爬取https://www.aqistudy.cn/historydata 网站的空气质量报告,爬取的数据以csv文件生成
scrapy startproject air_quality 创建scrapy项目
scrapy genspider api_history_spider https://www.apistudy.cn/historydata/index.php 编写spider
文件目录如图所示
seetings.py
1 ITEM_PIPELINES = { 2 'air_quality.pipelines.AirQualityPipeline': 300, 3 }
items.py
1 import scrapy 2 3 4 class AirQualityItem(scrapy.Item): 5 # define the fields for your item here like: 6 # name = scrapy.Field() 7 city_name = scrapy.Field() # 城市名称 8 record_date = scrapy.Field() # 检测日期 9 aqi_val = scrapy.Field() # AQI 10 range_val = scrapy.Field() # 范围 11 quality_level = scrapy.Field() # 质量等级 12 pm2_5_val = scrapy.Field() # PM2.5 13 pm10_val = scrapy.Field() # PM10 14 so2_val = scrapy.Field() # SO2 15 co_val = scrapy.Field() # CO 16 no2_val = scrapy.Field() # NO2 17 o3_val = scrapy.Field() # O3 18 rank = scrapy.Field() # 排名
pipelines.py
1 from scrapy.exporters import CsvItemExporter 2 3 class AirQualityPipeline(object): 4 5 def open_spider(self,spider): 6 self.file = open('air_quality.csv', 'wb') 7 self.exporter = CsvItemExporter(self.file) 8 self.exporter.start_exporting() 9 10 def close_spider(self,spider): 11 self.exporter.finish_exporting() 12 self.file.close() 13 14 def process_item(self, item,spider): 15 self.exporter.export_item(item) 16 return item
api_history_spider.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from urllib import parse 4 from air_quality.items import AirQualityItem 5 6 base_url = 'https://www.aqistudy.cn/historydata/' 7 8 class ApiHistorySpiderSpider(scrapy.Spider): 9 name = 'api_history_spider' 10 allowed_domains = ["aqistudy.cn"] 11 start_urls = ['https://www.aqistudy.cn/historydata/'] 12 13 def parse(self, response): 14 """ 15 解析初始页面 16 """ 17 # 获取所有城市的URL 18 city_url_list = response.xpath('//div[@class="all"]//div[@class="bottom"]//a//@href') 19 20 for city_url in city_url_list: 21 # 依次遍历城市URL 22 city_month_url = base_url + city_url.extract() 23 # 解析每个城市的月份数据 24 request = scrapy.Request(city_month_url, callback=self.parse_city_month) 