---------------马哥Linux操作系统------------------------
1、运算器、控制器、寄存器(register)是CPU的三大组成部分。
2、North Bridge:负责CPU和RAM(可以看成是主存)各存储cell进行通信的的芯片,他可以关联到CPU和RAM中的存储单位。
32位的CPU可以寻址2^32=4G的cell。一个cell就是一个Byte。
除了RAM之外需要与CPU进行大量和快速的数据交换的还有video card(显卡),显卡的数据可以在显存中缓存,要是没有显存那就缓存在内存中。所以一般来讲,显卡也是连接在北桥上。独立显卡不用去占用体系内存,具有独自的显存,并且技术上领先于集成显卡,可以供给更好的显现作用和运转能力。所以独立显卡性能比较好一些。
video card是一种外部设备。是一种IO设备。高速IO总线,通常叫做PCI总线(连接在南桥),现在又有了PCI-E(连接在北桥),南桥是把慢速总线汇总起来连接到北桥。各种磁盘总线是PCI格式的,像SCSI、IDE等等,由于是PCI是连接上来的,所以速度都是有限的。
任何一个硬件通过总线连接上计算机,必须在开机的时候必须申请一片连续的端口(IO Port)。很可能每次开机注册时候是不一样的。IO Port是用来区别硬件的。
CPU有一个中断控制器(Interrupt Controller)。
上下文切换,是一个进程切换。
3、PAE(Physical Address Extension,物理地址扩展)技术。32位的CPU多了4位寻址总线。
4、解决两个速度不匹配的话,利用缓存可以提高速度。现在很多是用多级缓存。缓存有意义的原因是程序具有局部性。
局部性:控件局部性、时间局部性。
CPU的缓存造价很高,他是多级缓存(三级缓存),越离CPU近,它的速度越快,造价越高,是一种SRAM技术。CPU的价格不但在它的主频上,另外一个在它的缓存上,缓存提高一倍,通常它的价格要提高一倍的。
一级指令缓存(I1)一级数据缓存(D1),二级缓存,三级缓存。一级二级是独有的,三级是共享(可以是多个CPU共享)的。
(转自 http://www.cnblogs.com/henryhappier/archive/2010/08/19/1803415.html)
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。由此可见,在CPU中加入缓存是一种高效的解决方案,这样整个内存储器(缓存+内存)就变成了既有缓存的高速度,又有内存的大容量的存储系统了。缓存对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与缓存间的带宽引起的。
缓存的工作原理是当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存,二级缓存,部分高端CPU还具有三级缓存,每一级缓存中所储存的全部数据都是下一级缓存的一部分,这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。一般来说,每级缓存的命中率大概都在80%左右,也就是说全部数据量的80%都可以在一级缓存中找到,只剩下20%的总数据量才需要从二级缓存、三级缓存或内存中读取,由此可见一级缓存是整个CPU缓存架构中最为重要的部分。
N路关联。
Write through,通写,缓存中的数据一改变就改变主存中的数据。
Write Back,回写,缓存中的数据将要丢弃的时候才改变相应的主存中的数据。
5、DMA:Direct Memory Access,直接内存访问。
DMA是Direct Memory Access的缩写。其意思是“存储器直接访问”。它是指一种高速的数据传输操作,允许在外部设备和存储器之间直接读写数据,即不通过CPU,也不需要CPU干预。整个数据传输操作在一个称为“DMA控制器”的控制下进行的。CPU除了在数据传输开始和结束时作一点处理外,在传输过程中CPU可以进行其它的工作。这样,在大部分时间里,CPU和输入输出都处在并行操作。因此,使整个计算机系统的效率大大提高。
6.BIOS & CMOS
7.内存最低的1M预留给BIOS使用。在下面是给DMA使用,他是将数据放入内存,并中断通知CPU。
8.内存的存储机制。内存的保护机制。
将内存按固定大小单元的划分好,它本来是按照字节来划分的,太小了,分配回收太复杂。存储槽,分好的一个存储槽叫一个页框,每一个页框可以存储一页。
页目录:用来方便从线性地址(逻辑地址)到物理地址的映射。http://book.51cto.com/art/201006/208525.htm
有了上面的机制,我们可以这样理解了:一个进程在面对内存的时候,它就可以认为自己有非常大的存储空间(相比较直接将一个进程的空间映射在内存中的一段线性相连的空间而言,这段相连空间一旦用完就没得用了,该进程面对内存时候自己的存储空间就这么一点)。利用页目录,我们可以将进程的逻辑地址空间(从逻辑地址上看是连续的)映射到物理地址空间(在物理地址上看是不连续的).
