FSC
2020-CVPR-Fast Sparse ConvNets
来源:ChenBong 博客园
- Institute:DeepMind,Google
- Author:Erich Elsen,Marat Dukhan,Trevor Gale
- GitHub:https://github.com/google/XNNPACK 600+
- Citation:14
Introduction
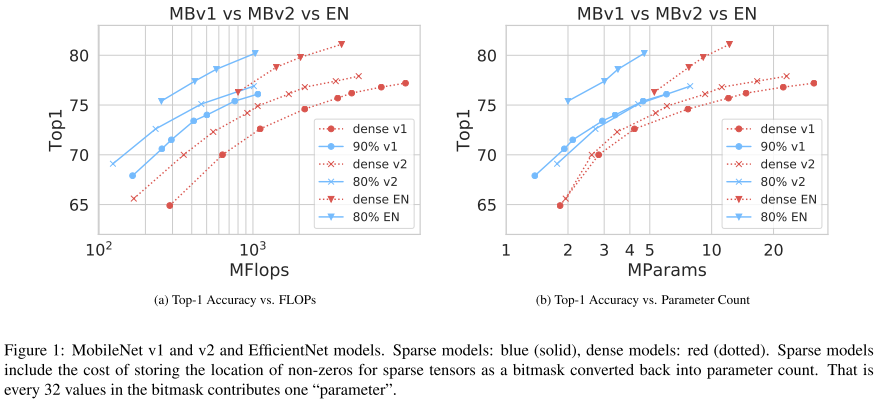
在FLOPs相同的情况下,稀疏卷积网络性能要高于密集卷积网络,大约相当于一代的改进(MobileNet V1 => MobileNet V2 => EfficientNet)。通过定制稀疏卷积算法,实现了对稀疏权重的卷积加速。推理时间加速1.3-2.4x,参数压缩率2x,FLOPs压缩率3x。
Motivation
CNN的效率一般由以下几个 metrics 定义:
- 实际加速比(interface time)
- 理论加速比(FLOPs)
- 模型大小(Params)
以上三者不是独立的,FLOPs 和 Params 对 实际加速比 的影响是一个复杂且与硬件高度相关的问题
Efficient CNN的方法有以下几种:
- 手工设计新的卷积结构,如 dw conv,这也可以看成一种稀疏化,是对 std conv 手工设计的一种稀疏化
- 剪枝,分为结构化剪枝和权重剪枝,其中一般认为权重剪枝会带来卷积核权重的稀疏化,需要定制的硬件才能实现加速,因此大多数工作聚焦于结构化剪枝
我们想纠正“稀疏化卷积核不能带来实际加速”的偏见,通过使用我们提出的稀疏卷积算法来替换原始的密集卷积算法,可以在稀疏卷积上实现实际的加速
Contribution
Method
剪枝算法
To prune, or not to prune: Exploring the efficacy of pruning for model compression.
