MetaPruning
2019-ICCV-MetaPruning Meta Learning for Automatic Neural Network Channel Pruning
来源:ChenBong 博客园
- Zechun Liu (HKUST)、Xiangyu Zhang (MEGVII)、Jian Sun(MEGVII)
- GitHub:251 stars
- Citation:20
Motivation
A typical pruning approach contains three stages: training a large overparameterized network, pruning the less-important weights or channels, finetuning or re-training the pruned network.
经典的剪枝三步骤:
- 训练过度参数化的网络
- 剪掉不重要的权重/卷积核
- finetune/re-train剪枝后的网络
这个经典pipeline的
- 第一个难点其中第二步是剪枝paper中讨论最多的地方,很多paper提出各种重要性度量函数或者“如何剪枝”的方法,如果是global-wise的剪枝算法(比如nvidia的taylor方法)一般不需要确定每层的剪枝率,而如果是layer-wise的剪枝算法,一般还需要人工确定每一层的剪枝比例。
- 第二个难点在于剪枝后fine-tune或re-train的过程十分耗时
a recent study [36] finds that the pruned network can achieve the same accuracy no matter it inherits the weights in the original network or not.
最近的研究表明,不论是否继承原始网络的权重,剪枝后的网络都可以达到相同的精度。(权重不重要,网络的结构比较重要)
This finding suggests that the essence of channel pruning is finding good pruning structure - layer-wise channel numbers.
通道剪枝的本质是找到好的网络结构(每层多少个卷积核)
In most traditional channel pruning, compression ratio for each layer need to be manually set based on human experts or heuristics, which is time consuming and prone to be trapped in sub-optimal solutions.
传统的通道剪枝算法的每层的压缩率需要人工设置或使用启发式算法确定,计算量大或容易陷入次优解
Contribution
train a PruningNet that can generate weights for all candidate pruned networks structures, such that we can search good-performing structures by just evaluating their accuracy on the validation data, which is highly efficient.
PruningNet可以为所有候选的剪枝网络生成权重(节省re-train的时间),这样可以搜索更多的剪枝结构。
Moreover, by directly searching the best pruned network via determining the channels for each layer or each stage, we can prune channels in the shortcut without extra effort, which is seldom addressed in previous channel pruning solutions.
通过直接确定每层的通道数来搜索最优结构,我们可以修剪shortcut中的通道&&,而无需额外的工作。这点在之前的工作中很少涉及。
At the same FLOPs, our accuracy is 2.2% - 6.6% higher than MobileNet V1, 0.7%-3.7% higher than MobileNet V2, and 0.6%-1.4% higher than ResNet-50.
在相同的FLOPs下,我们的精度比MobileNet V1高出2.2%-6.6%。比MobileNet V2高出0.7%-3.7%,比ResNet-50高出0.6%-1.4%
At the same latency, our accuracy is 2.1%-9.0% higher than MobileNet V1, and 1.2%-9.9% higher than MobileNet V2.
在相同的延迟下,我们的精度比MobileNetV1高出2.1%-9.0%,比MobileNetV2高出1.2%-9.9%
We proposed a meta learning approach, MetaPruning, for channel pruning. The central of this approach is learning a meta network (named PruningNet) which generates weights for various pruned structures. With a single trained PruningNet, we can search for various pruned networks under different constraints.
NAS:
- s1:定义搜索空间
- s2:定义结构生成器
- s3:结构生成器生成一个结构
- s4:评估该结构(使用重训练(耗时),或者某种估计方法(快速)来得到该结构的acc)
- s5:更新结构生成器(使得生成器可以生成结构更好的网络)
- return s3
metaPruning:
-
s0:训练PruningNet(权重生成器)(随机生成结构,训练,让PruningNet的权重生成器学会为特定的网络结构生成权重
-
s1:定义搜索空间:以待剪枝的网络作为基础的搜素空间(每层的通道数≤原始网络的该层通道数)
-
s2:定义结构生成器:使用遗传算法的结构生成器来生成网络结构
-
s3:(使用遗传算法的)结构生成器生成剪枝后的网络结构(每层的通道数)
-
s4:评估该结构(使用PruningNet权重生成器为网络生成权重,在验证集上评估)
-
s5:更新(使用遗传算法的)结构生成器(使得结构生成器可以生成更好的结构)
liberates human from cumbersome hyperparameter tuning and enables the direct optimization with desired metrics.
