首先,找到一个皮肤网站,其中一个著名的皮肤网站就是 https://littleskin.cn 。进入网站,我们就会见到一堆皮肤,这就是今天我们要爬的皮肤。给各位分享一下代码。
PS:另外很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
import requests
import re
import time
import json
download_sucess = True
time.sleep(1.5)
pictures = input('你想下载多少张皮肤:')
while pictures.isdigit() == False:
print("请输入数字!")
pictures = input('你想下载多少张皮肤:')
Path = input('请输入保存的路径:')
print("请稍等......")
pictures = int(pictures)
for i in range(1,pictures+1):
url = 'https://littleskin.cn/skinlib/data?filter=skin&uploader=0&sort=likes&keyword=&page=' + str(i)
response = requests.get(url).json()
ids = re.findall("'tid': (.*?),",str(response))
for id in ids:
picture_url = 'https://littleskin.cn/preview/' + id + '.png'
picture_name = picture_url.strip('https://littleskin.cn/preview/')
picture = requests.get(picture_url).content
try:
with open(Path + '//%s'%picture_name,'wb') as file:
file.write(picture)
except FileNotFoundError:
download_sucess = False
print('路径不存在!')
break
if download_sucess == False:
print("下载失败!")
elif download_sucess == True:
print('下载完成!')最终效果:
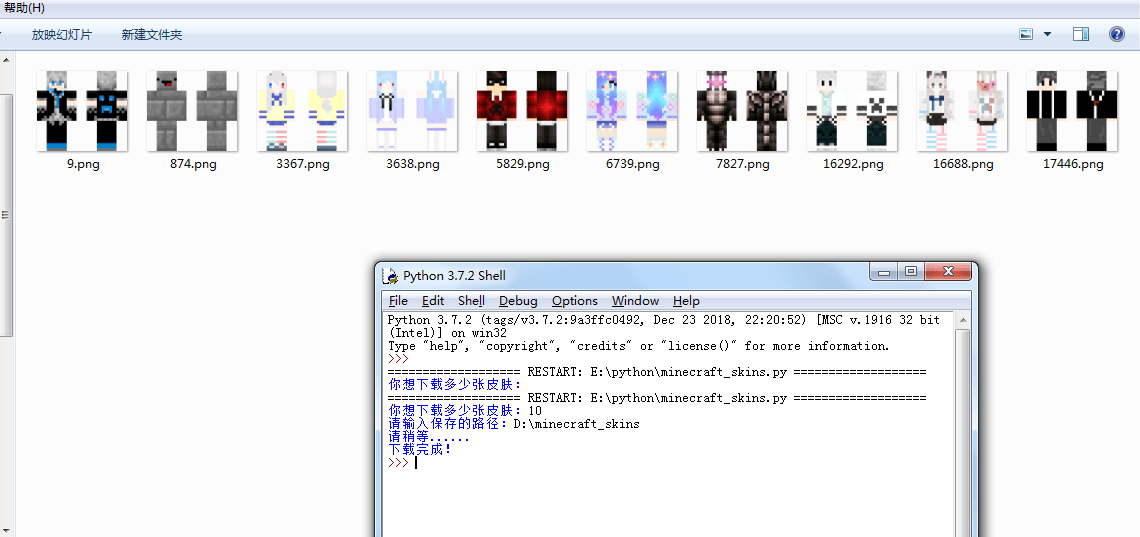
皮肤爬取的原理是通过 json 格式来查看网站的每一张图片的 id 号,再用拼接的方式组成一个图片地址,最后再用二进制的方式把图片存放在我们的文件夹里。希望各位能通过这篇文章学到东西。
总结:很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我整理啦从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF等】需要的可以进Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。