一、mysql的查询过程:
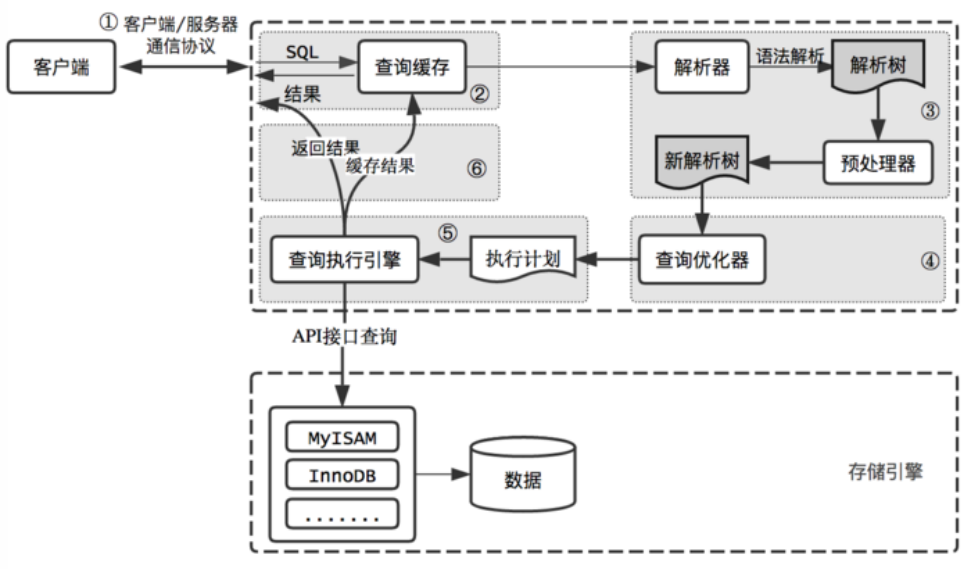
客户端向MySQL服务器发送一条查询请求 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段 服务器进行SQL解析、预处理、再由优化器生成对应的执行计划 MySQL根据执行计划,调用存储引擎的API来执行查询 将结果返回给客户端,同时缓存查询结果。图示如下:
二、SQL优化建议:
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 创建索引的格式: create index 索引名 on 表名(字段名[(字符长度)]);
2.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
3.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描, 如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值, 然后这样查询: select id from t where num=0
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。
5.下面的查询也将导致全表扫描: select id from t where name like '%abc%' 若要提高效率,可以考虑全文检索。
6.in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3
7.使用预编译查询。程序中经常根据用户输入来动态执行sql语句,这时应尽量使用参数化sql,不仅可以避免sql注入,还可以提高执行速度。
8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。 如: select id from t where num/2=100 应改为: select id from t where num=100*2
9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。 如: select id from t where substring(name,1,3)='abc'--name以abc开头的id 应改为: select id from t where name like 'abc%' 。
10.调整where子句中的连接顺序。DBMS一般自上而下解析where子句,根据这个原理,表连接最好写在其他where条件之前,那些可以过滤掉最大数量记录。
11.很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num) 但如果可以用表连接,则表连接比exists更有效率。
12.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。 这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
13.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
14.避免频繁创建和删除临时表,以减少系统表资源的消耗。
15.尽量将多条sql语句压缩到一句中,因为每次执行sql的时候都要建立网络连接、进行权限校验、进行sql语句查询优化、发送执行结果,整个过程非常耗时。
16.当sql语句连接多个表时,使用表别名并把别名前缀于每个列名上可以减少解析时间。 待补充。