2020-ICLR-FSNet Compression of Deep Convolutional Neural Networks by Filter Summary
来源:ChenBong 博客园
- Institute:Arizona State University,Microsoft Research,etc.
- Author:Yingzhen Yang,Nebojsa Jojic,etc.
- GitHub:/
- Citation:5
Introduction
- Filter Summary (FS): 提出了一种参数共享的卷积层,将一个卷积层所有的 filter 展开为一维,相邻 filter 重叠进行参数共享,一个卷积层可以用一个一维向量来表示,可以提高 Params 压缩率。
- Fast Convolution by Filter Summary (FCFS): 提出了一种一维卷积的加速算法,不用把一维的卷积核还原回 3D 的形式进行卷积,可以提高 FLOPs 压缩率。
- FSNet-WQ: 可以与量化方法结合,进一步提高 Params,FLOPs 压缩率
- DFSNet: 借鉴NAS的思想,可以以 End to End 的方式搜索每个一维卷积层中每个 filter 的 index
- DFSNet-DARTS: 可以与现有的NAS方法结合,搜索新的结构
Motivation
Contribution
We propose Filter Summary (FS) as a compact 1D representation for convolution filters.
- 提出了一种卷积核的一维表示(FS)
We propose a fast convolution algorithm for convolution with FS, named Fast Convolution by Filter Summary (FCFS), taking advantage of the 1D representation of filters in FS.
- 提出了一种适用于 FS 的快速卷积算法(FCFS),充分利用了卷积核一维表示的优点
In order to learn an optimal way filters share weights, we propose Differentiable Filter Summary Network, DFSNet.
- 提出了一种可微分的FS网络,使得网络可以学习更好地进行 filter 之间的参数共享
Method
Notation
- (m:n) —— indicate integers between m and n
- ([n]) —— defined as 1 : n
- (v_{m:n}) —— indicates a vector consisting of elements of (v) with indices in (m : n) .
Filter Summary(FS)
一个 layer 的所有参数的一维表示称为:FIlter Summary(FS)
一个 layer 的输出,输入通道数:(C_{out}, C_{in}) ,kernel_size: (S_1, S_2)
一个 filter 的 weight 数量: (C_{in}×S_1×S_2=K)
一个 layer 的 weight 数量: (KC_{out})
参数压缩率为 (r) ,则 FS 的长度 (L riangleqleftlfloorfrac{K C_{out}}{r} ight floor)