无需人工调整超参数,直接优化所需指标
MetaPruning can easily enforce constraints in the search of desired structures, without manually tuning the reinforcement learning hyper-parameters.
MetaPruning可以容易的在搜索结构的同时施加特定的约束(FLOPs、Latency...)
The meta learning is able to effortlessly prune the channels in the short-cuts for ResNet-like structures, which is non-trivial because the channels in the short-cut affect more than one layers.
可以修剪shortcut中的通道&&
Method
主要的pipeline分为2个步骤
- 训练一个PruningNet,可以直接生成backbone网络的权值
- 通过进化搜索算法,在搜索空间内搜索结构
(left(c_{1}, c_{2}, ldots c_{l} ight)^{*}=underset{c_{1}, c_{2}, ldots c_{l}}{arg min } mathcal{L}left(mathcal{A}left(c_{1}, c_{2}, ldots c_{l} ; w ight) ight)) (1)
s.t. (mathcal{C}<)constraint
(mathcal{A}) 是剪枝前的网络,我们要找的是在约束C下,使得网络有最小loss的通道序列(c1, c2, ..., cl)*
To achieve this, we propose to construct a PruningNet, a kind of meta network, where we can quickly obtain the goodness of all potential pruned network structures by evaluating on the validation data only.
我们先训练一个PruningNet,一个元网络,直接生成backbone网络的权值,因此无需fine-tune或re-train,我们可以直接在验证集上获得剪枝后结构的性能。
Then we can apply any search method, which is evolution algorithm in this paper, to search for the best pruned network.
PruningNet网络训练完毕后,我们可以应用多种搜索方法,使用结构生成器生成不同的网络结构,并对这些结构使用PruningNet进行权重生成,进而测试精度,通过测试精度来更新结构生成器。
这里我们使用的结构生成器是进化搜索算法(遗传算法)。
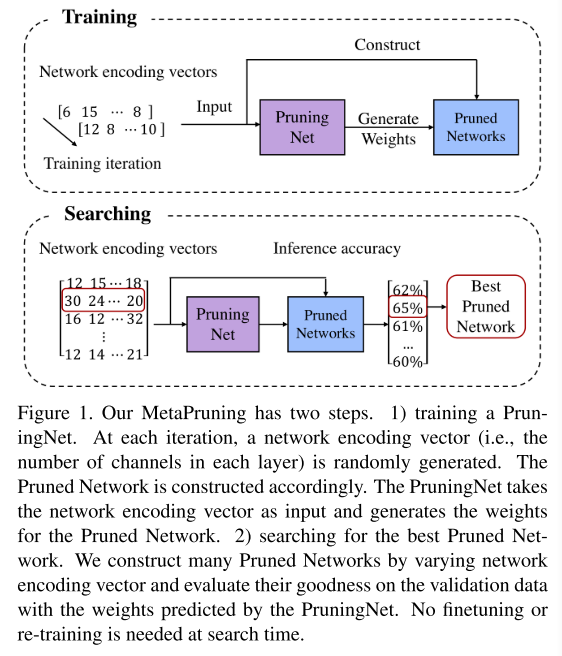
PruningNet Training
这部分先介绍了PruningNet 的训练,即如何让PruningNet学会预测不同结构网络的权重。
The PruningNet is a meta network, which takes a network encoding vector (c1, c2, ...cl) as input and outputs the weights of pruned network:
(mathbf{W}=)PruningNet(left(c_{1}, c_{2}, ldots c_{l} ight)) ......(2)
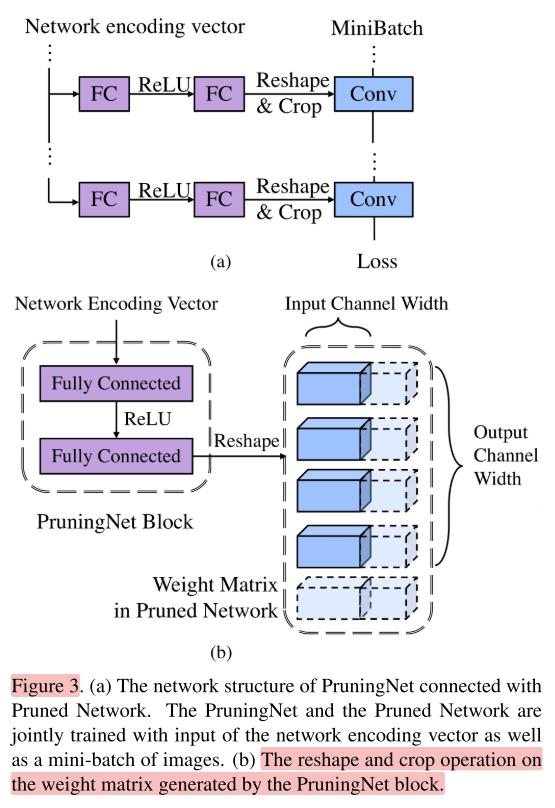
A PruningNet block consists of two fully-connected layers.
