CafeNet
2021-ICLR-Locally Free Weight Sharing for Network Width Search
来源:ChenBong 博客园
- Institute:University of Sydney,SenseTime,THU
- Author:Xiu Su,Shan You,Chen Qian,Chang Xu
- GitHub:/
- Citation:2
Introduction
基于超网训练的网络通道宽度搜索;确定每层宽度后,不是 fix-pattern(固定选择 left n 个通道),而是local-free(一部分固定选择,一部分自由选择):

Motivation
- 之前的超网训练都是 fix-pattern(取left n个通道),会降低超网对子网的评估性能
Contribution
- 超网训练在选取子网方式上的扩展,将 fix-pattern 扩展为 free-pattern
- 没有增加太多复杂度
Method
训练超网
考虑第 (i) 维(e.g. 第i层的宽度),fix-pattern 只需要宽度 (c_i) 就可以确定该层的结构。
local-free pattern 分为2部分(free+fix):
- free: (I_f(c) ⊂ [c − r : c + r]) , (|I_f(c)|=r+1) ,其中 (r) 是 free 部分允许的 offset;
- fix:除了free的部分,剩下的就是fix的部分: (I_b(c) = [0 : c_b]) ,其中 (c_b = max(c − r − 1, 0))
搜索子网
- 进化算法 CafeNet-E
- 随机 CafeNet-R
Experiments
ImageNet
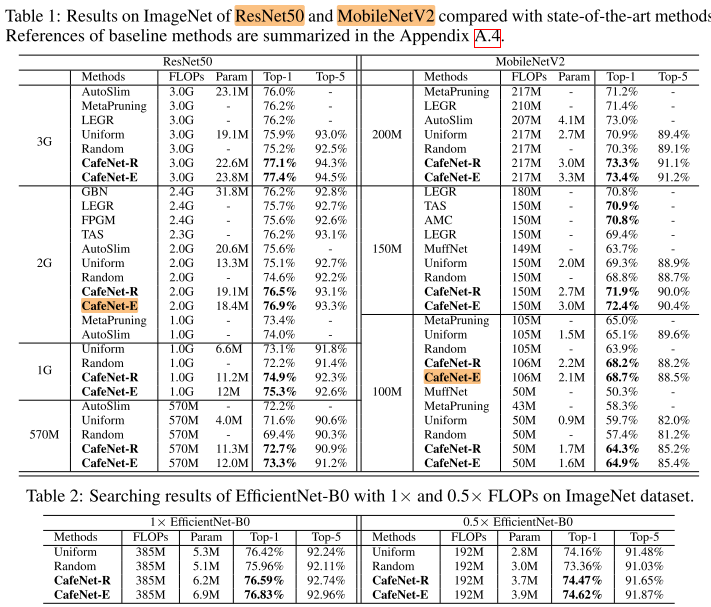
CIFAR10
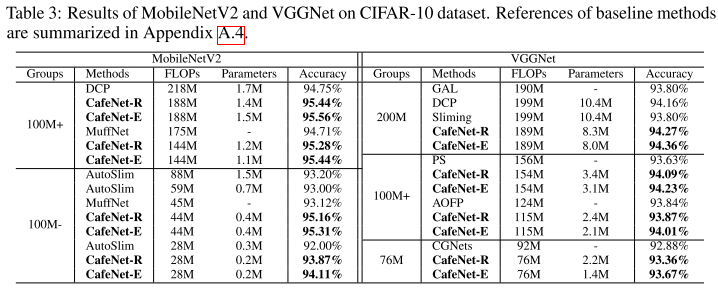
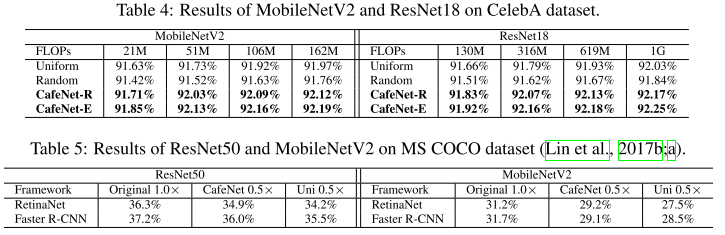
Other
Ablation
offset r

作者认为 r 增大带来采样空间的增大,进而导致训练时间增加(只有在 要保证每个子网都能得到相同程度的训练的前提下,超网训练时间才会增加,否则训练时间应该是可以手动设置成相同的)
然而 r 增大虽然导致子网的采样空间增大,但不意味着训练时间的增加,感觉应该在同样的训练时间下,对不同r(0-3)的超网进行训练,并在相同的搜索时间下对比子网 rank 的相关性;如果在不增加超网训练/子网搜索时间的情况下,使用r>=1还可以提高 rank 的相关性,才说明本方法的有效性。
Training and Searching Epoch
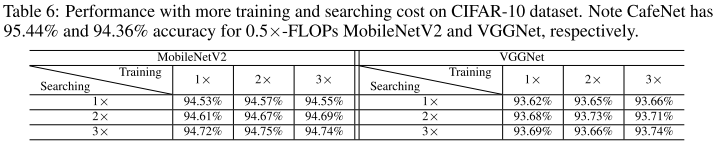
表格里比较的是 fix-pattern 增加训练时间和搜索时间的 top-1 性能,想说明本文的方法不是依靠增加训练/搜索时间来提高性能的。
但本文的 motivation 是通过增大子网空间,来提高超网的预测准确性,即 rank 的相关性,应该直接比较增加训练/搜索时间后的 rank 相关性才对,而不是比较搜索到的子网 top-1。
Conclusion
Summary
pros:
- 想法简洁
cons:
- motivation 是提高子网的采样空间,进而提高超网的预测能力(即提高子网 rank 的相关性),但全文都没有对 rank 相关性进行分析,而只对比了 top-1 的性能差异,但 top-1 更高不能说明超网的预测能力(子网 rank 相关性)更高
- 看到最后还是不清楚 left fix+right free 的pattern到底能不能提高超网的预测能力
- 方法很简单,但文章写得很长(附录11页),附录里讨论的感觉是一些不太重要的细节:缩写,更详细的实验结果,网络结构可视化等,有凑篇幅之嫌