操作系统对硬件资源统一管理,并把资源分配给各个APP使用,资源的使用情况直接影响到程序运行的速度。 如果资源使用过高,甚至会造成服务器宕机,直接造成业务中断。
实时掌握资源使用情况式每一个系统管理员必备的技能,可以及时发现潜在问题并及时处理。
其实就是 网管。 相当于医生 但是给计算机看病的,为了防患于未然,就需要各种的命令来了解计算机的各种状态:
1、资源管理的命令
2、阈值是多少。(关键指标)
3、如何定位问题
4、如何解决问题
一. CPU
查看命令: ps(静态任务管理器) top(动态任务管理器) uptime()
查看项: 进程总数、running队列、load值、使用率。
[root@python ~]# ps -ef 或者 ps aux
.........太多了不写了
[root@python ~]# top
.........
[root@python ~]# uptime
.........
# 查看cpu信息 cat /proc/cpuinfo
[root@python ~]# cat /proc/cpuinfo # 查看cpu信息
cpu 是分 几核几核的。 有几核,这里的信息就会分为几组进行展
processor : 0 # cpu的逻辑编号是多少,(几核)
vendor_id : GenuineIntel
cpu family : 6
model : 42
model name : Intel(R) Core(TM) i5-2320 CPU @ 3.00GHz # cpu型号
stepping : 7
microcode : 0x2e
cpu MHz : 3001.000
cache size : 6144 KB
physical id : 0 # cpu的物理编号(真是存在的cpu)
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc eagerfpu pni pclmulqdq ssse3 cx16 pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx hypervisor lahf_lm ssbd ibrs ibpb stibp tsc_adjust arat spec_ctrl intel_stibp flush_l1d arch_capabilities
# flags 代表cpu 支持的功能。
bogomips : 6002.00
clflush size : 64
cache_alignment : 64
address sizes : 43 bits physical, 48 bits virtual
power management:
CPU - 进程总数:
总进程数 - 0业务进程数 ≈ 业务进程数.(0业务进程数 意思是装完机之后,初始的这些不算在内。的业务数)
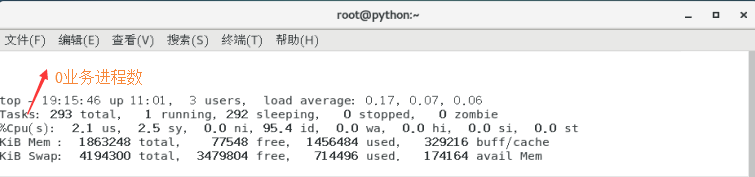
如果cpu使用率高,进程数也多:
那说明 机器压力大,需要升级配置或者通过集群解决。
如果cpu使用率高,但是业务进程数不多,(一堆乱七八糟的其他进程):
查看任务管理器中的进程,找找是否有陌生的进程,不认识的百度,综合后续指标 继续判断。
CPU - running 队列:
预警线: 单核不超过10个
超过说明CPU组员不足,是否是业务进程造成的:
是:那说明 机器压力大,需要升级配置或者通过集群解决。
不是: 找到 running队列中的进程,判断是否是恶意的程序,恶意程序直接 Kill 掉,并清除相关的链接
CPU - load 值 和 使用率:
这两者是成正比的, 使用率高,负载就高
预警线: load average 接受范围 3-5 [单个核 多核就乘以 N ], 使用率80%。(load值 最少要看10-15分钟的。 80%说的是整体的一个比例。)
重点看 CPU 的使用率,单核使用率 100% , 多核 N*100%
找到高消耗CPU的进程,判断是否为业务进程
是:那说明 机器压力大,需要升级配置或者通过集群解决。
不是: 找到 running队列中的进程,判断是否是恶意的程序,恶意程序直接 Kill 掉,并清除相关的链接
二. 磁盘
查看命令: df iostat iotop( iotop 如果没有, yum install iotop)