一个进程的需要的内存分配是这样的:
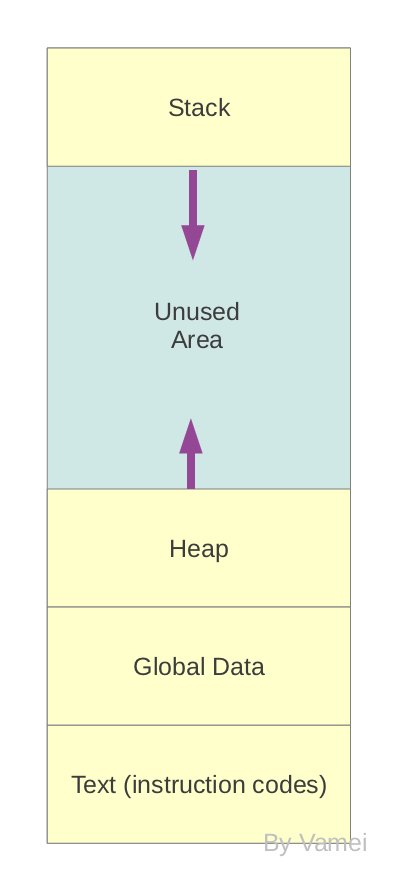
进程在内存中空间分配
图片来自http://www.cnblogs.com/vamei/archive/2012/10/09/2715388.html
页目录还有内存保护作用,防止内存交叉使用。
9.CPU有两种模式:CPU在运行内核的时候,是内核模式;在运行用户进程,是用户模式。区别:用户是不能控制硬件的!这是理解虚拟化的基础。
用户进程需要硬件操作(比如说读取辅存上的文件),那就需要系统调用(Syscall),模式切换(用户进程退出,内核进程退出)。读出来的数据先是存储在内核内存(物理内存),再映射到逻辑地址(交给了进程),内核唤醒用户进程,内核进程退出。
进程队列。
10.在Linux中进程是通过一个链表(双向链表)管理的。每一个进程用一个结构体(进程描述符)来描述的。
创建一个进程,就是创建一个描述符并添加到链表上。
11.进程切换又叫做上下文切换
12.进程类别:
交互式进程(I/O)
批处理进程(CPU)
实时进程(Real-time)
Linux优先级:priority
实时优先级: 1-99,数字越小,优先级越低
静态优先级:100-139,数据越小,优先级越高
实时进程:
SCHED_FIFO:First In First Out
SHCED_RR: Round Robin
SCHED_Other: 用来调度100-139之间的进程
进程优先级的调整(动态优先级、手动调整优先级)
13.Linux进程调度算法(进程是有优先级的):
将进程按优先级进行排队,每一个优先级两个队列(一个是活动队列,一个是过期队列),每次只要扫描活动队列的开头(99-0,100-139)。活动队列没运行完的队列就放到过期队列中,过期队列进程被唤醒,就将过期队列标记为活动队列,活动队列标记为过期队列。
14.进程的生成
每一个进程都有其父进程调用fork()来创建它的子进程。创建一个进程主要是创建它的进程描述符(task_struct),并且要有自己的内存空间(一开始fork的时候子进程和父进程指向同一个地址空间,当COW,Copy On Write,写时复制,的时候才为子进程分配自己的存储空间)等等一切,这都是由内核完成。
这跟Apache的prefork不一样。
15.SMP,对称多处理器。这里的内存是共享的。
NUMA,非一致性内存访问。每一个cpu都有自己的内存,有自己的内存控制器。
16.su——switch user的意思。
17.关于windows和Linux的shell:shell主要分为GUI和CLI(Command Line Interface,命令行界面)。Linux的CLI有很多,最常用的是bash。Linux的GUI主要有三种,GNOME、KDE、Xface。而windows的GUI是镶嵌在内核中的,windows不用GUI就没法工作,而Linux的GUI(Linux的GUI统称为X-Window)跟bash一样都是一个壳(shell),相当于一个程序。
18.雷锋实验室

22.命令的选项中有短选项(跟在-后面,加一个charater)和长选项(跟在--后面,加一个word)。有些选项是可以带参数的(注意,选项的参数和命令的参数是不一样的)


29.hash 显示使用命令以及它的命中次数。
缓存,当速度不行了就用缓存。这儿hash是将使用过的命令存到一个缓存中,这样一个命令被使用过了,下次使用这个命令的时候,就提高了命令执行的速度。总而言之,缓存是提高系统速度的。
30.date:时间管理
31.获取命令的使用帮助
内部命令:
help COMMAND 比如说help cd
外部命令:
COMMAND --help
无论是外部还是内部命令都可以使用man 命令来查看 man COMMAND。一般来说一个命令的使用说明都是压缩存放的。
man命令的章节划分是这样的:1——用户命令(/bin,/usr/bin,/user/local/bin);2——系统调用;3——库用户;4——特殊文件(设备文件);5——文件格式;6——游戏;7——杂项(miscellaneous);8——管理命令(/sbin,/usr/sbin,/user/local/sbin)