PruningNet是一个元网络,接收网络结构vector作为输入,输出该结构的网络参数。
backbone网络有几个层,PruningNet网络就有几个PruningNet block。
1个PruningNet block包含2个全连接层。如图3(a)
In the forward pass, the PruningNet takes the network encoding vector (i.e., the number of channels in each layer) as input, and generates the weight matrix.
Meanwhile, a Pruned Network is constructed.
PruningNet将网络结构vector(每层通道的数量)作为输入,输出网络的权重,并生成网络的结构。如图2
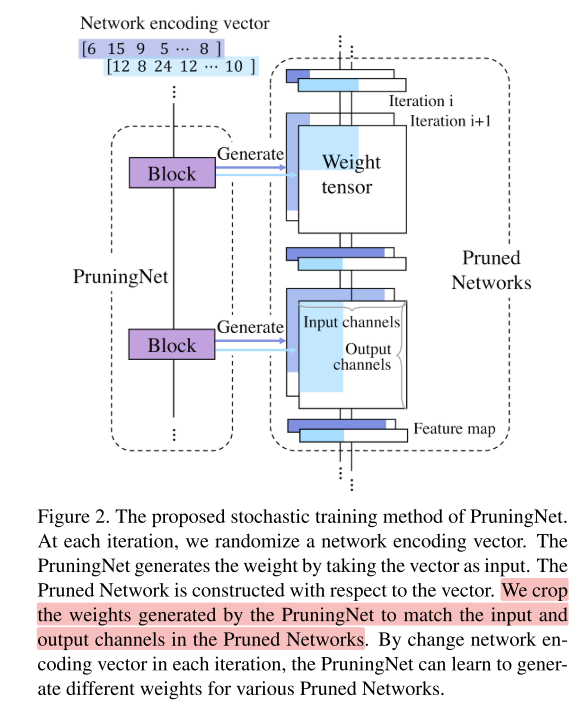
To train the PruningNet, we proposed the stochastic structure sampling. In the training phase, the network encoding vector is generated by randomly choosing the number of channels in each layer at each iteration
训练PruningNet的过程,是在搜索空间里随机采样生成的结构vector。
By stochastically training with different encoding vectors, the PruningNet learns to predict reasonable weights for various different Pruned Networks.
通过训练随机的结构vector,PruningNet就学会了预测不同结构的剪枝网络的权重。
In the backward pass, instead of updating the weights in the Pruned Networks, we calculate the gradients w.r.t the weights in the PruningNet.
反向过程中,不是更新剪枝后网络的权重,而是更新PruningNet的权重。
the gradient of the weights in the PruningNet can be easily calculated by the Chain Rule.
The PruningNet is end-to-end trainable.
PruningNet的权重可以使用Chain Rule计算,因此PruningNet可以被端到端地训练。
前向的细节
整个剪枝网络的结构vector会被分解成每层对应一个encoding vector(包含该层的input channels和output channels的信息),输入到该层对应的PruningNet blcok中。
每个PruningNet block接收一个encoding vector,经过reshape输入一个Weight Matrix,这里的Weight Matrix的大小是固定的(即原始backbone网络该层的Weight Matrix大小),再根据该层的encoding vector,对Weight Matrix进行Crop,就得到剪枝后网络的Weight Matrix。
Given a batch of input image, we can calculate the loss from the Pruned Network with generated weights.
给一个batch的输入图片,我们可以计算在生成的权重下的网络的loss
Pruned-Network Search
After the PruningNet is trained, we can obtain the accuracy of each potential pruned network by inputting the network encoding into the PruningNet, generating the corresponding weights and doing the evaluation on the validation data.
在PruningNet训练完成后,我们将网络结构vector输入PruningNet,就可以获得剪枝后网络的权重,在验证集上进行测试即可获得剪枝后网络的acc
To find out the pruned network with high accuracy under the constraint, we use an evolutionary search, which is able to easily incorporate any soft or hard constraints.
