DyNet
2020-arxiv-DyNet Dynamic Convolution for Accelerating Convolutional Neural Networks
来源: ChenBong 博客园
- Institute:huawei
- Author:Yikang Zhang, Qiang Wang
- GitHub:/
- Citation: 4
Introduction
和Google 的 CondConv,Microsoft 的 Dynamic Convolution 类似的工作,做的都是input-dependent的动态卷积核权重生成。
Google: 19 NIPS CondConv
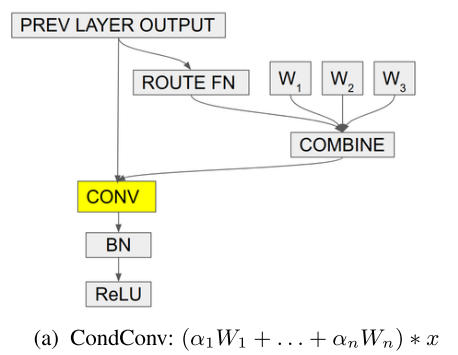
卷积层: (W_i: C_{out} × C_{in} × k × k) ; (hat W: C_{out} × C_{in} × k × k)
卷积层维度变化: (n × C_{out} × C_{in} × k × k ==> C_{out} × C_{in} × k × k)
变换方式:加权求和
加权系数: (α=r(x)=sigmoid(fc(avg pool(x))))
Microsoft: 20 CVPR Dynamic Convolution
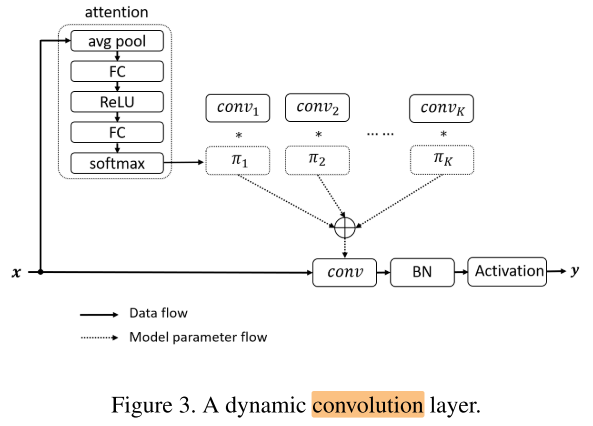
卷积层: (conv_i: C_{out} × C_{in} × k × k) ; (hat {conv}: C_{out} × C_{in} × k × k)
卷积层维度变化: (n × C_{out} × C_{in} × k × k ==> C_{out} × C_{in} × k × k)
变换方式:加权求和
加权系数: (pi=softmax(fc(relu(fc(avgpool(x))))))
Huawei: 20 DyNet
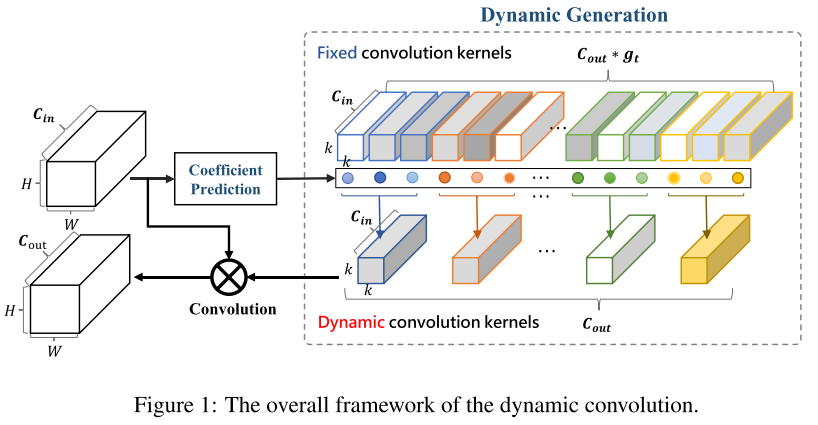
卷积层维度变化:: ((g_t × C_{out}) × C_{in} × k × k ==> (C_{out}) × C_{in} × k × k)
单个卷积核维度变化:: ((g_t) × C_{in} × k × k ==> (1) × C_{in} × k × k)
变换方式:加权求和
加权系数: (eta_t=sigmoid(fc(avg pool(x))))
区别:
- DyNet 从多套权重生成1套权重时,进行了分组;降低权重加权求和时的计算量( (widetilde{w}_{t}=sum_{i=1}^{g_{t}} eta_{t}^{i} cdot w_{t}^{i}) ,类似分组卷积降低计算量的原理)
- CondConv 和 Dynamic Convolution 都是一个layer计算一次加权系数,DyNet是一个block计算一次加权系数;降低计算加权系数时的 计算量(fc) 和 参数量(fc)
Motivation
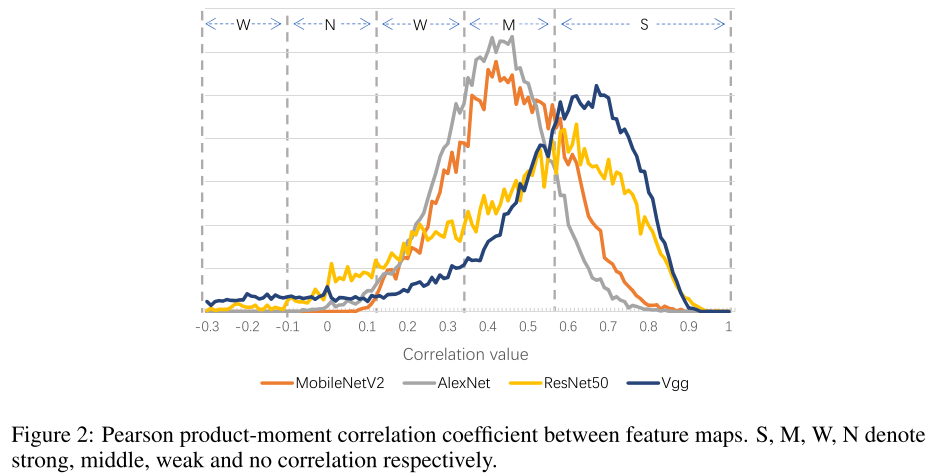
- 经典网络中卷积核之间存在很高的相关性,即卷积核存在冗余的现象
- 剪枝无法完全去除这些冗余性,是由于网络需要学习噪声无关的特征(例如对于人脸识别来说,光照,背景等就是噪声特征),需要多个相似的卷积核来协同提取这些噪声无关的特征 &&,因此fine-tune后冗余性会重新回来,称为内在的/固有的冗余性