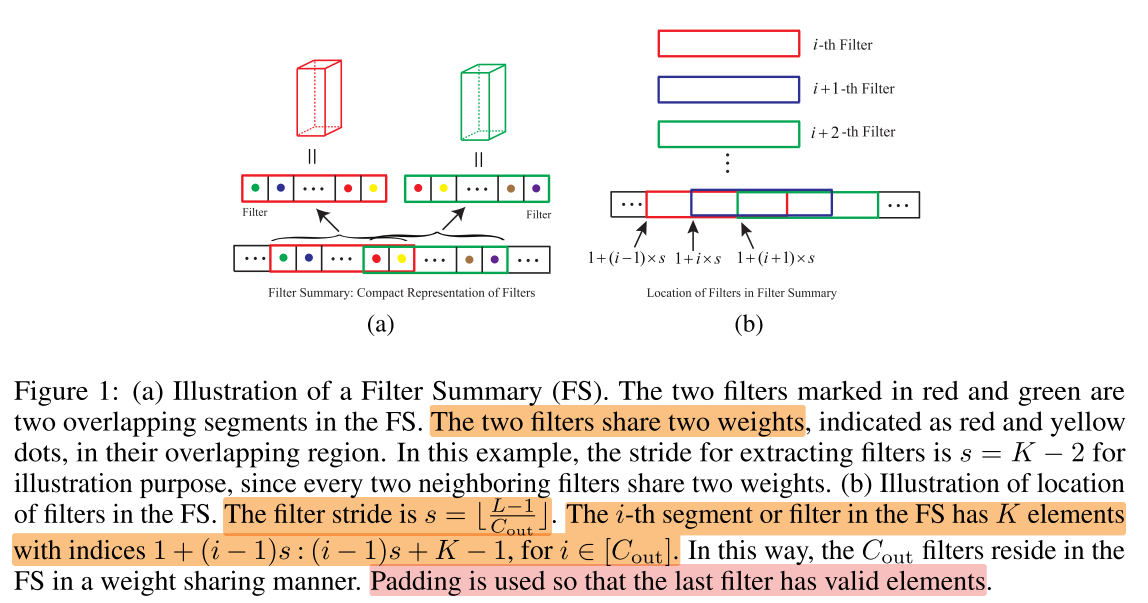
图1-a:
- 每个一维的 FS vector 表示一个卷积层
- 每个 FS 中的一段序列,表示每个 3D filter 按照 channel-major order 的一维展开
- 相邻的 filter 之间有重叠的部分,重叠部分的参数即为 filter 之间的共享参数
- 在这个例子中,stride (s=K-2)
图1-b:
- 不同的 filter 在 FS 中是等间隔排列的
- filter stride = (leftlfloorfrac{L-1}{C_{out}} ight floor)
- 第 i 个filter 的序列 在 FS 中的位置为 (1+(i-1)s : (i-1)s+K-1) for i in ([C_{out}])
例如:
一个卷积层: (C_{out}=64, C_{in}=64, s1=s2=3)
参数压缩率 (r=4)
则 FS 的长度 (L=frac{64 imes 64 imes 3 imes 3}{4}=9216)
stride (s=lfloor frac{9216-1}{64} floor=143)
Fast Convolution by Filter Summary(FCFS)
每次卷积计算的是 feature map 的一个 patch (记为 feature patch)与 一个 filter 的内积(对应位置元素相乘 再求和)
由于卷积的 stride 通常都较小,因此 一个feature map 中的不同 feature patch 其实也是参数共享的
当两者(feature patch 和 filter)都是参数共享的时候,内积运算可以被简化,以避免重复计算
因此我们提出一种适用于 FS 的快速卷积算法:Fast Convolution by Filter Summary(FCFS)
我们将 feature map( (C_{in} imes D_1 imes D_2) )也按 channel-major order 展开为一维,记为 (M)
feature map 中 ([i,j,k]) 的 element 位于 (M_{k cdot C_{in}D_1+jC{in}+i})
因此不同的 feature patch( (C_{in} imes S_1 imes S_2) )位于 M 中的不同位置(可能是重叠的)
如图2,一个 feature patch 中的 2 个 slice((C_{in} imes S_1)),位于M中的不同位置:
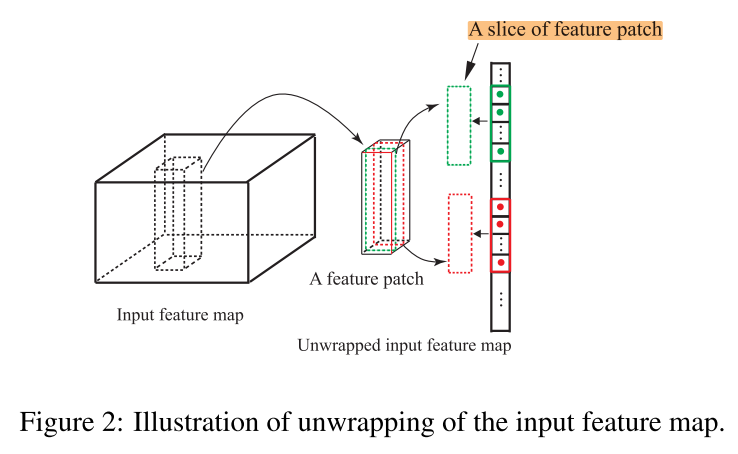
用 (F) 来表示一个 FS,
同理,3D filter 的不同 slice,也位于 (F) 的不同位置(图3-上)
(F) 中的一个 filter 的 一个 slice 会和 feature map 中的任意位置的 feature patch slice 都计算一次内积,例如 filter 1 中的 slice-a,和 filter-2 中的 slice-b,都会和 feature map 中的 feature patch slice-c 进行内积运算,而 slice-a 和 slice-b 存在共享的参数,如果分别和 slice-c 做内积,就产生了重复计算(图x-1)。
S1:我们先计算 (M) 和 (F) 元素之间的乘积,并将结果保存在矩阵 (A) 中,(A_{i,j}=M_{i} cdot F_{j},i∈[C_{in}D_1D_2], j∈[L])