检查项: 使用率, IO队列长度
[root@python ~]# fdisk -l 磁盘 /dev/sda:42.9 GB, 42949672960 字节,83886080 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节 磁盘标签类型:dos 磁盘标识符:0x000bf194 设备 Boot Start End Blocks Id System /dev/sda1 * 2048 2099199 1048576 83 Linux /dev/sda2 2099200 83886079 40893440 8e Linux LVM 磁盘 /dev/mapper/centos_python-root:37.6 GB, 37576769536 字节,73392128 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节 磁盘 /dev/mapper/centos_python-swap:4294 MB, 4294967296 字节,8388608 个扇区 Units = 扇区 of 1 * 512 = 512 bytes 扇区大小(逻辑/物理):512 字节 / 512 字节 I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘使用率预警线: 80%
超过80%的应该加磁盘,或者清理磁盘空间
队列长度 2-3 (超过就说明 IO 不够用了)
检查那个进程占用了 IO, 是否为恶意进程
是: 找到进程kill掉,清除对应文件
不是:优化 IO 磁盘阵列或者上存储
[root@python ~]# df -Th 文件系统 类型 容量 已用 可用 已用% 挂载点 /dev/mapper/centos_python-root xfs 35G 21G 15G 58% / devtmpfs devtmpfs 894M 0 894M 0% /dev tmpfs tmpfs 910M 0 910M 0% /dev/shm tmpfs tmpfs 910M 11M 900M 2% /run tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup /dev/sda1 xfs 1014M 286M 729M 29% /boot tmpfs tmpfs 182M 4.0K 182M 1% /run/user/42 tmpfs tmpfs 182M 36K 182M 1% /run/user/0 /dev/sr0 iso9660 4.3G 4.3G 0 100% /run/media/root/CentOS 7 x86_64


三. 内存
查看命令: free
查看项: 1.物理内存 2./swap(交换分区) 使用率
阈值: 物理内存 80% /swap :5% (swap使用时就说明物理内存不够用了。 因为数据都是由物理内存来提供的)
内存使用进程: ps
[root@python ~]# free -m total used free shared buff/cache available Mem: 1819 1281 81 5 456 310 Swap: 4095 790 3305
总内存 使用的内存 自由的 共享 缓存 有效的
使用内存时: 先拿 free 然后 cache 最后走 swap
App申请内存时也是先看free 有没有,再看cache够不够, 然后去used扫描看那些空间是长时间没有用的。
然后就会将这些数据 刷到 swap 中, 将腾出来的内存交给 App使用。
used --> swap 叫换出
swap --> used 叫换入
频繁的换入/换出, 就会对性能有很大的影响。 这是不应该的。
所以 swap 被使用就报警
使用 top命令 可以查看,进程对内存 (%MEM --memory) 的使用。 发现不对的就去查一查。
四. 网络
查看命令: iftop (iftop -i ens33 多块网卡的情况下,制定监控那块网卡)
检查项: 流入流出峰值
阈值: 总宽带的 80%

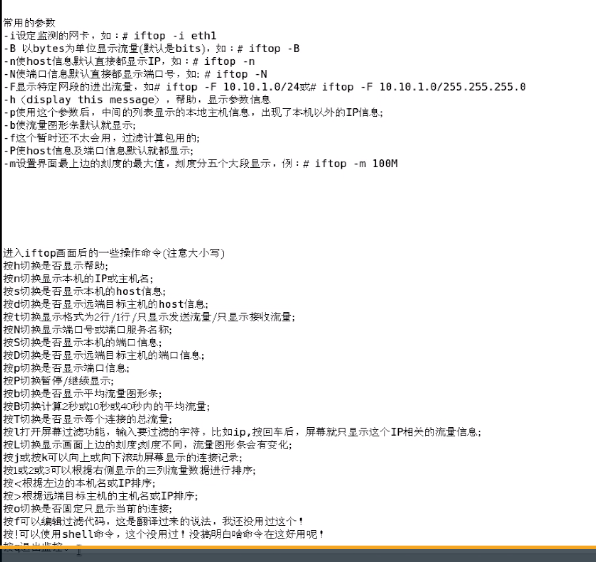
在检查时 一定要仔细啊。 不能随便 把进程就给杀了。 如果杀错了。 你老板就会杀了你。