1、团队成员简介

左边:马腾跃 右边:陈谋

左上:李剑锋 左下:仉伯龙 右:卢惠明
团队成员及博客:
李剑锋: Blog: http://www.cnblogs.com/Power-Byte/
陈谋: Blog: http://www.cnblogs.com/13061176Terry/
马腾跃: Blog: http://www.cnblogs.com/summerMTY/
卢惠民: Blog: http://www.cnblogs.com/lhm924/
仉伯龙: Blog: http://www.cnblogs.com/zhangbolong/
2、软件工程介绍
项目目标:
- 在线问答网站中散落着许多有价值的知识和有借鉴意义的经验,然而对于一个不精通于信息检索的人来说要寻找这些有价值的信息往往要耗费大量时间,甚至根本不能找到,故而本软件在此需求的基础上进行开发,以满足用户对于信息检索,信息筛选,信息翻译,信息可视化等方面的需求。
预期的典型用户:
软件的用户方一方面是学霸在线教学问答系统后台的开发人员,开发人员可以通过软件提供的接口来直接对于数据进行处理,开发人员具有专业计算机水平,
软件的用户方另一方面是普通用户,本软件将功能性的模块进行集成与封装并且提供UI接口服务于普通用户对于信息检索,信息筛选,信息翻译,信息可视化等方面的需求。
预期的功能描述:
软件产品功能主要包括定义在线教学问答网站的内容结构,能够从爬到的内容中抽取元数据并将其纳入到既定的组织结构中,在用户查询时能够给予快速准确的响应,并且支持标签,翻译的功能。
- 在线问答网站的内容结构定义;
主要是对在线问答网站的组织进行格式化提取,(包括网站的用户提出的问题,以及其他用户给出的相应的解决方式),然后按照既定的格式整理并且存储到数据库中。
- 增量式的数据处理;
对于后续爬取得到的最新数据,能够按照定义好的内容结构准确地合并到已有的内容中。
- 文本标签;
对于用户提出的问题所属的类别使用标签进行分类。
- 文本关键词提取;
对于问题中所涉及的主要内容以及术语进行分类提取。
- 文本内容翻译;
满足基于不同语言背景的用户搜集检索资料的需求。
- 用户界面与用户进行交互。
满足界面友好的要求,对于用户来说易于上手,易于使用。
- 给在线组和app手机客户端组上传数据
当有需求的时候,我们会给在线组上传一定量的数据,由于给网站上传大量数据的时候会给网站服务器增加负担,有时网站拒绝访问,有时网站崩溃,所以每次我们只上传一定量的数据,从而让上传数据变得稳定。
预期用户
- 由于我们的应用是给学霸客户端和在线系统使用,所以的目标就是给他们定时提供数据。
3、产品需求及反馈
|
需求 |
反馈 |
| 1.上传数据(在线组、手机app组) |
1.定义Json规格,定义上传文件类型 2.通过Json向Solr这个搜索引擎后台上传数据 |
| 2.视频文件(在线组) |
1.向爬虫组提出要求,并且定时进行交流。 2.效果不尽如人意 |
| 3.问答(在线组、手机app组) |
1.刚开始用Stackoverflow的数据进行测试上传 2.实现搜搜问问、百度知道、德问、cnblogs数据处理 |
| 4.对标签进行定义(在线组) |
1.通过stackoverflow的api对相应的标签进行定义。 2.其他标签从文章中抽取。 |
|
5.标签、关键词结果分析(老师) |
1.与学长的进行了相应的对比,从F值来看,我们的测试效果比学长高17.8个百分点左右 |
|
6.两个后端(老师) |
1.将处理数据和上传数据分成两部分,不同用户可以登陆不同后端进行相应的操作。 |
用户评价:
| 在线组 | 数据能够用,但是上传的数据太少 |
| app组 | 数据现在能用的太少 |
4、预期目标以及实际情况
| 预期目标 |
1.处理数量 60000条 上传数量8000条 2.能够处理pdf、ppt、视频、doc 3.问答网站:搜搜问问、百度知道、德问、cnblogs、stackoverflow、知乎 |
| 实际情况 |
1.实际处理数量 55308条 上传数量240条 2.实际能处理的文件pdf、ppt、小部分视频 3.实际问答网站:搜搜问问、百度知道、德问、cnblogs、stackoverflow |
由于后期时间原因,我们与在线组和app组的交流比较少,导致我们在Json格式定义、测试方面比较缓慢;
视频部分能够处理是因为我们获得的文件不都是特别好,有些是因为视频的相关文本数据太少,所以没法给其
添加标签、关键字等重要搜索关键字。
5、分工协作

我觉得一个PM在担当总的设计、构建是不太好的,我真心的认为两个规划能力好的同学共同担当效果会更好。
因为我在统筹规划的同时真心地觉得自身能力的不足,无法完美地担任这个职责,所以我觉得至少有一个人监督会更好。
6、平衡 时间/质量/资源
| 时间 |
|
||||||||||||||||||||||||||||||||||||||||||
| 质量 | 进行了单元测试 | ||||||||||||||||||||||||||||||||||||||||||
| 资源 | 我们人力资源、物力资源都比较充足 |
7、软件质量