- 发现通过对固定的卷积核,基于输入做线性组合,可以无需多个相似的卷积核协同,就可以提取噪声无关的特征 &&
Contribution
Method
Coefficient prediction module
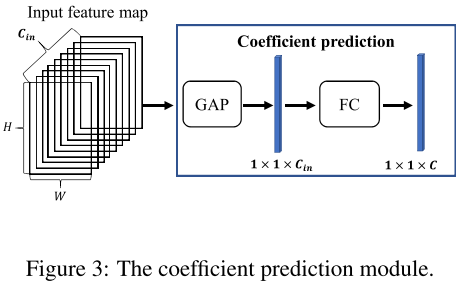
Training algorithm
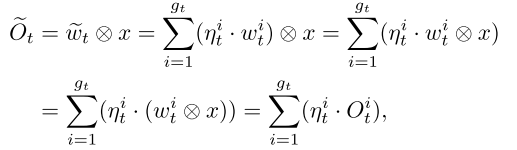
按照权重生成的原理,应该对每个样本做权重生成再做卷积,但这样无法做batch_size>1的训练,因为每个样本所对应的卷积权重都不同;
实际上训练过程中是一个batch先做卷积,再对输出做加权求和。
Experiments
ImageNet
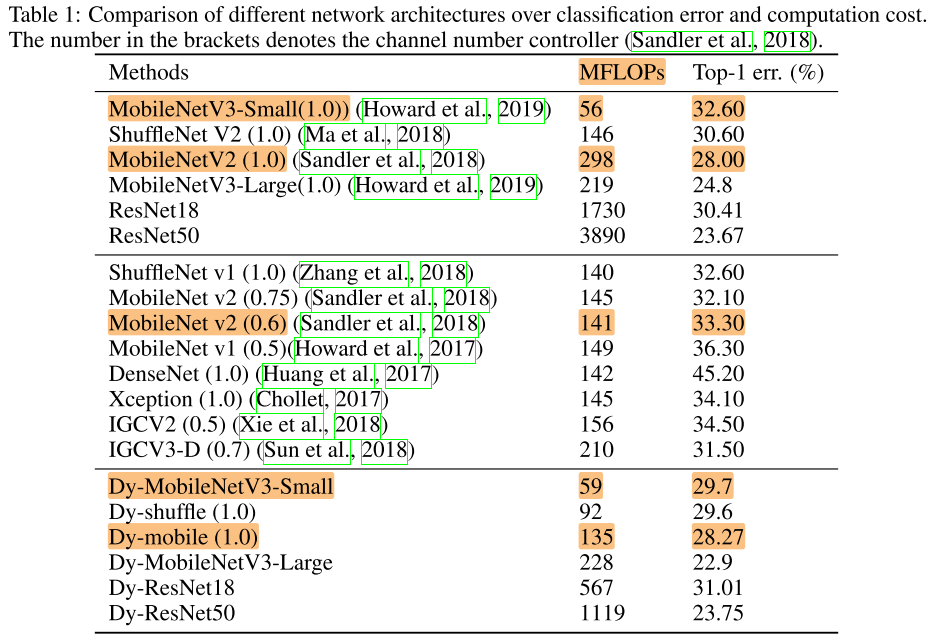
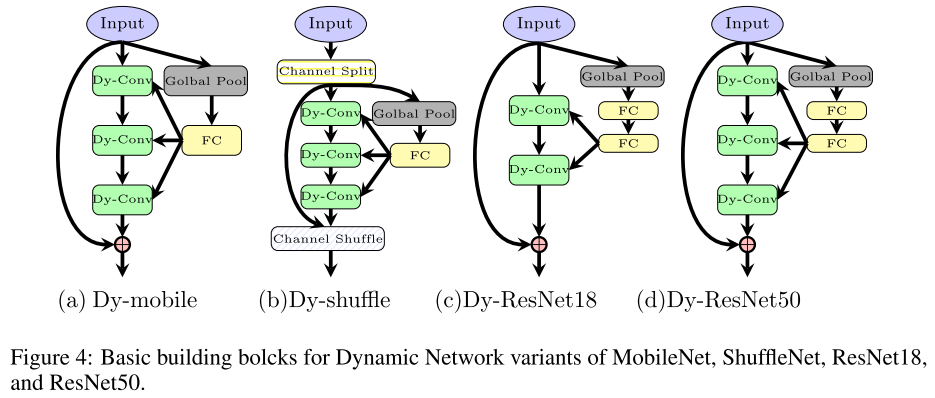
Dy-MobileNetV3 和 MobileNetV3 的实际推理宽度相同
Dy-mobile 的实际推理宽度 < MobileNetV3 的实际推理宽度
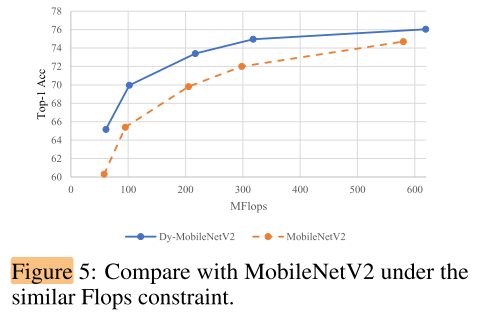
Analysis
相关性
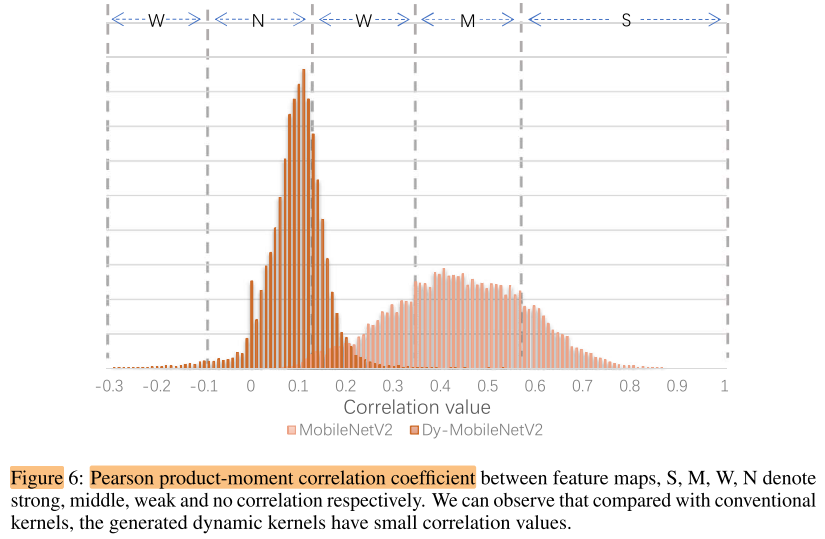
DyNet的输出相关性降低
分辨率与加速比
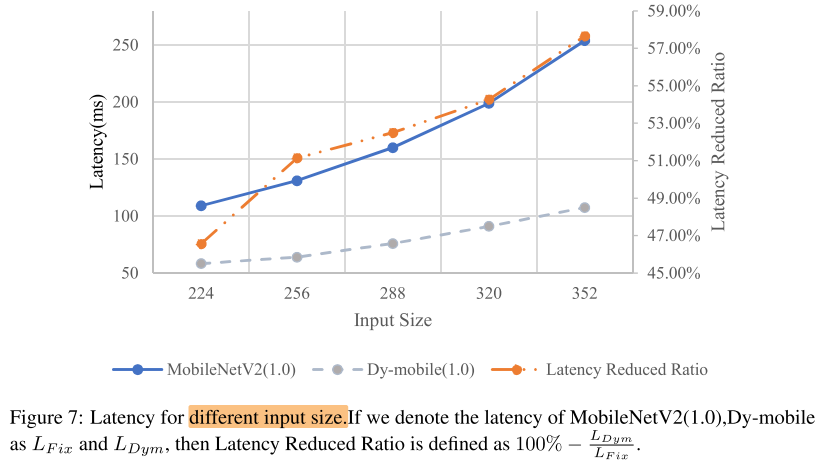
作者认为,由于生成权重的过程(计算量新增的部分avgpool,fc)与输入分辨率是无关的,因此分辨率越大,加速效果越好;