因此 feature patch 的一个 slice 与 filter 的一个 slice 的内积,就是对应位置对角线段上的元素之和,(图x-2,从x轴方向上看,对角线段上的元素之和,可以看做是一个 feature patch slice 与不同 filter slice 的内积;同理,y方向上看就是一个 filter slice 与不同 feature patch slice 的内积)
但不能每次都重新求和,这样就产生了重复的加法。
(A) 中的每条对角线可以看做一个向量,记为 (I),长度为 (T) ,因此 (A_{i,j}) 在 (I) 中可以表示为 (I_t) (左上角 t=1)
S2:接下来计算 (IL) 矩阵, (IL) 矩阵大小和 (A) 相同, (IL) 矩阵中每个位置的元素 (I L_{i}=sum_{t=1}^{i} I_{t}, i in[T])
S3:因此每条对角线段之和(一个 filter slice 与 一个 feature patch slice 的内积)可以表示为该线段头尾的 (IL_i) 的差(图3右)
(S3中的减法操作的次数是比较少的,图x-3)

Acceleration of FCFS
feature map:( (C_{in} imes D_1 imes D_2) )
filter size: (C_{in}×S_1×S_2=K)
filter num:(C_{out})
加速比:(frac{C_{mathrm{out}} D_{1} D_{2} K}{C_{mathrm{in}} D_{1} D_{2} L^{prime}+C_{mathrm{out}} D_{1} D_{2} S_{2}}) ,(K>>S_2), (=frac{C_{mathrm{out}} D_{1} D_{2} K}{C_{mathrm{in}} D_{1} D_{2} L^{prime}} approx r S_{1}) ,其中 (frac{L}{C_{mathrm{in}} S_{1}}=L^{prime})
FSNet-WQ
8-bit 量化,参数量减少为 1/4
DFSNet
每个filter 加上一个可学习的 α,让每个 filter 在 (F) 中的起始位置 (l),可以端到端地学习,: (l=frac{1}{1+e^{-alpha}})
Experiments
Setup
baseline CNN
- epoch:300
- lr:0.1
- lr-decay:150,225
CIFAR-10
将 baseline model 中的卷积层替换为 FS:

ImageNet
将 baseline model 中的卷积层替换为 FS:


与 filter 剪枝方法的对比
FSNet, FSNet-WQ 与 结构化剪枝方法的对比


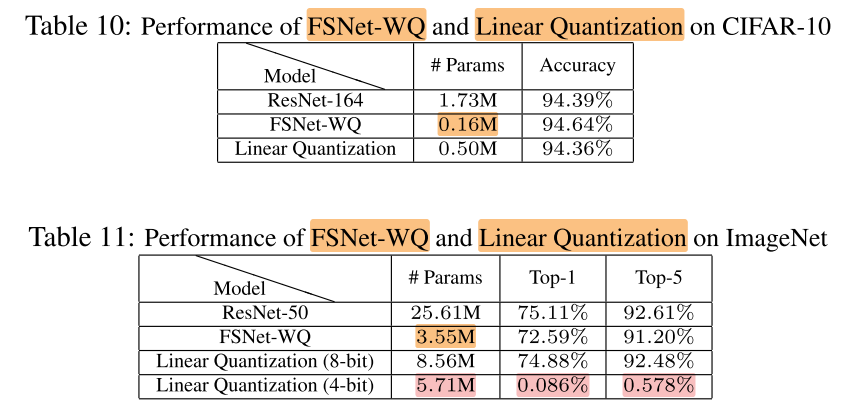
FSNet-WQ
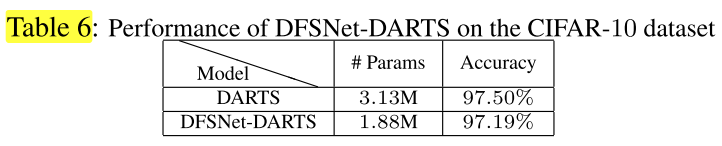
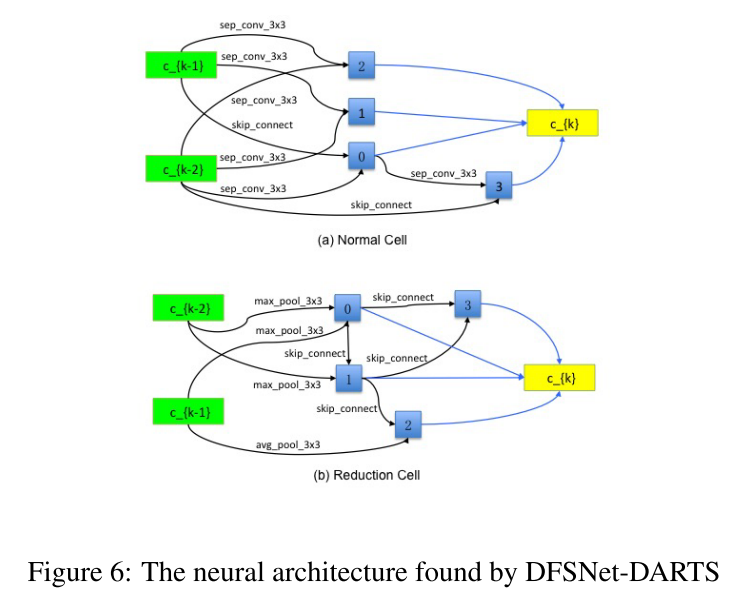
DFSNet-DARTS
将 DARTS 中的搜索空间的卷积层,换成 FS 卷积层:
Conclusion
Summary
To Read
We use the idea of cyclical learning rates (Smith, 2015) for training FSNet.
- Leslie N. Smith. Cyclical Learning Rates for Training Neural Networks. arXiv e-prints, art. arXiv:1506.01186, June 2015.