为了找到acc最高的剪枝后网络,我们使用进化算法搜索(可以容易的施加soft or hard constrains)
pruned network is encoded with a vector of channel numbers in each layer, named the genes of pruned networks.
剪枝后网络的结构vector成为该网络的基因
we first randomly select a number of genes
首先随机生成不同网络的基因
Then the top k genes with highest accuracy are selected for generating the new genes with mutation and crossover
训练这些网络,选择acc最高的(网络)基因作为父本,通过突变和交叉互换产生子代。
We can easily enforce the constraint by eliminate the unqualified genes.
我们可以将不符合约束的子代淘汰,继续选择符合约束的最佳子代种群产生后代
进化搜索算法:

Experiments
Setting
In the first stage, the PruningNet is train from scratch with stochastic structure sampling, which takes 1/4 epochs as training a network normally. Further prolonging PruningNet training yields little final accuracy gain in the obtained Pruned Net.
第一阶段,从搜索空间随机抽样训练PruningNet,大概花费1/4的epochs,使用更多的epochs时PruningNet的性能提升不明显。
In the second stage, we use an evolutionary search algorithm to find the best pruned network.
第二阶段,使用进化搜索算法搜索最佳的剪枝结构。
no fine-tuning or retraining are needed at search time, which makes the evolution search highly efficient.
搜索过程中无需fine-tuning或者retraining,因此搜索过程十分高效
The best PrunedNet obtained from search is then trained from scratch.
找到最佳的剪枝结构后,train from scratch
standard data augmentation strategies as [19] to process the input images
使用与[19]相同的数据增强
At training time, we split the original training images into sub-validation dataset, which contains 50000 images, and sub-training dataset with the rest of images
训练阶段,将原始训练集划分为子验证集(50000张)和子训练集(剩下的部分)
We train the PruningNet on the sub-training dataset and evaluating the performance of pruned network on the sub-validation dataset in the searching phase.
在子训练集上训练PruningNet,在子验证集上测试剪枝后网络的实际表现。
At search time, we recalculate the running mean and running variance in the BatchNorm layer with 20000 sub-training images for correctly inferring the performance of pruned networks, which takes only a few seconds.
搜索阶段,使用20000张子训练集重新计算剪枝后网络BN层的均值和方差,推断剪枝后网络的性能,花费几秒的时间。
After obtaining the best pruned network, the pruned network is trained from scratch on the original training dataset and evaluated on the test dataset.
获得最佳网络后,在原始训练集和原始验证集上train from scratch
MobileNet V1
we have the PruningNet blocks equal to the number of convolution layers in the MobileNet v1
each PruningNet block is composed of two concatenated fully-connected(FC) layers.
待剪枝的backbone网络有几层,对应的PruningNet就有几个PruningNet block,每个PruningNet block中包含2个FC layer,一个FC block用来预测一层的参数。
Then this vector is decoded into the input and output channel compression ratio of each layer, i.e., (left[frac{C_{p o}^{l-1}}{C_{o}^{l-1}}, frac{C_{p o}^{l}}{C_{o}^{l}} ight])
网络结构vector被编码成压缩率,剪枝网络的第i层对应PruningNet中的第i个FC block,这个block的输入参数为 ([上一层输出通道压缩率,当前层输出通道压缩率]) 。即 ([frac{上一层剪枝后的输出通道数}{上一层原始输出通道数},frac{当前层剪枝后的输出通道数}{当前层原始输出通道数}]) 。
This two dimensional vector is then inputted into each PruningNet block associated with each layer
剪枝网络每层对应的PruningNet中的FC block的输入都是二维vector
The first FC layer in the PruningNet block output a vector with 64 entries.
PruningNet block中第一个FC层的输出是64行&&的vector
the second FC layer use this 64-entry encoding to output a vector with a length of (C_{o}^{l} imes C_{o}^{l-1} imes W^{l} imes H^{l}) Then we reshape it to (left(C_{o}^{l}, C_{o}^{l-1}, W^{l}, H^{l} ight)) as the weight matrix in the convolution layer, as shown in Figure.3.
block中第二个FC层将64行的vector作为输入,输出长度为 (C_{o}^{l} imes C_{o}^{l-1} imes W^{l} imes H^{l}) 的vector,接着reshape成形状为 (left(C_{o}^{l}, C_{o}^{l-1}, W^{l}, H^{l} ight)) 的matrix
MobileNet V2
In MobileNet V2, each stage starts with a bottleneck block matching the dimension between two stages.