在MobileNet Family model中,dw卷积只占用很小的FLOPs,Params和推理时间,在MBv1中 dw FLOPs <2%,在MBv2中 dw FLOPs < 3%,以下以1×1卷积为例。
对于MBv1, MBv2, EN,对第一个卷积层不剪枝,对最后一个全连接层不剪枝。
Kernel Implementation
一般卷积计算的矩阵格式是 HW C,我们的SpMM使用的矩阵格式是 C HW
以 1×1 卷积为例:
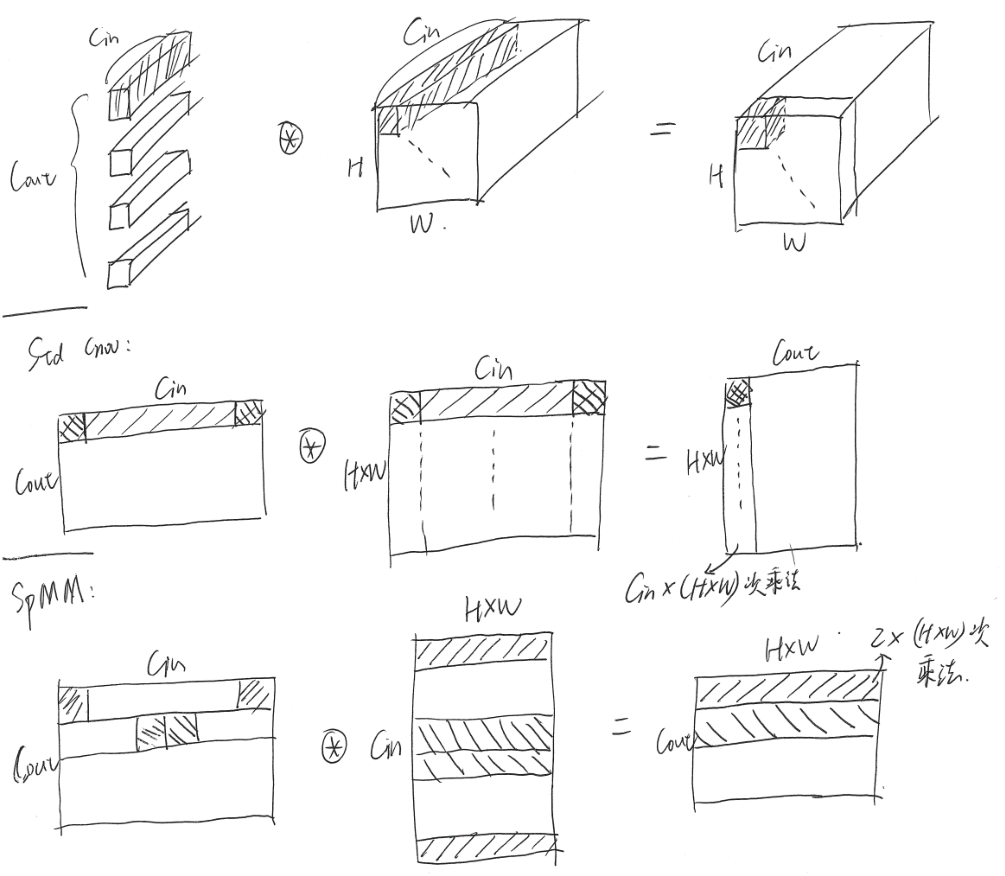
HW C 与 C HW 的在内存中存储的区别:
- HW C中,同一个 spatial location,不同 channel 的元素在内存中是相邻的
- C HW中,不同 spatial location,同一个 channel 的元素在内存中是相邻的
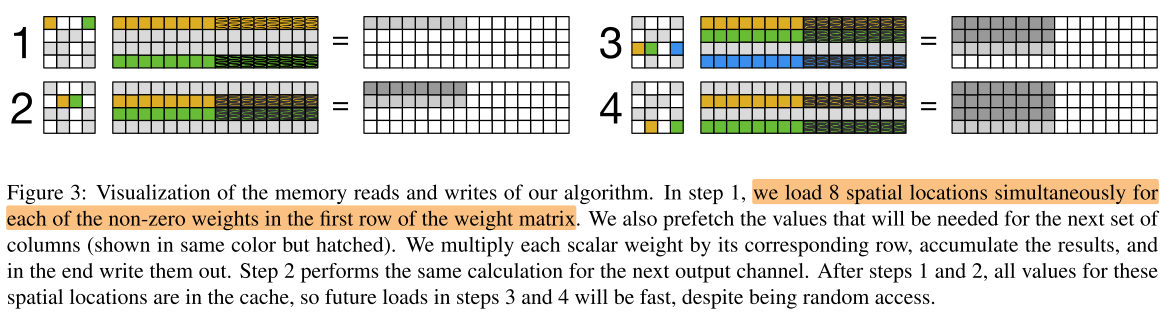
我们的SpMM可以实现高性能的原因是:
- 虽然 Weight 矩阵是稀疏的,但 Activation 矩阵是密集的,定向从Activation中(顺序)读取vector,可以实现密集乘法,减少乘法次数