25 yield request 26 27 def parse_city_month(self, response): 28 """ 29 解析该城市的月份数据 30 """ 31 # 获取该城市的所有月份URL 32 month_url_list = response.xpath('//table[@class="table table-condensed ' 33 'table-bordered table-striped table-hover ' 34 'table-responsive"]//a//@href') 35 36 for month_url in month_url_list: 37 # 依次遍历月份URL 38 city_day_url = base_url + month_url.extract() 39 # 解析该城市的每日数据 40 request = scrapy.Request(city_day_url, callback=self.parse_city_day) 41 yield request 42 43 def parse_city_day(self, response): 44 """ 45 解析该城市的每日数据 46 """ 47 url = response.url 48 item = AirQualityItem() 49 city_url_name = url[url.find('=') + 1:url.find('&')] 50 51 # 解析url中文 52 # item['city_name'] = city_url_name 53 item['city_name'] = parse.unquote(city_url_name) 54 55 # 获取每日记录 56 day_record_list = response.xpath('//table[@class="table table-condensed ' 57 'table-bordered table-striped table-hover ' 58 'table-responsive"]//tr') 59 for i, day_record in enumerate(day_record_list): 60 if i == 0: 61 # 跳过表头 62 continue 63 td_list = day_record.xpath('.//td') 64 65 item['record_date'] = td_list[0].xpath('text()').extract_first() # 检测日期 66 item['aqi_val'] = td_list[1].xpath('text()').extract_first() # AQI 67 item['range_val'] = td_list[2].xpath('text()').extract_first() # 范围 68 item['quality_level'] = td_list[3].xpath('.//div/text()').extract_first() # 质量等级 69 item['pm2_5_val'] = td_list[4].xpath('text()').extract_first() # PM2.5 70 item['pm10_val'] = td_list[5].xpath('text()').extract_first() # PM10 71 item['so2_val'] = td_list[6].xpath('text()').extract_first() # SO2 72 item['co_val'] = td_list[7].xpath('text()').extract_first() # CO 73 item['no2_val'] = td_list[8].xpath('text()').extract_first() # NO2 74 item['o3_val'] = td_list[9].xpath('text()').extract_first() # O3 75 item['rank'] = td_list[10].xpath('text()').extract_first() # 排名 76 77 yield item
运行spider
scrapy crawl api_history_spider
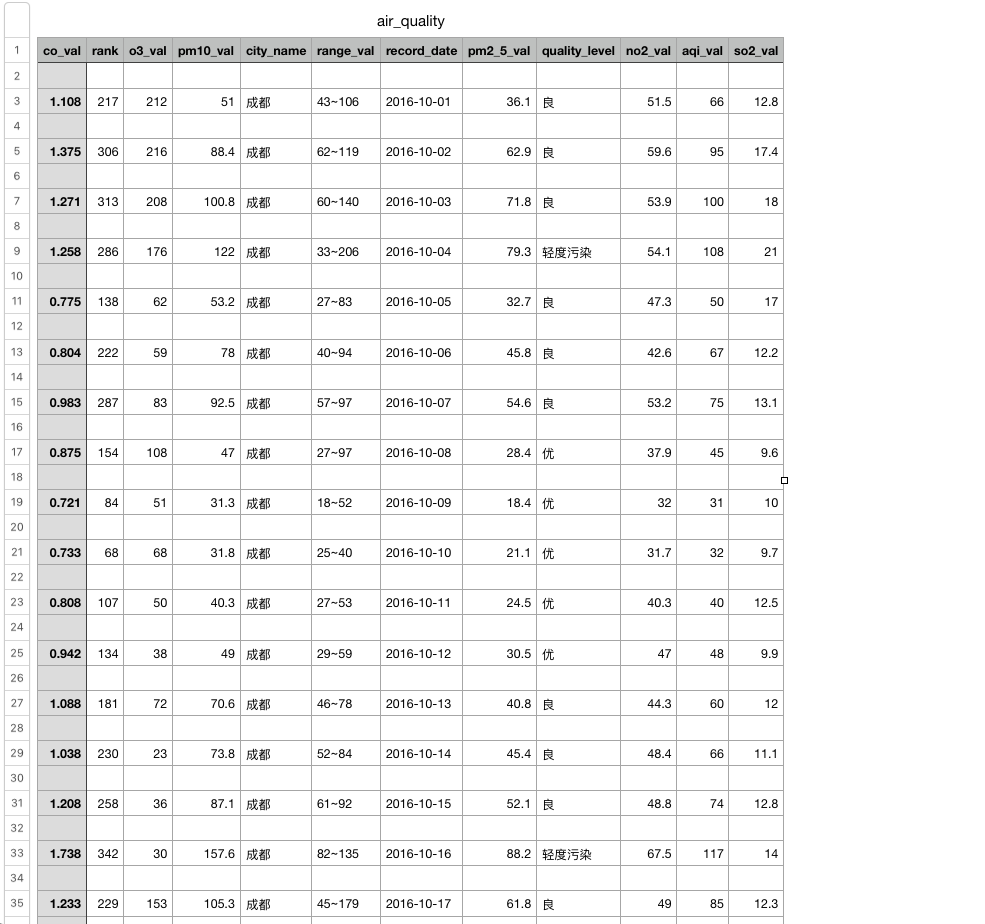
得到csv文件,部分如下图所示: