写出不必要的主键重复的数据说明你对业务或者SQL关联的理解有问题
SQL最重要的一块语法就是各种关联
inner join 和 left join 是最常用的
如果没能深入理解SQL查询 就会写出一些有重复的关联查询
1 select 债券代码,交易市场 ,count(*) -- 查重主键 2 from 3 ( 4 -- 加入需要查重的代码 5 )a 6 group by 债券代码,交易市场 7 having count(*)>1
用以上这段代码可以进行主键查重
我就联系实际简单说明一下
首先提出一个问题 :
Q: 如果select * from A inner join B on A.a=B.b
A表的数据条数是n
B表的数据条数是m
假定n<m
那么结果集的数据条数范围是多少 ?
一般来说 由于是inner join 结果应该小于等于n
把inner join 比作是找对象 A表和B表的主键找对象 找到了对象留下 放在结果集中 没找到的走开
那结果条数应该不会大于n才对
但事实呢
结果条数可以大于n
比如 如果A表的a列 在 B表的b列找到了多个对象 结果会是怎样呢 ?
1 select * from 2 ( 3 select a=1,c=1 4 )a 5 inner join 6 ( 7 select b=1,c=2 8 union all 9 select b=1,c=3 10 )b on a.a=b.b
执行一下上面的SQL语句 结果是会返回2条数据
inner join 换成 left join 结果是一样的
返回的最大记录数是n*m
理解这个问题对于深入理解SQL关联查询至关重要

-------------------------
我们可以简单的这样理解 SQL关联像是找对象 , 而每个表(A和B)中的字段都是结果集的一个标签 , 也就是列 columns
你可以在最外面的select语句后面对这些标签字段进行各种处理 比如case when 然后返回新的标签列 用 as 命名
-----------------------------------补充一个很重要的技巧
如果你理解了上面的结论 那么你写多表关联的话就很轻松了
但是 有一个问题
1 drop table if exists #a 2 select * into #a 3 from 4 ( 5 select symbol='001',exchange='sh',rn=1 6 union all 7 select symbol='001',exchange='sz',rn=2 8 ) a 9 10 select * from #a 11 12 select symbol,exchange1=max(case when rn=1 then exchange else null end),exchange2=max(case when rn=2 then exchange else null end) 13 from #a group by symbol 14 15 drop table #a
主键是symbol
单独用symbol字段关联#a会关联出两条数据 即为主键重复 不可取
但这两条数据我都想要 该怎么处理
那就改写成第二个查询 可以做到把两条数据合并成一条 而且能取出所有想要的数据
如果不进行这样的转换 就需要多left join 一个表 每个表里面分别限制where条件rn=1 和 rn=2
这里的聚合函数是max还是min,avg其实无所谓 反正都是忽略null
else null 可以省略 因为case when 默认有这句代码
这个写法大大简化了代码
结果如下图
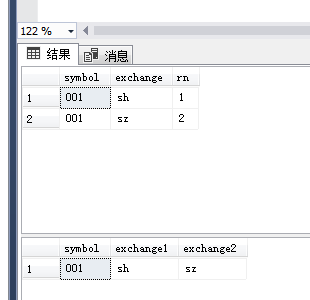
这个技巧可以实现横纵转换 , 很妙
谢谢!