实际上忽略生成权重的部分,Dy-mobile是一个比MobileNetV2更窄的网络,事实上是窄网络和宽网络在不同分辨率下加速比的对比(多出来的计算量 avgpool,fc 的占比在大分辨率推理中占比减小,使得加速比上升)
Ablation Study
固定网络与动态网络
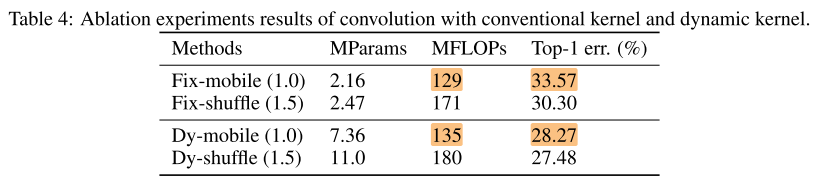
Fix-mobile 是和 Dy-mobile(实际推理)宽度相同的固定网络,想说明相同实际推理宽度下,动态网络比静态网络性能好;但实际上Dy-mobile的参数量是Fix-mobile的g=6倍
gruop size(g)
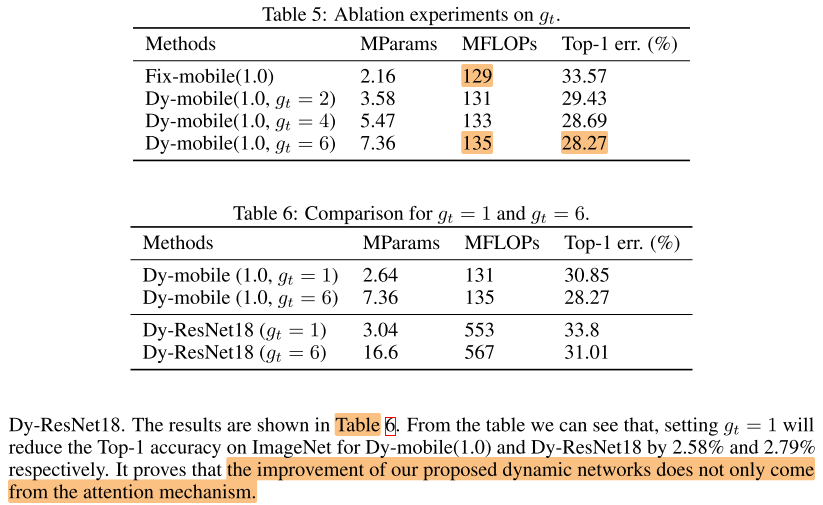
- g=6效果好
- g=1相对于做attention,因此g=1也是有提点的效果的,g=6比g=1还有提点,说明效果不完全来自于attention
Conclusion
Summary
To Read
Reference
2019-NIPS-CondConv: Conditionally Parameterized Convolutions for Efficient Inference: https://www.cnblogs.com/chenbong/p/14392503.html
2020-CVPR-Dynamic Convolution Attention over Convolution Kernels: https://www.cnblogs.com/chenbong/p/14476760.html
https://zhuanlan.zhihu.com/p/139933466
https://blog.csdn.net/kingsleyluoxin/article/details/105702418