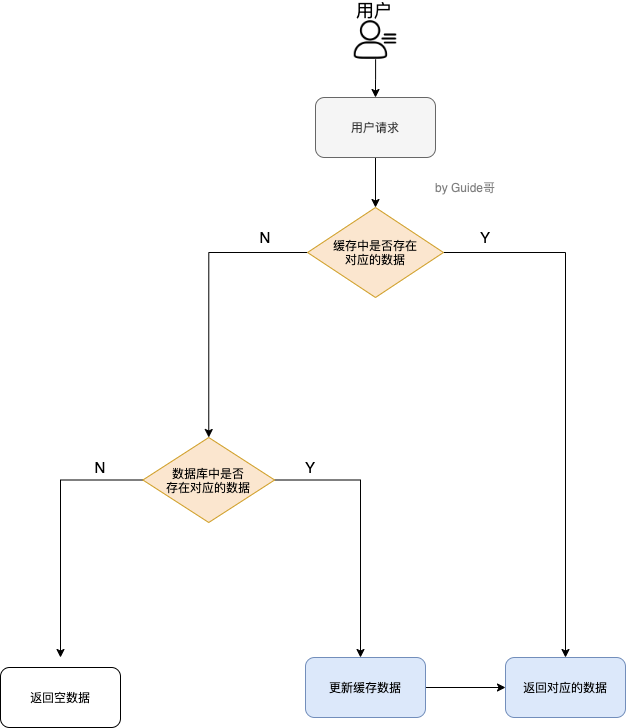
首先讲讲缓存数据的处理流程是怎样的?
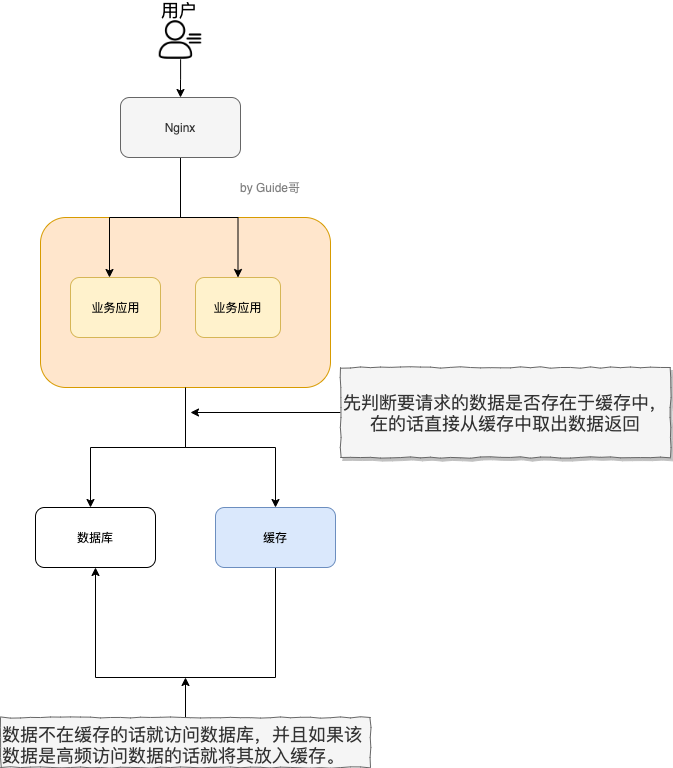
为什么要用 Redis/为什么要用缓存?
主要是为了提升用户体验以及应对更多的用户。
缓存的有点:
高性能 :
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。换句话说内存比磁盘快
注意:要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据!
高并发:
一般像 MySQL这类的数据库的 QPS(QPS(Query Per Second):服务器每秒可以执行的查询次数;) 大概都在 1w 左右(4核8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到30w+(就单机redis的情况,redis 集群的话会更高)。
直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。
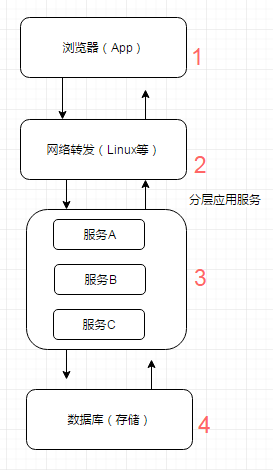
缓存可以用在哪里:
如下图,缓存的使用可以出现在1~4的各个环节中,每个环节的缓存方案与使用各有特点
缓存的特征:
- 命中率
命中率=返回正确结果数/请求缓存次数,命中率问题是缓存中的一个非常重要的问题,它是衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高。
- 最大元素(最大空间)
缓存中可以存放的最大元素的数量,一旦缓存中元素数量超过这个值(或者缓存数据所占空间超过其最大支持空间),那么将会触发缓存启动清空策略根据不同的场景合理的设置最大元素值往往可以一定程度上提高缓存的命中率,从而更有效的时候缓存。
- 清空策略
如上描述,缓存的存储空间有限制,当缓存空间被用满时,如何保证在稳定服务的同时有效提升命中率?这就由缓存清空策略来处理,设计适合自身数据特征的清空策略能有效提升命中率。常见的一般策略有:
-
- FIFO(first in first out)
先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
-
- LFU(less frequently used)
最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
-
- LRU(least recently used)
最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
除此之外,还有一些简单策略比如:
-
- 根据过期时间判断,清理过期时间最长的元素;
- 根据过期时间判断,清理最近要过期的元素;
- 随机清理;
- 根据关键字(或元素内容)长短清理等。
缓存介质分类:
虽然从硬件介质上来看,无非就是内存和硬盘两种,但从技术上,可以分成内存、硬盘文件、数据库。
-
- 内存:将缓存存储于内存中是最快的选择,无需额外的I/O开销,但是内存的缺点是没有持久化落地物理磁盘,一旦应用异常break down而重新启动,数据很难或者无法复原。
- 硬盘:一般来说,很多缓存框架会结合使用内存和硬盘,在内存分配空间满了或是在异常的情况下,可以被动或主动的将内存空间数据持久化到硬盘中,达到释放空间或备份数据的目的。
- 数据库:前面有提到,增加缓存的策略的目的之一就是为了减少数据库的I/O压力。现在使用数据库做缓存介质是不是又回到了老问题上了?其实,数据库也有很多种类型,像那些不支持SQL,只是简单的key-value存储结构的特殊数据库(如BerkeleyDB和Redis),响应速度和吞吐量都远远高于我们常用的关系型数据库等。
缓存种类:
-
本地缓存:指的是在应用中的缓存组件,其最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适;同时,它的缺点也是应为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
-
分布式缓存:指的是与应用分离的缓存组件或服务,其最大的优点是自身就是一个独立的应用,与本地应用隔离,多个应用可直接的共享缓存。
参考文档:
https://tech.meituan.com/2017/03/17/cache-about.html
https://github.com/Snailclimb/JavaGuide/blob/master/docs/database/Redis/redis-all.md