在MobileNet V2中,每个stage从一个bottleneck block开始,这个block匹配两个阶段的维度。&&
If a stage consists of more than one block, the following blocks in this stage will contain a shortcut adding the input feature maps with the output feature maps, thus input and output channels in a stage should be identical, as shown in Figure 4 (b).
如果一个stage包含多个block,那么该stage包含一个shortcut连接,将input feature maps 和 output feature maps相加,因此该stage的input channels 和 output channels相同。
To prune the structure containing shortcut, we generate two network encoding vectors.
为了修剪包含shortcut的结构,我们生成2个网络的encoding vectors
one encodes the overall stage output channels for matching the channels in the shortcut.
一个vector对所有stage的output channels进行编码
another encodes the middle channels of each blocks
另一对stage中间的channels进行编码
we generate the corresponding weight matrices in that block, with a vector (left[frac{C_{p o}^{b-1}}{C_{p}^{b-1}}, frac{C_{p o}^{b}}{C_{o}^{b}}, frac{C_{middle;po}^{b} }{C_{middle; o}^{b}} ight])
我们使用 ([frac{上一个block剪枝后的output; channels}{上一个block原始的output; channels}, frac{当前block剪枝后的output; channels}{当前block原始的output; channels}, frac{当前block中间层剪枝后的output; channels}{当前block中间层原始的output; channels}]) ,即 ([上一个block的output channels压缩率,当前block的output channels压缩率,当前block的中间层压缩率])
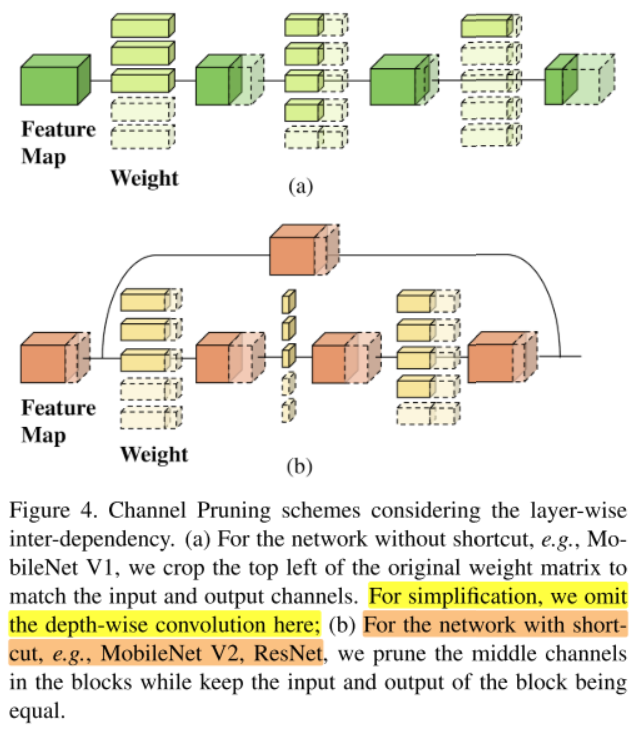
ResNet
ResNet has similar network structure with MobileNet v2
ResNet与MobileNet V2有相似的结构
only differs at the type of convolution in the middle layer, the downsampling block and number of blocks in each stage.
唯一的不同是中间层的卷积类型、downsampling block和每个stage中blcok的数量。&&
Pruning under FLOPs constraint(FLOPs约束)
Table 1 compares our accuracy with the uniform pruning baselines reported in [24], we obtain 6.6% higher accuracy than the baseline 0.25× MobileNet V1.
表一比较了相同FLOPs下,我们的方法与uniform pruning baseline的acc差距,比0.25x MobileNet V1 baseline高出6.6%。
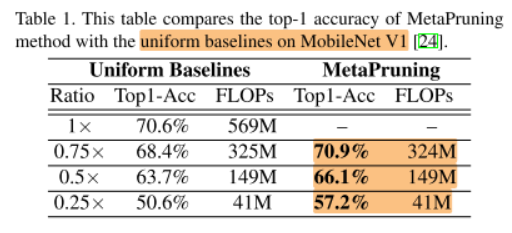
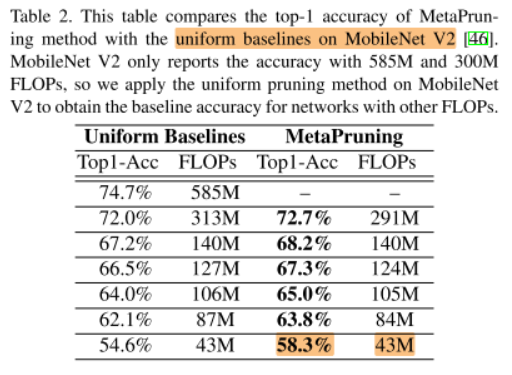
we also achieves decent improvement on MobileNet V2, shown in Table.2. With MetaPruning, we can obtain 3.7% accuracy boost when the model size is as small as 43M FLOPs.