32. touch——不单纯是为了创建文件,修改文件时间戳的
stat——display file or filesystem status
file——显示文件的类型
install——copy files and set attributes复制文件和设置属性
install -d DIRCOTRY.. 表示创建目录
33.Nano:Linux下面一个文本编辑器,功能相对比较小的编辑器
34.LFS(Linux From Scratch,从起跑线开始Linux),自己根据这个文档弄好Linux就牛逼啦。
35.命令Conclusion:
目录管理:ls、cd、pwd、mkdir、tree
文件管理:touch、stat、file、rm、cp、mv、nano
时间日期:date、clock、hwclock、cal
文本处理:cat、more(向后翻页)、less(文本分页查看,space空格键下一页,b键上一页,enter回车键下一行)、head(默认前十行)、tail、cut、sort、uniq、grep
36.显示环境变量的值
如echo $PATH
37.执行命令历史中第n条命令 !n
执行上一条命令 !!
执命令历史中最近一个以指定字符串开头的命令 !string
引用上一个命令的最后一个参数 !$ 也可以使用先按下Esc松开然后按下.按钮
38.在linux中给一个命令取别名 alias CMDALIAS=COMMAND [options] [arguments]
在shell中定义的别名仅在当前shell生命中有效,别名的有效范围仅为当前shell进程。
直接输入alias可以查看所有的别名
撤销别名unalias,unalias CMDALIAS
39.命令替换:把命令中某个子命令替换为执行结果的过程
使用$(COMMAND)或者使用反引号(他不是单引号,是Tab键上面的那个键)`COMMAND`
比如 echo "the current dirctionary is $(pwd)"
bash支持的引号:``:反引号,命令替换;"":双引号,弱引用,可以实现变量替换;'':单引号,强引用,不完成变量替换。
40.文件名通配 :*任意长的任意字符 ?任意单个字符 []指定范围内的任意单个字符 [^]指定范围之外的任意一个字符
[:space:]表示所有的空白字符,所以用[[:space:]]就表示一个空格
[:punct:]表示所有标点符号
[:lower:]表示所有小写字母 相当于a-z 所以[a-z]就跟[[:lower:]]是一个意思
[:upper:]大写
[:alpha:]字母,所以[^[:alpha:]]就表示非字母的一个字符
[:digit:]数字
用man 7 glob可以查看上面的东东。
41.加密方法:
对称加密:加密和解密使用同一个密码
公钥加密:每个密码都成对出现,一个为私钥,一个为公钥
单向加密,散列加密,又可以叫成:提取数据特征码,可以用来做数据校验。它是单向的,不可逆的。
42.用户组类别:
私有组:创建用户时,如果没有为其指定所属的组,系统会自动为其创建一个与用户名同名的组
基本组:用户的默认组
附加组,额外组:默认组以外的其他组
43.id命令
print real and effective user and group IDs
finger:查看用户帐号信息
44.useradd
userdel删除用户:
-r 表示删除用户的同时删除用户的家目录。userdel删除用户的时候不会删除用户的额家目录
45.修改用户帐号属性:
usermod:
-u 修改用户名
-g 修改基本组,但必须是事先存在的组
-G 修改附加组,这样会覆盖此前的附加组(-a -G,在原有附加组的基础上增加附加组)
-d 修改家目录,一般与 -m 一起使用
-L 锁定帐号 -U 解锁帐号
46.修改用户注释信息chfn(change finger)
修改密码passwd [USERNAME]
创建组 groupadd
newgrp GROUPNAME以这个身份登录另一个组,要是不想在这个组回到原来的组,就用exit退出就好了
47.# chown 改变文件的属主
-R :修改文件及其内部文件的属主
--reference=/path/to/somefile file,...
