1. 概括数据:
1 from urllib.request import urlopen 2 from bs4 import BeautifulSoup 3 import re 4 import string 5 import operator 6 7 def cleanInput(input): 8 input = re.sub(' +', " ", input).lower() 9 input = re.sub('[[0-9]*]', "", input) 10 input = re.sub(' +', " ", input) 11 input = bytes(input, "UTF-8") 12 input = input.decode("ascii", "ignore") 13 cleanInput = [] 14 input = input.split(' ') 15 for item in input: 16 item = item.strip(string.punctuation) 17 if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'): 18 cleanInput.append(item) 19 return cleanInput 20 21 def ngrams(input, n): 22 input = cleanInput(input) 23 output = {} 24 for i in range(len(input)-n+1): 25 ngramTemp = " ".join(input[i:i+n]) 26 if ngramTemp not in output: 27 output[ngramTemp] = 0 28 output[ngramTemp] += 1 29 return output 30 content = str( 31 urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt").read(), 32 'utf-8') 33 ngrams = ngrams(content, 2) 34 sortedNGrams = sorted(ngrams.items(), key = operator.itemgetter(1), reverse=True) 35 print(sortedNGrams) 36 37 def isCommon(ngram): 38 commonWords = ["the", "be", "and", "of", "a", "in", "to", "have", "it", 39 "i", "that", "for", "you", "he", "with", "on", "do", "say", "this", 40 "they", "is", "an", "at", "but","we", "his", "from", "that", "not", 41 "by", "she", "or", "as", "what", "go", "their","can", "who", "get", 42 "if", "would", "her", "all", "my", "make", "about", "know", "will", 43 "as", "up", "one", "time", "has", "been", "there", "year", "so", 44 "think", "when", "which", "them", "some", "me", "people", "take", 45 "out", "into", "just", "see", "him", "your", "come", "could", "now", 46 "than", "like", "other", "how", "then", "its", "our", "two", "more", 47 "these", "want", "way", "look", "first", "also", "new", "because", 48 "day", "more", "use", "no", "man", "find", "here", "thing", "give", 49 "many", "well"] 50 for word in ngram: 51 if word in commonWords: 52 return True 53 return False
2. 马尔可夫模型:
对一个天气系统建立马尔可夫模型:
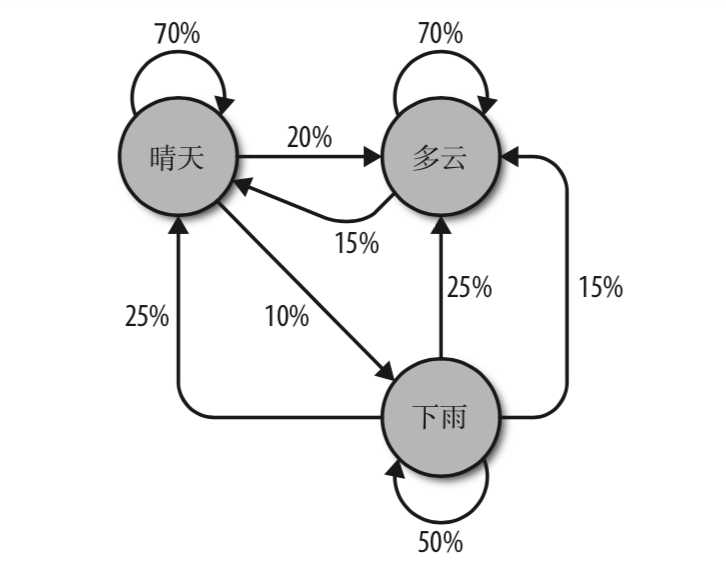
在这个天气系统模型中,如果今天是晴天,那么明天有 70% 的可能是晴天,20% 的可能 多云,10% 的可能下雨。如果今天是下雨天,那么明天有 50% 的可能也下雨,25% 的可 能是晴天,25% 的可能是多云。
3. 广度优先搜索算法:
广度优先搜索算法的思路是优先搜寻直接连接到起始页的所有链接(而不是找到一个链接 就纵向深入搜索)。如果这些链接不包含目标页面(你想要找的词条),就对第二层的链 接——连接到起始页的页面的所有链接——进行搜索。这个过程不断重复,直到达到搜索 深度限制或者找到目标页面为止。
4.自然语言工具包:
自然语言工具包(Natural Language Toolkit,NLTK)就是这样一个 Python 库,用于识别和 标记英语文本中各个词的词性(parts of speech)。