通常来说,在我们的系统中会把数据永久保存在DB中,并且冗余一份数据在缓存中。读请求优先从缓存读取数据,没有再从DB读取,如下图:
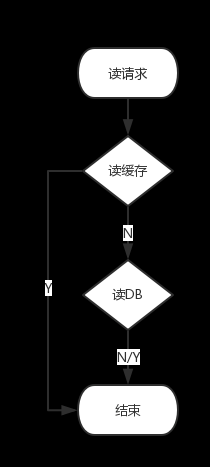
这样做的好处是可以减小DB的压力,提高请求的响应速度。
但这种架构在提升系统读请求处理能力的同时,给系统写请求的处理带来了不少的麻烦。因为数据在DB跟缓存中各自保存了一份,如何保证它们之间的数据一致就是需要注意的问题了。
当处理写请求时有两种方式:
一、先写缓存再写DB
- 如果第一步写缓存失败,直接返回,无影响。
- 如果缓存写成功,DB写失败,此时如果不清除缓存中已写入的数据,则会造成数据不一致(缓存中是新值,DB中是旧值)。
如果增加清除缓存的逻辑,那么清除操作又失败了该如何处理?
二、先写DB再写缓存
- 如果DB写入失败,直接返回,无影响。
- 如果DB写入成功,缓存写入失败则会造成数据不一致(即DB中是新值,缓存中是旧值)。
如果重试写入缓存,那重试也失败该如何处理?
三、问题分析
问题本质上就是一个分布式数据一致性问题,在不要求强一致性的场景下,我们只要开辟一个异步任务去保证最终一致性即可。
就上面所说的场景来说,发生失败时,我们可以开启一个异步线程去做数据回填操作,反复重试直到成功。如果采用异步线程回填数据的方式做最终一致性,那么这个容错性是内存级别的,也就是说如果此时重启服务(线程消失),那么这个重试任务就丢失了,导致数据不一致。
其实宏观上来说,缓存数据设置过期时间就是一种数据最终一致性的方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以DB为准,对缓存操作只是尽最大努力即可。也就是说如果DB写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从DB中读取新值然后回填缓存,完成数据的最终一致性。