同样在43MB FLOPs的约束下,我们比baseline高出3.7%
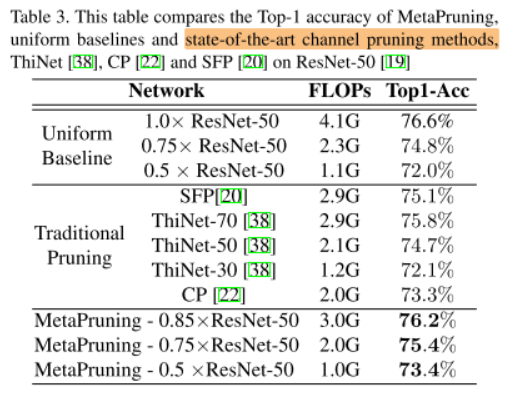
For heavy models as ResNet, MetaPruning also outperforms the uniform baselines and other traditional pruning methods by a large margin, as is shown in Table.3.
MetaPruning与Uniform Baseline和传统剪枝方法对比
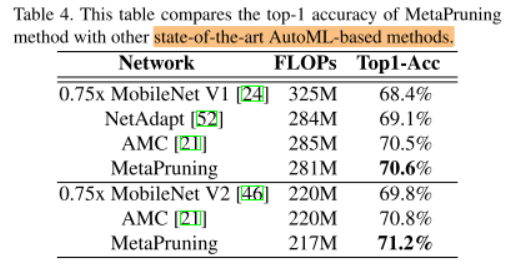
In Table 4, we compare MetaPruning with the state-ofthe-art AutoML pruning methods.
MetaPruning与SOTA的AutoML剪枝算法对比
Pruning under latency constraint (Latency 约束)
Without knowing the implementation details inside the device, MetaPruning learns to prune channels according to the latency estimated from the device.
无需了解设备内部的实现细节,MetaPruning学习估计网络在设备上的运行时间,施加Latency约束。
As the number of potential Pruned Network is numerous, measuring the latency for each network is too timeconsuming.
搜索空间中的候选网络很多,每个都放到设备上运行测试太耗时,可以采用某种方法直接根据网络结构估计网络的耗时。
With a reasonable assumption that the execution time of each layer is independent, we can obtain the network latency by summing up the run-time of all layers in the network.
合理假设网络所有层的执行时间,是每一层单独执行时间的和。
Following the practice in [49, 52], we first construct a look-up table, by estimating the latency of executing different convolution layers with different input and output channel width on the target device.
我们首先构造查找表,通过估计不同的输入和输出通道在特定设备上的延时来构造查找表。
Then we can calculate the latency of the constructed network from the look-up table.
然后我们可以根据查找表估计剪枝后网络的延时
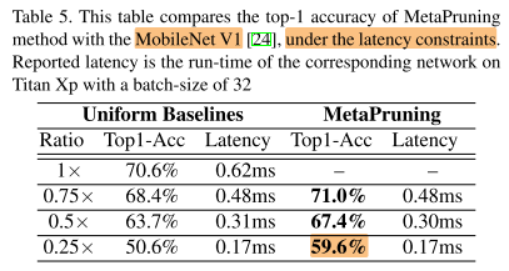
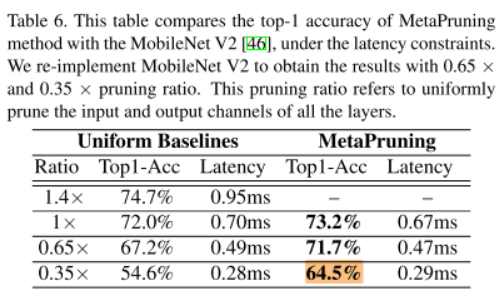
We carried out experiments on MobileNet V1 and V2. Table 5 and Table 6 show that the prune networks discovered by MetaPruning achieve significantly higher accuracy than the uniform baselines with the same latency.
