- 团队成员简介:http://www.cnblogs.com/cheneygroup/p/4830994.html
- 团队成员及博客:
李剑锋: Blog: http://www.cnblogs.com/Power-Byte/
陈谋: Blog: http://www.cnblogs.com/13061176Terry/
潘成鼎: Blog: http://www.cnblogs.com/cheney223/
卢惠民: Blog: http://www.cnblogs.com/lhm924/
仉伯龙: Blog: http://www.cnblogs.com/zhangbolong/
- 项目目标: 在线问答网站中散落着许多有价值的知识和有借鉴意义的经验,然而对于一个不精通于信息检索的人来说要寻找这些有价值的信息往往要耗费大量时间,甚至根本不能找到,故而本软件在此需求的基础上进行开发,以满足用户对于信息检索,信息筛选,信息翻译,信息可视化等方面的需求。
- 预期的典型用户:
-
- 软件的用户方一方面是学霸在线教学问答系统后台的开发人员,开发人员可以通过软件提供的接口来直接对于数据进行处理,开发人员具有专业计算机水平,
- 软件的用户方另一方面是普通用户,本软件将功能性的模块进行集成与封装并且提供UI接口服务于普通用户对于信息检索,信息筛选,信息翻译,信息可视化等方面的需求。
- 预期的功能描述:
- 软件产品功能主要包括定义在线教学问答网站的内容结构,能够从爬到的内容中抽取元数据并将其纳入到既定的组织结构中,在用户查询时能够给予快速准确的响应,并且支持标签,翻译的功能。
- 在线问答网站的内容结构定义;
主要是对在线问答网站的组织进行格式化提取,(包括网站的用户提出的问题,以及其他用户给出的相应的解决方式),然后按照既定的格式整理并且存储到数据库中。
- 增量式的数据处理;
对于后续爬取得到的最新数据,能够按照定义好的内容结构准确地合并到已有的内容中。
- 文本标签;
对于用户提出的问题所属的类别使用标签进行分类。
- 文本关键词提取;
对于问题中所涉及的主要内容以及术语进行分类提取。
- 文本内容翻译;
满足基于不同语言背景的用户搜集检索资料的需求。
- 用户界面与用户进行交互。
满足界面友好的要求,对于用户来说易于上手,易于使用。
