为了简化问题,我们将短文本分为两种类别中的一种,即要么是正常微博、要么是自杀倾向微博。这样,有了上次的微博树洞,训练集和测试集就非常好获得了。由于是短文本二分类问题,可以使用 scikit-learn 的 SVM 分类模型。
不过要注意的是,我们的分类器并不能保证分类出来的结果百分百正确,毕竟心理状态是很难通过文本准确识别出来的,我们只能通过文字,大致判断其抑郁情况并加以介入。实际上这是一个宁可错杀一百,不可放过一个的问题。毕竟放过一个,可能就有一条生命悄然流逝。
本文源代码: https://github.com/Ckend/suicide-detect-sv... 欢迎一同改进这个项目,在训练集和模型方面,改进的空间还相当大。
PS:另外很多人在学习Python的过程中,往往因为遇问题解决不了或者没好的教程从而导致自己放弃,为此我建了个Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
1. 数据准备
数据集整体上分两个部分,一部分是训练集、一部分是测试集。其中,训练集和测试集中还要分为正常微博短文本和自杀倾向短文本。
将上一篇爬取微博树洞的文章中得到的数据进行人工筛选后,挑出 300 条作为训练集(有点少,其实业界至少也要 3000 条以上),再根据上次的微博爬虫随意爬取 10000 条微博作为训练集的正常微博类。另外再分别搜集自杀倾向微博和普通微博各 50 条作为测试集。
每条微博按行存储在 txt 文件里。训练集中,正常微博命名为 normal.txt, 自杀倾向微博命名为 die.txt。测试集存放在后缀为_test.txt 的文件中:

此外,接下来我们会使用到一个机器学习工具包叫 scikit-learn (sklearn),其打包好了许多机器学习模型和预处理的方法,方便我们构建分类器,在 CMD/Terminal 输入以下命令安装:
pip install -U scikit-learn
如果你还没有安装 Python,请看这篇文章安装 Python,然后再执行上述命令安装 sklearn.
2. 数据预处理
我们使用一个典型的中文自然语言预处理方法:对文本使用结巴分词后将其数字化。
由于具有自杀倾向的微博中,其实类似于 "死"、"不想活"、"我走了" 等这样的词语比较常见,因此我们可以用 TF-IDF 将字符串数字化。如果你不了解 TF-IDF,请看这篇文章: 文本处理之 tf-idf 算法及其实践
数字化的部分代码如下。
print('(2) doc to var...')
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
# CountVectorizer考虑每种词汇在该训练文本中出现的频率,得到计数矩阵
count_v0= CountVectorizer(analyzer='word',token_pattern='w{1,}')
counts_all = count_v0.fit_transform(all_text)
count_v1= CountVectorizer(vocabulary=count_v0.vocabulary_)
counts_train = count_v1.fit_transform(train_texts)
print("the shape of train is "+repr(counts_train.shape) )
count_v2 = CountVectorizer(vocabulary=count_v0.vocabulary_)
counts_test = count_v2.fit_transform(test_texts)
print("the shape of test is "+repr(counts_test.shape) )
# 保存数字化后的词典
joblib.dump(count_v0.vocabulary_, "model/die_svm_20191110_vocab.m")
counts_all = count_v2.fit_transform(all_text)
print("the shape of all is "+repr(counts_all.shape))
# 将计数矩阵转换为规格化的tf-idf格式
tfidftransformer = TfidfTransformer()
train_data = tfidftransformer.fit(counts_train).transform(counts_train)
test_data = tfidftransformer.fit(counts_test).transform(counts_test)
all_data = tfidftransformer.fit(counts_all).transform(counts_all) 3. 训练
使用 scikit-learn 的 SVM 分类模型,我们能很快滴训练并构建出一个分类器:
print('(3) SVM...')
from sklearn.svm import SVC
# 使用线性核函数的SVM分类器,并启用概率估计(分别显示分到两个类别的概率如:[0.12983359 0.87016641])
svclf = SVC(kernel = 'linear', probability=True)
# 开始训练
svclf.fit(x_train,y_train)
# 保存模型
joblib.dump(svclf, "model/die_svm_20191110.m")这里我们忽略了 SVM 原理的讲述,SVM 的原理可以参考这篇文章:支持向量机(SVM)—— 原理篇
4. 测试
测试的时候,我们要分别计算模型对两个类别的分类精确率和召回率。scikit-learn 提供了一个非常好用的函数 classification_report 来计算它们:
# 测试集进行测试
preds = svclf.predict(x_test)
y_preds = svclf.predict_proba(x_test)
preds = preds.tolist()
for i,pred in enumerate(preds):
# 显示被分错的微博
if int(pred) != int(y_test[i]):
try:
print(origin_eval_text[i], ':', test_texts[i], pred, y_test[i], y_preds[i])
except Exception as e:
print(e)
# 分别查看两个类别的准确率、召回率和F1值
print(classification_report(y_test, preds)) 结果:
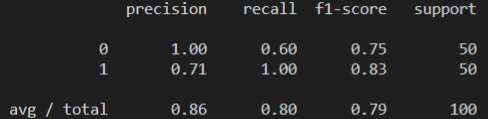
对自杀倾向微博的分类精确率为 100%,但是查全率不够,它只找到了 50 条里的 60%,也就是 30 条自杀倾向微博。
对于正常微博的分类,其精确率为 71%,也就是说有部分正常微博被分类为自杀倾向微博,不过其查全率为 100%,也就是不存在不被分类的正常微博。
这是建立在训练集还不够多的情况下的结果。我们的自杀倾向微博的数据仅仅才 300 条,这是远远不够的,如果能增加到 3000 条,相信结果会改进不少,尤其是对于自杀倾向微博的查全率有很大的帮助。预估最终该模型的精确率和召回率至少能达到 95%。
本次分享大家都明白了没? 另外很多人在学习Python的过程中,往往因为遇问题解决不了从而导致自己放弃,为此我建了个Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决哦,一起相互监督共同进步
本文的文字及图片来源于网络加上自己的想法,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。