DRNet
2021-Arxiv-Dynamic Resolution Network (06.05)
来源: ChenBong 博客园
- Institute:Zhejiang University, Huawei Noah’s Ark Lab
- Author:Mingjian Zhu, Yunhe Wang
- GitHub:/
- Citation:/
Introduction
instance-aware 的动态分辨率网络
在backbone网络之前, 增加一个resolution predictor(Conv+FC) 模块, 输入为原始图片, 输出为识别该图片所需的分辨率, 将该图片resize成所预测的分辨率, 再输入后续的backbone网络
引入resolution predictor会增加计算量, 但减小分辨率可以在backbone网络中减少计算量 (需要满足: 收益>增加的开销)
Motivation

Contribution
Method
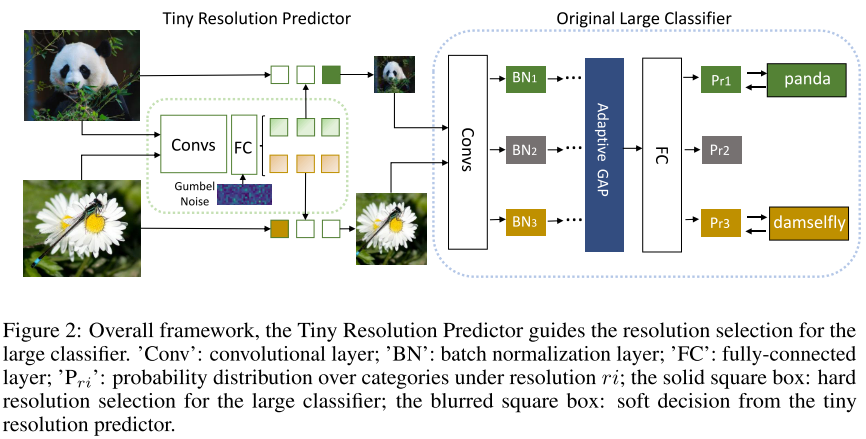
Resolution Predictor
Resolution Predictor (R) 根据输入样本 (X) , 输出一个soft概率向量 (R(X)=p_{r}=left[p_{r_{1}}, p_{r_{2}}, ldots, p_{r_{m}} ight] qquad(1))
根据soft概率向量 (p_r) 采样得到one-hot向量 (h) , 选中对应的 resolution 输入到backbone网络进行训练
采样的过程是不可导的(梯度无法反向传播到predictor的参数上), 采用Gumbel-Softmax trick, 将采样节点分离到计算图之外,使predictor参数也可以接受反向传播:
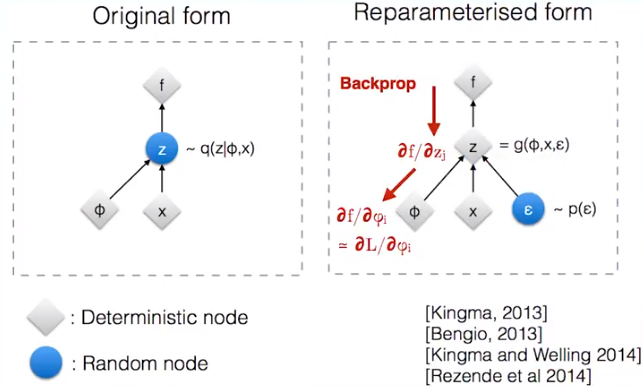
e.g. (zsim N(x, phi^2)) ==> (varepsilon sim N(0,1), z=x+varepsilon cdot phi)
(mathbb{G}(R(X))=mathbb{G}left(p_{r} ight)=h=[h_1, h_2, ..., h_j] qquad (2))
(h_{j}=frac{exp left(log left(pi_{j} ight)+g_{j} ight) / au}{sum_{j=1}^{m} exp left(left(log left(pi_{j} ight)+g_{j} / au ight) ight)} qquad (11)) , 其中 (g_i) 是Gumbel噪声, 服从Gumbel分布; (τ) 为温度系数( ( au) 取很小的值, (h) 即为one-hot向量)
选中对应的分辨率, 输入到后续的backbone model: (hat{X}=sum_{j=1}^{m} h_{j} X_{r_{j}} qquad (4))
Resolution-aware BN
每个分辨率一个私有BN (ps. 训练时应该没有影响, inference时无需校正BN)
Loss
CE Loss
(L_{c e}=mathcal{H}(hat{y}, y) qquad (5))
FLOPs regularization Loss
(F=sum_{j=1}^{m}left(C_{j} cdot h_{j} ight) qquad (6)) , F是某个样本真实的推理FLOPs, (C_j) 是第 (j) 个分辨率对应的FLOPs, (h_j) 是one-hot向量, 一共m种分辨率
(L_{r e g}=max left(0, frac{mathbb{E}(F)-alpha}{C_{max }-C_{min }} ight) qquad (7)) , 其中 (alpha) 是目标FLOPs, 超过目标FLOPs时施加惩罚
Total Loss
(L=L_{c e}+eta L_{r e g} qquad (8)) , 其中 (eta) 是超参数
Experiments
Setting
- dateset
- ImageNet 100
- ImageNet 1k
- resolution
- ResNet: [1.0x, 0.75x, 0.5x] of 224x224
- MobileNetV2: [1.0x, 0.875x, 0.75x] of 224x224
- resolution predictor model
- ResNet
- 4-stage residual network, each stage contains one residual basic block
- input resolution 128×128
- FLOPs=300M
- MobileNet
- 4-stage residual network, each stage contains one inverted residual block
- input resolution 64×64
- FLOPs没讲 &&
- ResNet
- train pre-train backbone model without resolution predictor
- ResNet
- different resolution
- epoch=70, batch size=256, weight decay=1e-4, momentum=0.9
- init lr=0.1, decay by 10 every 20 epoch
- MobileNet V2
- follows the original paper (&& 250 epoch?)
- ResNet
- train resolution predictor model && fine-tune backbone model
- ResNet
- epoch=100
- init lr=0.1, decay by 10 every 30 epoch
- MobileNet V2
- follows the original paper (&& 250 epoch?)
- ResNet
- GPU: V100
ImageNet 100 (Ablation)