- 软件产品功能主要包括定义在线教学问答网站的内容结构,能够从爬到的内容中抽取元数据并将其纳入到既定的组织结构中,在用户查询时能够给予快速准确的响应,并且支持标签,翻译的功能。
- 预期用户数量
- 由于我们的应用是给学霸客户端和在线系统使用,所以我们现阶段是没有多少用户的。主要在、是对这两大用户提供支持。
- 项目实现历程
- 团队成员在M1 的角色和具体贡献:
|
名字 |
角色 |
具体的, 可衡量的, 可验证的贡献 |
|
李剑锋 |
PM |
写了6篇博客,多次和爬虫组、客户端、在线系统进行沟通,写了 800行代码 |
|
陈谋 |
Dev |
写了3000行代码, 200行注释, 3篇博客 |
|
卢惠明 |
Dev |
完成关键词抽取,写了1000行代码,并完成相应的测试,2篇博客 |
|
仉伯龙 |
Test |
测试了关键词抽取代码,测试分词等 |
|
刘夕霆 |
Test |
完成问答系统的设计,测试最终版本 |
|
潘成鼎 |
Test |
完成早期的数据库设计 |
- 成果展示
- 主界面:

- 添加文本:
- 原始数据:
- 去噪:
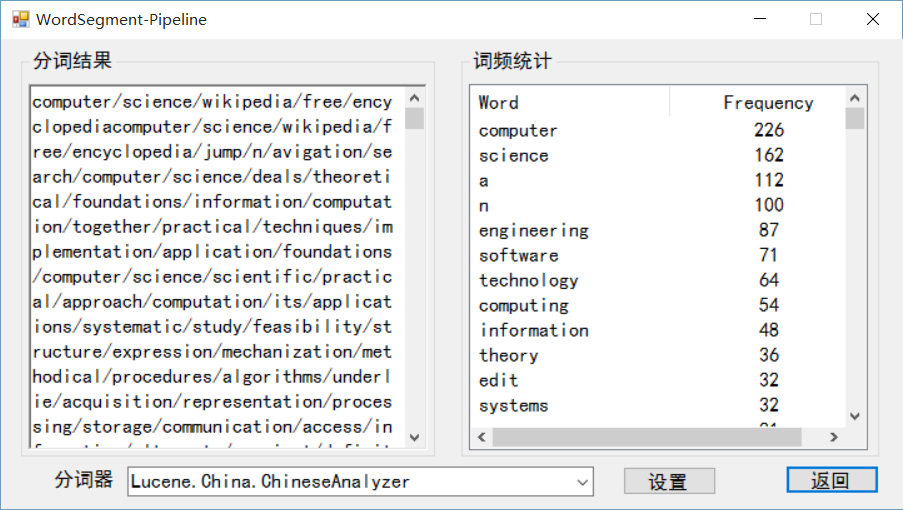
- 分词:
- 翻译原文本:(API)

- 翻译译文:
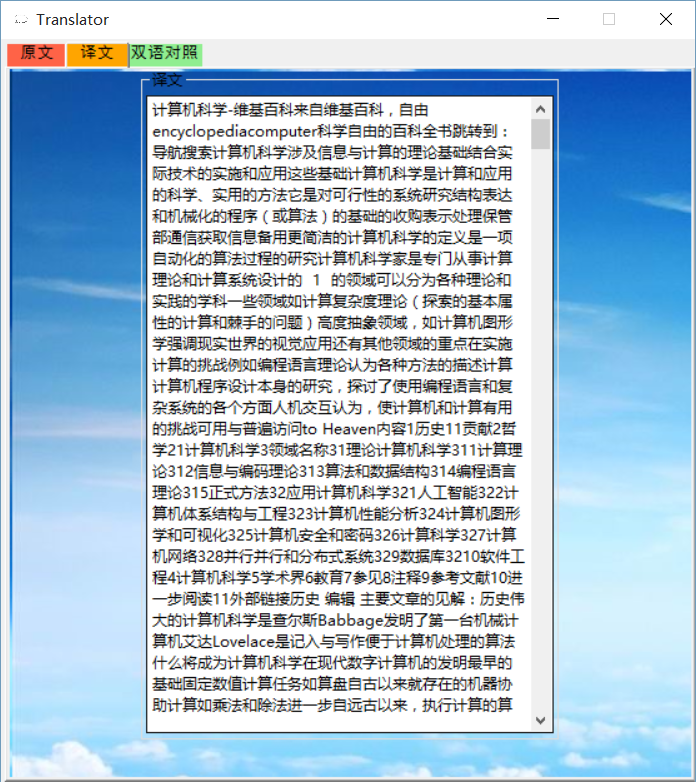
- 中英对照:

- 最终结果:

- 特色功能:
- 首先,分词运用了TF-IDF方式。为了提高我们的关键词抽取的准确度,我们采用了TF-IDF的方式进行了关键词的抽取;
- 其次,分词器有的多个选择,为了让用户选择最佳的分词器,我们给用户提供了多个可用的分词器;
- 第三,完成文本翻译功能,为了让用户能够方便的进行数据的阅读,我们用百度翻译api进行文本翻译;
- 第四,做到了功能与界面的松耦合,关键功能从界面代码中分离出来。
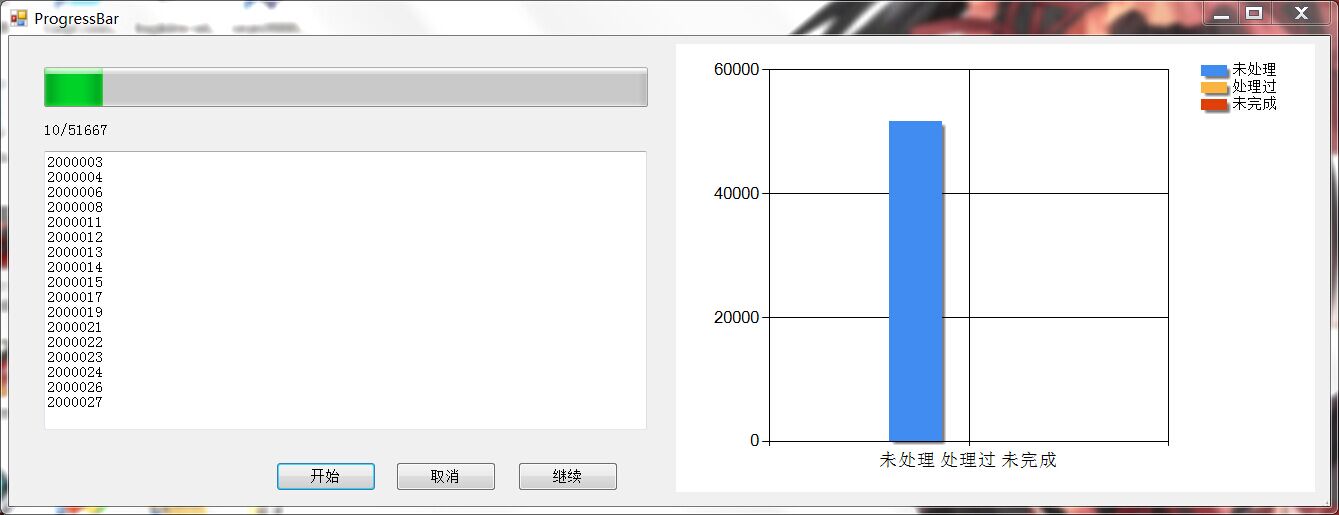
- 第五,数据处理进度可以实时追踪,跟踪进度如下图:
- 软件Bug:
- 之前的软件的一个缺点是代码冗余度较大,功能代码和界面耦合较为紧密(主界面代码长度为1000+)在本软件中将主要功能与界面分离出来,做到松耦合。
