趁热打铁, 一波 SQL 继续带走 ~~
虽然是假期, 但我也不想出去逛, 宅着也不想看书和思考人生, 除了做饭, 就更多对着电脑发呆. 时而看了下微信群, 初中小伙伴结合, 祝福寄语 和 随份子 都已安排. 满满地的羡慕哇. 别人的欢愉, 终将还是与我没啥太大关系. 而我在追求啥呢, 现在的我没有社交, 也没有什么朋友, 日常疲与应付工作, 如果谈思考人生的话, 我确实是会在思考人生在世的意义, 我始终觉得人生没有意义, 如果不做点啥, 只是平庸地活着. 而我现在就是, 就是为了活着, 而活着, 也不知道意义在哪. 又回想一个大学老师, 以他的经历告诉我们:
- 人生的意义, 在于追求
- 人生的价值, 在于奉献
一开始是觉得, 这个老师价值观挺正, 比思修老师还正, 当然也没几个人将其当做一回事儿. 现当我每天在疲于工作的时候, 突然就会想这个问题, 尤其是在深圳这样的一线城市. 我不禁一次次追问自己, 我追求啥? 我又奉献了啥? 结论是, 现在的我,或许从这个很正的价值观来看, 我是在浪费生命, 和碌碌无为, 既甘于平庸, 有对平庸有偶尔的愤怒.
很多时候都是思而不得, 就假借不断工作来麻痹自己, 当然领导是对我挺满意的, 其实我也不在乎, 只想用工作或者, 写代码还麻痹自己, 这也是写这些, 没啥用的笔记的原因之一.... 似乎有点扯远了, sql 回归主题, 继续刷 sql 呀, 技术就是需要不断学习, 练习 和积淀的过程.
表关系
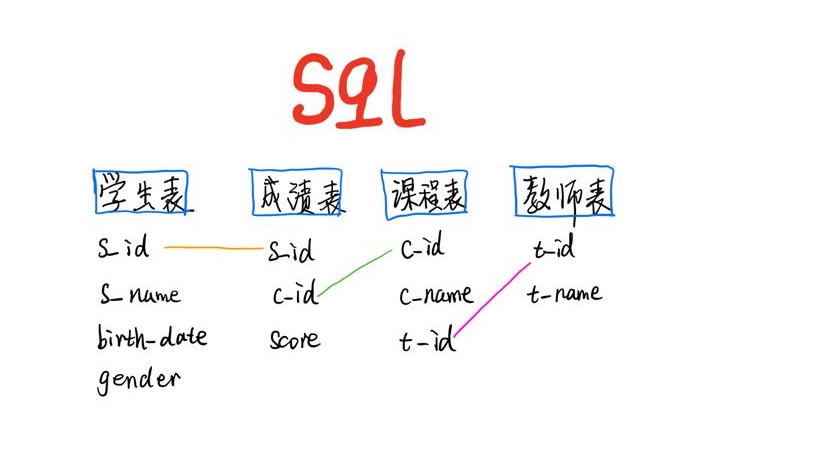
上篇是整了个, 还是有些稍微复杂的 套娃, 从 a 写到 g 了. 这篇还是来一些稍微简单些的, 练习而已, 不要太当真.
需求 01
查询 每门课程的学生选课人数 (超过 2人 才统计)
要求 输出课程号 和 选修人数, 查询结果 按人数 降序, 如人数相同, 按课程号 升序 排列
分析
从 score 中对 c_id 进行 group by , 然后 再 having 出 count(s_id) > 2 即可
select
c_id,
count(distinct s_id)
from score
group by c_id
having count(distinct s_id) > 2
+------+----------------------+
| c_id | count(distinct s_id) |
+------+----------------------+
| 0002 | 3 |
| 0003 | 3 |
+------+----------------------+
2 rows in set (0.00 sec)
然后再按照 人数降序, 课程号升序, 这不简单得一批.
select
c_id,
count(distinct s_id) as chosed_num
from score
group by c_id
having count(distinct s_id) > 2
order by chosed_num desc, c_id asc
+------+------------+
| c_id | chosed_num |
+------+------------+
| 0002 | 3 |
| 0003 | 3 |
+------+------------+
2 rows in set (0.00 sec)
这种 group by + having 的, 非常简单了, 真的理解了 group by 不论是从 sql 的视角, 还是 从 R, 从 Pandas 的视角来看, 一旦真正了解, 数据分析基本掌握了一大半. 仔细一想, 每天做的数据分析处理的工作, 不都是在按不同维度进行 group by 嘛.., 业务就是这样的, 看似复杂, 其实还是围绕 group by 来做维度细分的呀.
需求 02
查询 至少选修两门课的 学生学号, 姓名, 课程名称, 分数
分析
先将选了 2 门课以上的 s_id 找出来, 然后从 score 表, course 表, student 中匹出相应的字段即可
select s_id from score
group by s_id having count(c_id) > 2
+------+
| s_id |
+------+
| 0001 |
| 0003 |
+------+
2 rows in set (0.00 sec)
然后就是把 1, 3 号兄弟, 的姓名, 学号, 课程名称等都 匹上 即可. 之前写类似的我用的 套娃, 现在打算不那样做, 用子查询来弄, 即从 score 中, 筛选出 1, 3 号兄弟的 成绩表, 然后再 inner join 上其他的信息.
不对, 直接先来连接上, 最后再整体过滤吧. 先不过滤, 不考虑性能, 这样先我感觉语句会更顺一点.
select
a.s_id,
c.s_name,
b.c_name,
a.score
from score as a
inner join course as b
on a.c_id = b.c_id
inner join student as c
on a.s_id = c.s_id
-- 最后再来进行过滤
where a.s_id in (
select s_id from score
group by s_id having count(c_id) > 2
)
当然也可以先来 where 的, 就是先套娃嘛, 跟之前的一样的. 但我感觉, 不太好读, 说实话, 对于套娃.
select
b.s_id,
d.s_name,
c.c_name,
b.score
from (
select
a.s_id,
a.c_id,
a.score
from score as a
where a.s_id in (
select s_id from score
group by s_id having count(c_id) > 2
)
) as b
inner join course as c
on b.c_id = c.c_id
inner join student as d
on b.s_id = d.s_id
+------+-----------+--------+-------+
| s_id | s_name | c_name | score |
+------+-----------+--------+-------+
| 0001 | 王二 | 语文 | 80 |
| 0001 | 王二 | 数学 | 90 |
| 0001 | 王二 | 英语 | 99 |
| 0003 | 胡小适 | 语文 | 80 |
| 0003 | 胡小适 | 数学 | 80 |
| 0003 | 胡小适 | 英语 | 80 |
+------+-----------+--------+-------+
6 rows in set (0.00 sec)
虽然二者的结果是一样的, 但我感觉, 我还是更加喜欢前面的吧, 虽然我平时在工作中用的更多是 后面的套娃, 其实写得贼难受了, 套娃, 一层层的, 别说别人看不懂 , 过一段时间, 我自己都看不懂是咋嵌套的了.
小结
- group by + having 过滤, 这个技能是必须要熟练运用的呀, 而且应用场景还特别多
- join 和 where, 条件放哪的问题, 我觉得都没关系, 看是写套娃还是最后来过滤, 代码可读上, 我选择先 join 最后再来对整体进行 where , 而, 从功能实现上, 我更多的还是套娃, 一个个算出来, 套上, 然后在进行 join
- 思考, sql 的的执行顺序很关键, 这也是我现在写SQL的风格, 解释器怎么读,我就怎么写, 在顺序上