对每一个功能都进行了单元测试,虽然有些测试并非完全覆盖,但是总体来说我们的功能比较完善,而且bug比较少
8、M2阶段的实际进展

9、团队成员在M2的角色和具体贡献
|
名字 |
角色 |
具体的, 可衡量的, 可验证的贡献 |
得分 |
|
陈谋 |
PM & Dev |
写了10篇博客,多次和爬虫组、客户端、在线系统进行沟通,写了 3213行代码 |
90 |
|
李剑锋 |
Dev & Test |
写了823行代码, 200行注释, 1篇博客 |
60 |
|
卢惠明 |
Dev & Test |
完成关键词抽取,写了495行代码,并完成相应的测试,2篇博客 |
40 |
|
仉伯龙 |
Dev & Test |
测试了关键词抽取代码,写了235行代码,测试其结果等 |
37 |
|
刘夕霆 |
Dev & Test |
与android客户端组进行沟通,写了276行代码,测试最终版本 |
35 |
|
马腾跃 |
Dev & Test |
写了276行代码,与在线组进行沟通、交流 |
38 |
10、成果展示
- 登陆界面

- 主界面:

- 添加文本:
- 原始数据:
- 去噪:
- 分词:
- 翻译原文本:(API)

- 翻译译文:
- 中英对照:

- 最终结果:

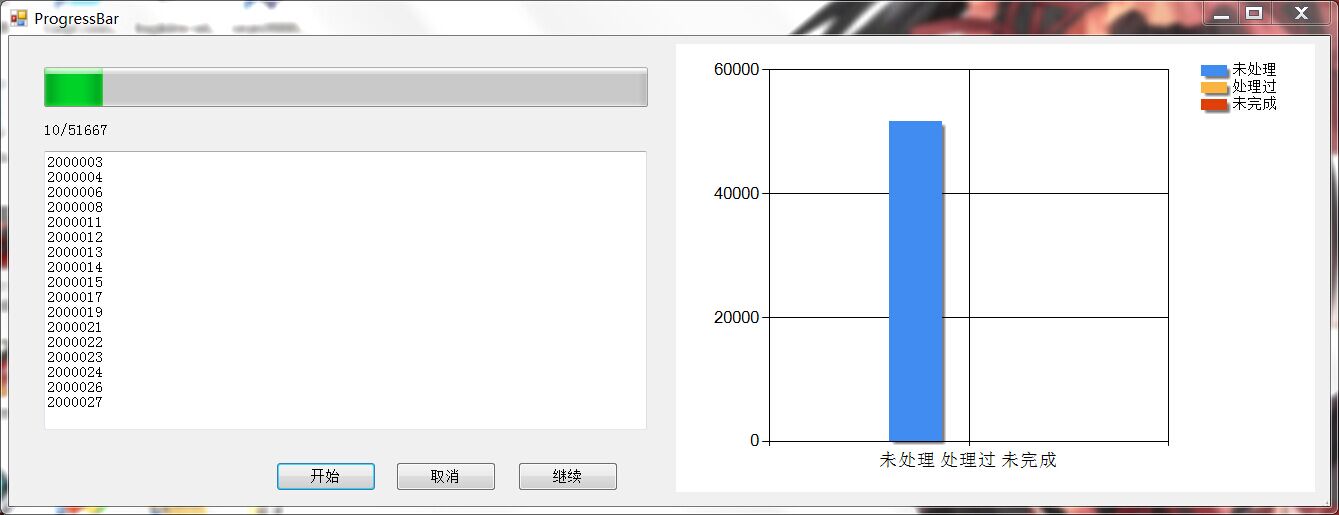
- 上传数据

11、软件Bug
我们的软件管理中遇到的Bug基本上在http://www.cnblogs.com/cheneygroup/p/5117810.html
12、个人总结
- 李剑锋:在Beta阶段我们完成了既定的目标,而且我们通过不断沟通,与另外三组一同构建了完整的框架,从而在工作的开展过程中很是愉快。但是由于时间的原因,我们没能够完成既定的目标,这是我们的遗憾!
- 陈谋:知识和能力都是在不断地学习和锻炼中累积的,我们在Beta阶段这种高压状态下,仍坚持进行各项任务,我们确实付出了,也确实收获了,感谢软工给予我们不断超越自我的。
- 卢惠明:这一阶段我主要负责测试,虽然测试比较枯燥无味,但是确实是一项很有用的技能。
- 刘夕霆:软工,我实在不敢恭维。太累了,希望老师减负!。。。不过,我在这几次团队作业中收获了很多很多,谢谢老师。
- 仉伯龙:我处理不少事情,但是我感觉学的不是特别多。我相信只要我们不断进取,不断探索,我一定能够学到更多,明白更多,最后在理论知识、实践知识方面有了更高的认识。
- 马腾跃:我是这组里唯一的女生,交流起来真的不是特别方便,但是我仍然在尽职尽责地完成PM布置下来的任务,总的来说这阶段我测试任务很多,实质性的开发并不是特别多。