chown USERNAME:GRPNAME file,... 可以用chown同时改变文件的属主和属组
# chgrp
-R:也有这种修改内部文件属组的用法
# chmod:修改文件的权限,可以修改三类用户的权限,修改某类用户或者某些类用户的权限,修改某些类的用户某位或者某些位权限
48.正常创建一个用户
新建一个没有家目录的用户openstack;
# useradd -M openstack
复制/etc/skel为/home/openstack;
# cp -r /etc/skel /home/openstack
了解什么是/etc/profile和/etc/skel
改变/home/openstack及其内部文件的属主属组均为openstack;
# chown -R openstack:openstack /home/openstack
49.umask
创建文件666-umask(文件默认不能具有执行权限,如果算的结果中具有执行权限,将其权限加1)
创建目录777-umask
50.站在用户登录的角度老说,shell的类型:
登录式shell:
正常通过某终端登录
su - USERNAME
su -l USERNAME
非登陆式shell:
su USERNAME
图形终端下打开命令窗口
自动执行的shell脚本
51.bash的配置文件:
全局配置,配置文件 /etc/profile, /etc/profile.d/*.sh, /etc/bashrc
个人配置,~/.bash_profile, ~/.bashrc
profile类的文件:设定环境变量,登录时运行的命令或者脚本
bashrc类的文件:设定本地变量,定义命令别名
52.登录式shell如何读取配置文件?
/etc/profile-->/etc/profile.d/*.sh--> ~/.bash_profile-->~/.bashrc-->/etc/bashrc
非登录式shell如何读取配置文件?
~/.bashrc-->/etc/bashrc-->/etc/profile.d/*.sh
53. 标准输入一般是键盘
标准输出和错误输出一般是显示器
I/O重定向:改变了数据的输入或者输出来源
54.脚本在执行的时候会启动一个子shell进程:
命令行中启动的脚本会集成当前shell环境变量
系统自动执行的脚本(非命令行启动)就需要自我定义需要各环境变量
55.变量有:
本地变量,作用域为当前代码段;
局部变量local varlue,作用域为当前代码段;
环境变量export value,作用域为当前shell进程及其子进程。
位置变量$1 $2 $3 $4......
