最终爬虫一组打算用SQL Server,我们组为了更好地与他们进行连接处理,也选择了SQL Server服务器的处理。还有我们在数据处理方面对学长的代码进行了优化,尽量让数据处理速度更快,同时我们会让视图之间是一种弱连接的方式,尽量让视图更加完整,用户体验更加完善。
这两天时间完成的任务:
- Tag的去重,建立标签。
- 完成数据库的连接,完成代码逻辑中查询,插入等操作。
- 搭建界面,并设置相应的跳转
- 对关键词算法进行调整,并实现
- 完成说明文档的书写。
“纸上得知终觉浅,绝知此事要躬行”,正是在一遍遍的代码阅读和调试之中,正是在不断参考他人优秀博客的过程中,我们懂得了很多。为了尽可能巩固并加深对知识点的认识,我们组一直要求每一位学员要把读到的知识用简单的样例实现。也正是在这种严格要求之下,我们的相关能力有了较大的提升。
但是,我们还是遇到了很多无法解决的困难!询问学长,询问大牛,便成了我们的家常便饭。在这种浓烈的学习氛围之中,我们组每一位学员都收获了知识,增进了友谊。
明天的任务:
| Members | Tomorrow's Task |
|---|---|
| 陈谋 | 完成关键词抽取的代码检验 |
| 李剑锋 | 进行已完成的任务的单元测试 |
| 潘成鼎 | 完成E-R模型的数据库建设 |
| 卢惠明 | Tagging |
| 刘夕霆 | 搭建相应的网页 |
| 仉伯龙 | 对已完成的任务进行单元测试 |
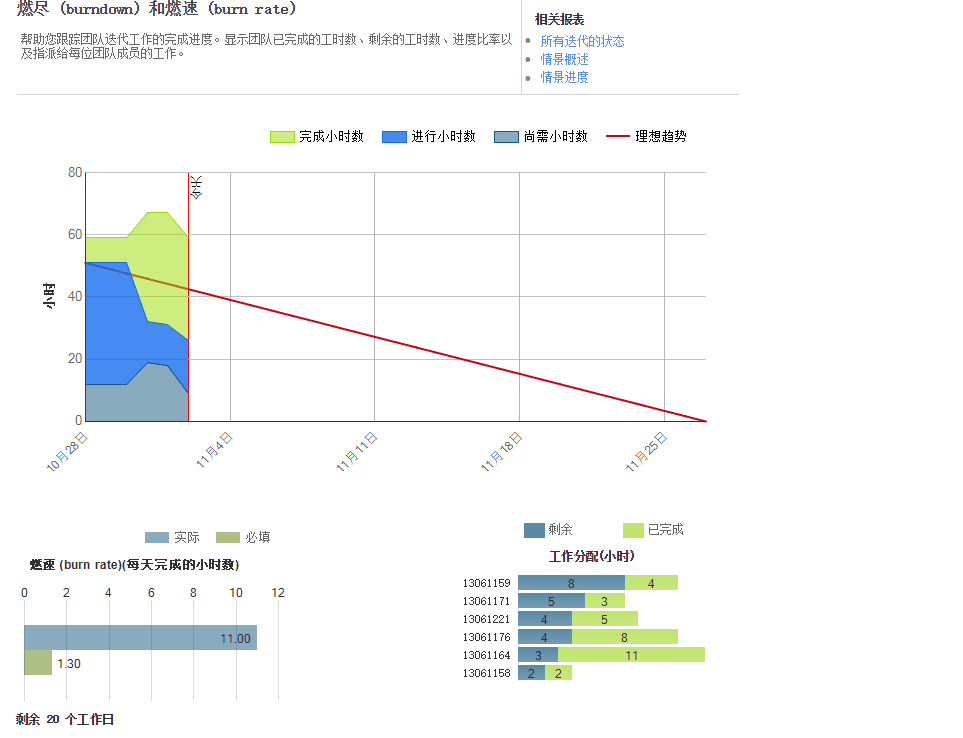
我们的进度情况(燃尽图):