表1, 3/4行, 对RA-BN做消融
表2, 对Loss项中的超参 (eta) 和 flops约束 (alpha) 做消融
ImageNet 1k
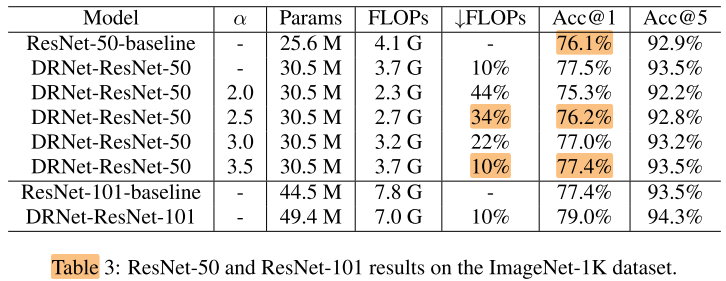
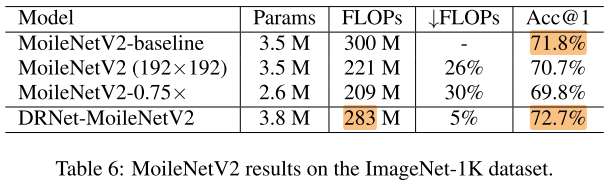
Other
Comparison with filter pruning
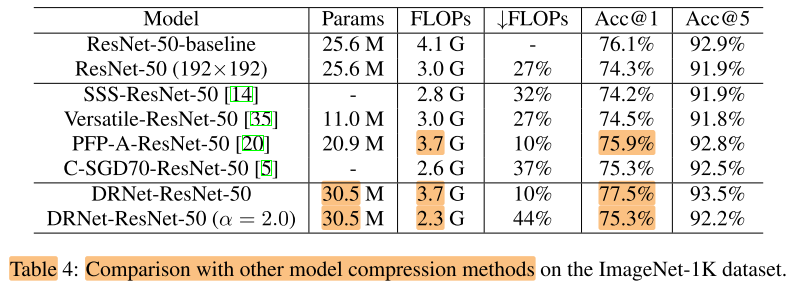
与剪枝的方法正交, 可以与剪枝方法结合(表4 中)
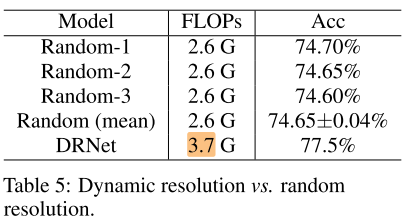
Comparison with random sample
Latency
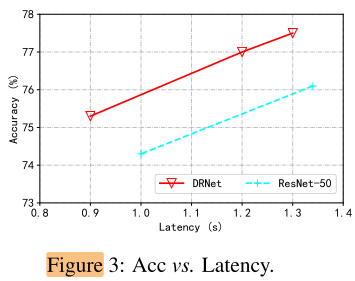
可以实现实际的加速 &&测速?
Visualization

Conclusion
Summary
cons:
- Resolution predictor module
- 设计过于复杂, 计算开销太大(300M FLOPs)
- 不统一(不同backbone使用不同的predictor结构)
- 实际上并不是end-to-end的训练
- latency实验中, 测速的问题
- gumbel softmax只解决了从概率分布p采样onehot p的梯度回传, resize部分是如何将backbone梯度回传到resolution Predictor的?
To Read
Reference
Gumbel-Softmax Trick和Gumbel分布 - initial_h - 博客园 (cnblogs.com)