特殊变量$? 用于记录上一条命令执行状态的返回值
56.撤销变量
unset VALUE (其实我们在定义变量的时候是set VARNAME=VALUE,只不过set可以省略)
查看当前shell中变量 set
查看当前shell的环境变量: printenv 或者 env 或者 export
-----------------------------上交教学视频学习------------------------------------
1、多道批处理系统的核心技术
作业管理:作业的现场保护和恢复、处理机管理、存储管理、设备管理、文件系统管理(file system)
2、分时操作系统
技术基础:时钟、中断技术
3、主存-后援存储方式
后援的存储速度是介于主存与硬盘之间的。是分时系统的一个重要的技术。
正在执行的作业的存放在主存上,等待时间片的作业存储在后援上面。
4、时间片的长短很会影响性能
就跟存储块的大小一样。
5、分布式操作系统
它是以计算机网络为基础的计算机系统,包含多台处理机,每一台处理机完成系统中指定的一部分功能。从硬件上讲,它与计算机局域网没有任何区别,关键是软件。
6、多处理操作系统
多处理系统是由多台处理机组成的计算机系统。
7、程序与进程
程序是静态的,进程是一个动态的概念;同一个程序可以被多个进程同时执行,而一个进程也可以包括执行多个程序;程序一般是长期存在的,而进程不但占用存储空间还要专用cpu。
8、在windows下面每一个分区下面都有一个根目录
就是冒号反斜杠( : )
9、在windows中的.bat是一个批处理文件
在批处理文件中有很多的命令,将他们放在一个文件中就是一个批处理文件。现在很多都是将他做成.exe文件了。
widnows是一个单用户多任务的操作系统。unix是一个多用户多任务的系统。
10、操作系统的启动只能靠“自举”。即,自己把自己一步一步导入内存,开始工作。 还记得模电中的自举电路吗
11、死锁
若干个进程由于互相等待已被对方占有的资源而处于一种僵持的状态。资源是独享的而且是不可抢占的。
死锁的预防:资源互斥和资源不可抢夺一般不能改变,所以我们可以“每个进程必须得到其工作所需的全部资源才开始执行或者不占用资源的时候才执行——占有且等待”;“循环等待——在资源分配上采用有序使用法,就是说现在执行的进程使用的资源都是一个顺序”。
12、银行家算法
一个银行在他现在资金的基础上,在保证取款人在取钱的时候都能取到足够的钱,才把一个贷款者需要的钱贷款给贷款人。
银行家算法是典型的避免死锁的算法。
13、死锁解除措施
关键是“诊断”,判断有没有死锁。所以要每隔一段时间就检查并判断所查出来的等待是正常的还是死锁。
方法:资源剥夺法、撤销进程法
14、同步与互斥(相关的概念)
广义同步,保证进程之间的协调一致,不会发生与时间有关的错误,分为互斥和同步。
和时间相关的错误:进程进展速度、处理器切换时机等时间因素导致程序运行结果不确定。为了避免这种错误,需要运用同步机制。
狭义的同步,几个进程合作完成一个任务时,进程间存在时序关系,必须按一定的顺序协调一致的执行特定操作。
互斥,几个进程需要使用同一个共享资源,而这些资源同一时刻只能被一个进程使用。这种状况叫做互斥。
临界资源,就是被抢的不可抢占的资源。
临界区,在进程的程序中涉及到临界资源的程序段。是一段代码。
15、生产者与消费者问题
一个缓冲区,生产者生产东西往缓冲区放,消费者从缓冲区拿了东西消费。
他是一个同步问题,也是一个互斥问题。与时间与顺序有关的问题。这里的缓冲就是临界的资源。
这些问题的解决是靠进程之间的通信机制。
16、进程通信
低级通信,只用一个信号量(只用一个整形变量甚至是一个bit)进行通信
高级通信,进程间传递的信息量比较大(比如通过内存的一个缓冲区设置通过外存上的一个文件)
方法:信号量(低级)
17、信号量:是一个数据结构,它包括一个整型变量(S)和一个与之联系的进程队列。
struct semaphore { int s; pointer_PCB quene; }
s大于0表示有s个资源可以分配,s小于0表示该资源已经被占用完。
quene是一个指针队列,指向需要资源的进程的队列。
信号量的值只能通过P、V操作这两个原语来改变。原语是说,两个操作必须都执行成功,要是有一个没有执行成功则两个操作都取消。好比银行转账似的,两个操作,扣掉一个人的钱,给另一个人加钱,要是有一个操作没有执行成功那么两个操作都要取消。
P操作:s减1;若s>=0该进程继续进行,否则该进程进入等待装填并被加入到s的等待序列。(其实就是问,这个资源我能不能用,s就表示有资源可以分配,得到了这个资源我就执行,没有我就等待)
V操作:s加1;如果s<=0则将等待队列中的第一个进程释放,把他的状态转为就绪;无论s值如何,都要继续执行这个v操作。