我们在MobileNet V1和V2上进行了实验,表5和表6表明,通过MetaPruning发现(剪枝)的网络在相同的延时下有更高的精度。
Pruned result visualization
Figure 5 shows the pruned network structure of MobileNet V1.
图5展示了剪枝后MobileNet V1的结构。纵轴为不同block的输出通道数。
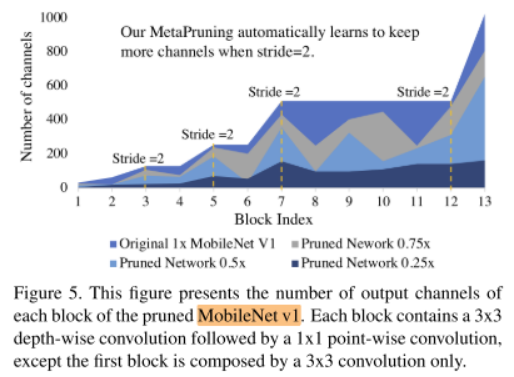
We observe significant peeks in the pruned network every time when there is a down sampling operation.
我们观察到每当stride=2,即这个block进行down sampling操作时,通道数都有个高峰。
When the down-sampling occurs with a stride 2 depthwise convolution, the resolution degradation in the feature map size need to be compensated by using more channels to carry the same amount of information.
可能是因为,stride=2/downsampling 操作时,feature map分辨率下降,需要更多的通道数来补偿feature map分辨率的降低
Thus, MetaPruning automatically learns to keep more channels at the downsampling layers.
因此MetaPruning自动地学习到在downsampling层的时候保持更多的channels。
The same phenomenon is also observed in MobileNet V2, shown in Figure 6.
同样的现象也可以再MobileNet V2上观察到。纵轴为不同block的middle channels
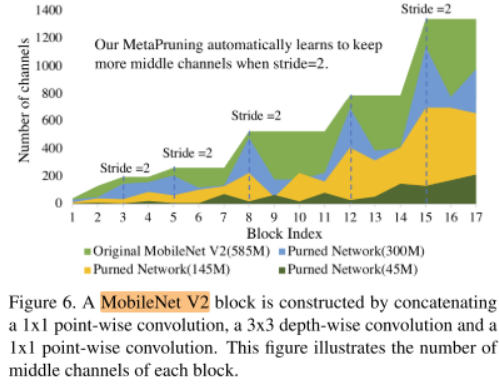
The middle channels will be pruned less when the corresponding block is in responsible for shrinking the feature map size.
当一个block负责缩小feature maps的size时,这个blcok内部的channels会被修剪的比较少
Moreover, when we automatically prune the shortcut channels in MobileNet V2 with MetaPruning, we find that, despite the 145M pruned network contains only half of the FLOPs in the 300M pruned network, 145M network keeps similar number of channels in the last stages as the 300M network, and prunes more channels in the early stages.
当我们使用MetaPruning修剪MobileNet V2时,我们发现尽管145M的剪枝网络的FLOPs仅有300M网络的FLOPs的一半,但在最后阶段的block的通道数却差不多,145M网络更多的是修剪前面block的通道。纵轴为不同block的shortcut channels
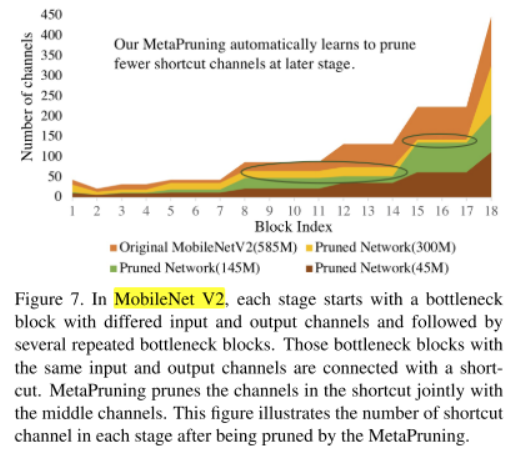
We suspect it is because the number of classifiers for the ImageNet dataset contains 1000 output nodes and thus more channels are needed at later stages to extract sufficient features.
我们怀疑是因为ImageNet数据集包含1000个输出,因此后期需要更多的通道来提取足够的特征。
When the FLOPs being restrict to 45M, the network almost reaches the maximum pruning ratio and it has no choice but to prune the channels in the later stage, and the accuracy degradation from 145M network to 45M networks is much severer than that from 300M to 145M.