- 对 Activation vector 进行预读取
- 对矩阵乘法按合适的顺序进行,使得数据大部分都位于L1 cache 中,后续访问速度快
- 当 (C_{in}) 足够小,整个 Activation 都可以存储在cache中,进一步减少 cache miss 的时间
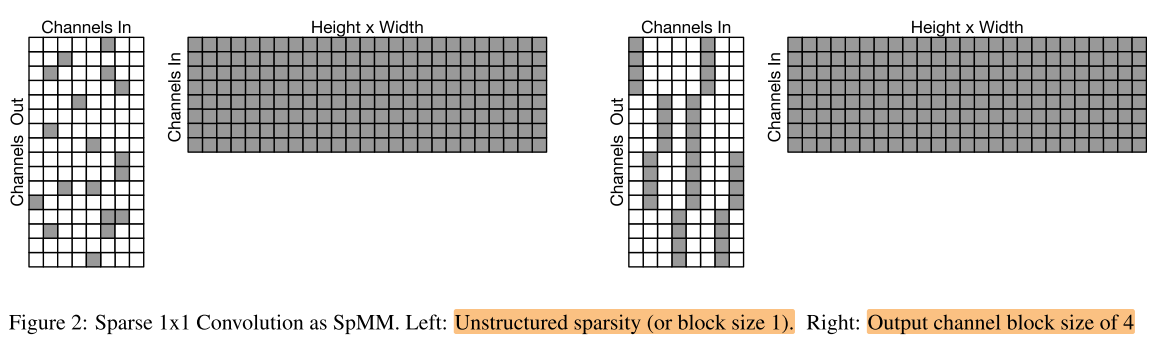
- 进一步提高 data reuse:对稀疏pattern进行约束:n×1,在weight 的output channel 维度上进行blcok约束
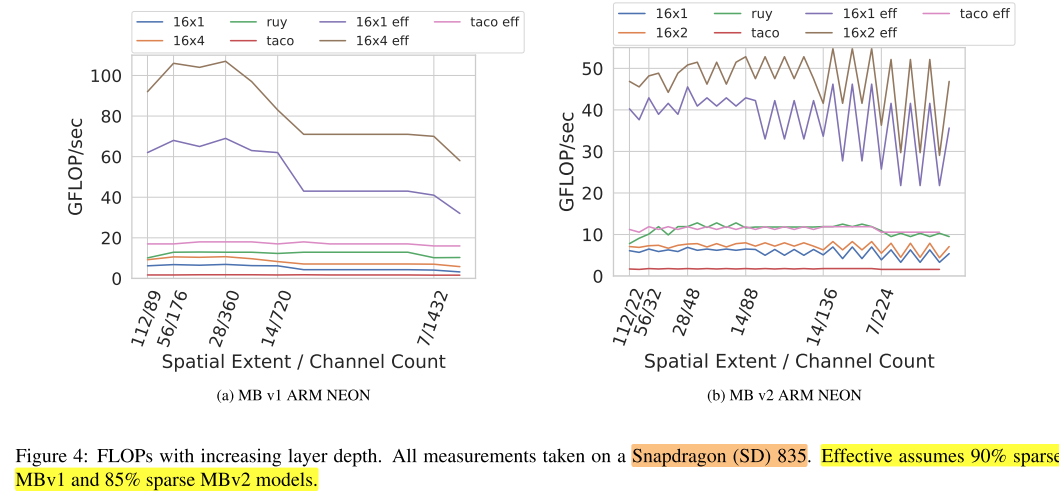
Experiments
使用top-1性能相当的模型进行比较,要达到同样的性能,因此Sparse版本的网络width会比dense版本更大。
具体来说,MBv1 稀疏率90%;MBv2 稀疏率85%

block形状的影响:

在MBv1中,在最后2层,当通道数(1024)导致 “strip” 的大小超过L1缓存的大小时,模型的最后两层性能就会明显下降(16×4表示 spatial vectorization width=16,block size=2 ):