| 代码冗余 | 两个getTagNo函数、getWebpageNo函数分别在MainWindow类和InputNewData类中定义了 |
| 代码冗余 | 多个process函数(processpdf和 process函数类似;baiduzhidaoprocess、stackoverflowprocess、cnblogsprocess、sosowenwenprocess、dewenprocess基本一样;判断函数baiduzhidao、stackoverflow、sosowenwen、cnblogs、dewen完全可以合并)非常类似,为此我们进行了合并 |
-
- 现阶段的追踪进度方面存在一些小问题。
- 一旦数据库关闭,我们的程序存在不能继续访问的问题。
- 数据加载进度慢,没能够快速处理文本文件。
个人总结:
- 李剑锋:在Alpha阶段我们完成了既定的目标,但是可能对于团队中所遇到的问题难度估计不够,遇到一个个看似简单的问题往往需要耗费相当多的时间,以这一方面在Beta需要作出更大的改变。
- 陈谋:这一次我们组的团队协作方面做得不够好,主要开发是由我来做,所以收获也是最大的。首先我对于对于工程的把握更加明确。学会了数据的与处理的工作,当然也在阅读代码的过程中明确翻译、关键词抽取等数据处理方面的知识。
- 卢惠明:完成了关键词抽取之后,不敢说我对于数据处理的一个重要方面有了没明确认识,但是至少可以说我已经可以在学校智能所做些事情了。
- 刘夕霆:对于网站的一些知识,我已经有了较高的认识。特别是对于问答网站的一些处理方面,对于网页规格方面也有了较高的认识。
- 仉伯龙:我处理不少事情,但是我感觉学的不是特别多。我相信只要我们不断进取,不断探索,我一定能够学到更多,明白更多,最后在理论知识、实践知识方面有了更高的认识。
- 潘成鼎:我由于中途有些事没能够参与到系统的开发,所以我只能说声抱歉。如果下阶段我还能在这一组,我一定要为团队做出必要的贡献。
我们在这阶段开始时对于数据处理的认识不是特别明确,所以开始时候我们没有进行良好的技术分工。进度较为缓慢。所以在Beta阶段,将由陈谋作为PM,对团队任务进行细分,对需求进行明确,对架构进行规划。最后交给每一位组员明确的任务,从而让每一个组员有较高的提升。