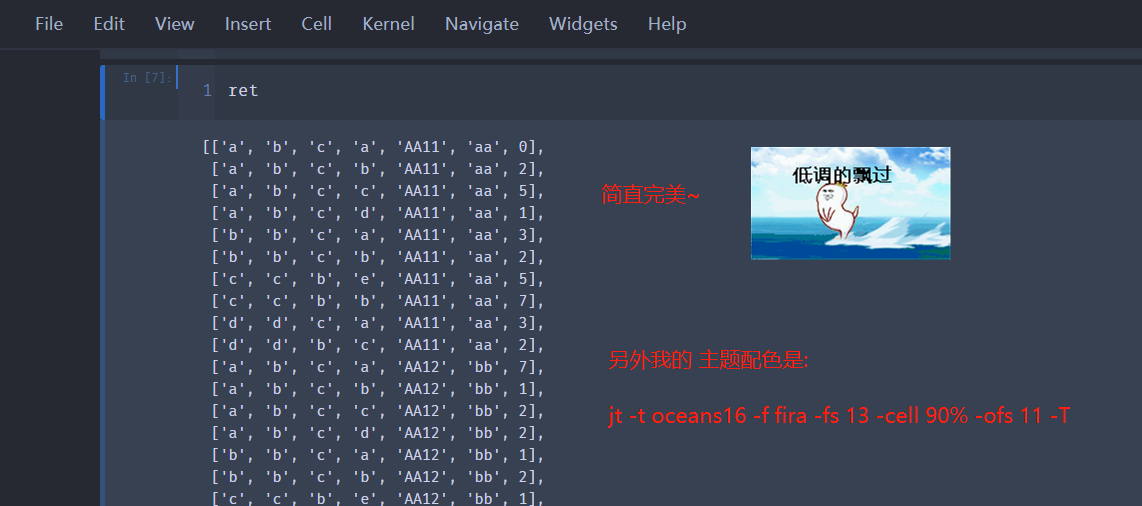
之列来一波运行效果呀
完整代码
import pandas as pd
def get_data(file_path):
"""将Excel读取为DF"""
return pd.read_excel(file_path)
def col_to_row(df):
"""多行转多列,返回转好的二维数组"""
columns = df.columns.values
# 需要转置的那部分 DF
row_n = df.shape[0] -1
col_n = df.shape[1] - 4
ret = []
for i in range(col_n):
for j in range(row_n):
# 索引取值 iloc[行索引,列索引] 即可
lst = [
# 先取前四列, j+1 是为了跳过第 2 行
df.iloc[j+1, 0], df.iloc[j+1, 1],
df.iloc[j+1, 2], df.iloc[j+1, 3],
# 再取当前列的, 前两行, 和 对应的值 (i,j) 再来3个字段
columns[i+4],
df.iloc[0, i+4],
df.iloc[j+1, i+4]
]
# 每一次取值, 则作为新数据的一行
ret.append(lst)
return ret
def save_excel(d2_array, col_names, save_path):
"""将一个二维数组,拼接为DF 再存为Excel"""
pd.DataFrame(d2_array,
columns=col_names).to_excel(
save_path, index=False
)
# 主逻辑
data = get_data("D:/test_data/多列转多行.xlsx") # 获取数据
d2_array = col_to_row(data) # 处理数据
col_names = ['name','gender','age', 'major', 'I', 'AM', 'NB']
save_excel(d2_array, col_names, "D:/youge.xlsx") # 存储数据
print("ok!")
然后来看一波, 结果, 从 Excel.

小结
- 行列转换, 除了用什么 stack(), pivot, melt 之类的, 也有看需求, 暴力来循环的
- 这个案例关键在于, 两个 for 循环来移动取值(下标) , 类似于, 指针移动在二维数组中
- 理解原理就行, 多搬砖和收藏点赞才是偷懒的唯一途径