145M网络到45M的精度下降比300M网络到145M网络的精度下降大得多(&&模型越小,精度下降越厉害,这不是正常的吗?)。
Ablation study (消融实验)
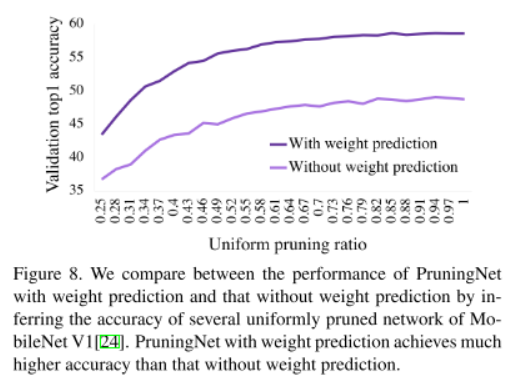
In this section, we discuss about the effect of weight prediction in the MetaPruning method.
We compare the performance between the PruningNet with and without weight prediction.
这部分我们讨论是否使用PruningNet进行权值预测的影响。
Figure 8 shows PruningNet without weight prediction achieves 10% lower accuracy.
图8说明使用PruningNet进行权值预测比不使用PruningNet进行预测,网络精度高了10%
We further use the PruningNet without weight prediction to search for the Pruned MobileNet V1 with less than 45M FLOPs. The obtained network achieves only 55.3% top1 accuracy, 1.9% lower than the pruned network obtained with weight prediction.
不使用PruningNet进行预测再搜索MobileNet V1,得到的网络比使用PruningNet预测再搜索的结果低了1.9%(&&感觉差距并不大?是不是不使用PruningNet预测权值,直接搜索的效果也不错?)。
In that case, the weight prediction mechanism in meta learning is effective in de-correlating the weights for different pruned structures and thus achieves much higher accuracy for the PruningNet.
在这种情况下(&&是不是在其他情况下,使用PruningNet进行权值预测并没有明显的作用?不然为什么要说In this cast?),使用PruningNet预测权值再搜索可以提高剪枝网的精度。
Conclusion
- it achieves much higher accuracy than the uniform pruning baselines as well as other state-of-the-art channel pruning methods, both traditional and AutoML-based;
比传统的剪枝算法和AutoML剪枝算法更好。
- it can flexibly optimize with respect to different constraints without introducing extra hyperparameters
灵活地施加不同的约束(FLOPs约束、Latency约束)而不引入超参数。(这个好)
- ResNet-like architecture can be effectively handled;
可以修剪ResNet-like的结构
- the whole pipeline is highly efficient.
流程高效
Summary
主要思想:
NAS:
- s1:定义搜索空间
- s2:定义结构生成器
- s3:结构生成器生成一个结构
- s4:评估该结构(使用重训练(耗时),或者某种估计方法(快速)来得到该结构的acc)
- s5:更新结构生成器(使得生成器可以生成结构更好的网络)
- return s3
metaPruning:
- s0:训练PruningNet(权重生成器)(随机生成结构,训练,让PruningNet的权重生成器学会为特定的网络结构生成权重
- s1:定义搜索空间:以待剪枝的网络作为基础的搜素空间(每层的通道数≤原始网络的该层通道数)
- s2:定义结构生成器:使用遗传算法的结构生成器来生成网络结构
- s3:(使用遗传算法的)结构生成器生成剪枝后的网络结构(每层的通道数)
- s4:评估该结构(使用PruningNet权重生成器为网络生成权重,在验证集上评估)
- s5:更新(使用遗传算法的)结构生成器(使得结构生成器可以生成更好的结构)
finetune步骤上的改进:
主要就是评估结构好坏的步骤非常耗时,问题是如何减少评估结构的时间。
注意到结构会直接决定最终的acc,即结构和最终的acc是存在某种函数关系的。因此问题转变成如何通过设计一个算法,直接通过结构来预测该结构的精度,从而免去重训练的时间。
定义搜索空间上的改进:
传统的NAS方法的搜索空间都很大,而MetaPruning是从已有的经典的backbone网络出发,将原始的backbone网络作为搜索空间,而不是从0搜索,大大节省了搜索的时间。
Reference
https://xmfbit.github.io/2019/10/26/paper-meta-pruning/ ⭐️
https://zhuanlan.zhihu.com/p/64422341
https://www.jianshu.com/p/be3054560315
https://blog.csdn.net/qq_30615903/article/details/102975932
https://www.aminer.cn/research_report/5dce46c61ca12517163eecf9