代码实例
import numpy as np
import tensorflow.compat.v1 as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
tf.compat.v1.disable_eager_execution()
tf.disable_v2_behavior()
#加载数据集
mnist = input_data.read_data_sets("C:/Users/chenqi/Desktop/data/mnist", one_hot=True)
trainimg = mnist.train.images
trainlabel = mnist.train.labels
testimg = mnist.test.images
testlabel = mnist.test.labels
print ("MNIST ready")
#定义函数需要的参数(权重和偏置)
n_input = 784
n_output = 10
#wc1 wc2是两个卷积层的过滤器filter,根据下面tf.nn.conv2d函数中对filter参数的要求[filter_height, filter_width, in_channels, out_channels]
#[过滤器的高、过滤器的宽、输入的特征图数量(隐含的表示过滤器的深度)、想要得出的特征图数量]
weights = {
'wc1': tf.Variable(tf.random_normal([3, 3, 1, 64], stddev=0.1)),
'wc2': tf.Variable(tf.random_normal([3, 3, 64, 128], stddev=0.1)),
'wd1': tf.Variable(tf.random_normal([7*7*128, 1024], stddev=0.1)),
'wd2': tf.Variable(tf.random_normal([1024, n_output], stddev=0.1))
}
biases = {
'bc1': tf.Variable(tf.random_normal([64], stddev=0.1)),
'bc2': tf.Variable(tf.random_normal([128], stddev=0.1)),
'bd1': tf.Variable(tf.random_normal([1024], stddev=0.1)),
'bd2': tf.Variable(tf.random_normal([n_output], stddev=0.1))
}
#实现卷积神经网络的函数
def conv_basic(_input, _w, _b, _keepratio):
# INPUT 同理根据tf.nn.conv2d函数中对input要求[batch, in_height, in_width, in_channels]
_input_r = tf.reshape(_input, shape=[-1, 28, 28, 1])
# CONV LAYER 1
_conv1 = tf.nn.conv2d(_input_r, _w['wc1'], strides=[1, 1, 1, 1], padding='SAME')
#_mean, _var = tf.nn.moments(_conv1, [0, 1, 2])
#_conv1 = tf.nn.batch_normalization(_conv1, _mean, _var, 0, 1, 0.0001)
_conv1 = tf.nn.relu(tf.nn.bias_add(_conv1, _b['bc1']))
_pool1 = tf.nn.max_pool(_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
_pool_dr1 = tf.nn.dropout(_pool1, _keepratio)
# CONV LAYER 2
_conv2 = tf.nn.conv2d(_pool_dr1, _w['wc2'], strides=[1, 1, 1, 1], padding='SAME')
#_mean, _var = tf.nn.moments(_conv2, [0, 1, 2])
#_conv2 = tf.nn.batch_normalization(_conv2, _mean, _var, 0, 1, 0.0001)
_conv2 = tf.nn.relu(tf.nn.bias_add(_conv2, _b['bc2']))
_pool2 = tf.nn.max_pool(_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
_pool_dr2 = tf.nn.dropout(_pool2, _keepratio)
# VECTORIZE
_dense1 = tf.reshape(_pool_dr2, [-1, _w['wd1'].get_shape().as_list()[0]])
# FULLY CONNECTED LAYER 1
_fc1 = tf.nn.relu(tf.add(tf.matmul(_dense1, _w['wd1']), _b['bd1']))
_fc_dr1 = tf.nn.dropout(_fc1, _keepratio)
# FULLY CONNECTED LAYER 2
_out = tf.add(tf.matmul(_fc_dr1, _w['wd2']), _b['bd2'])
# RETURN
out = { 'input_r': _input_r, 'conv1': _conv1, 'pool1': _pool1, 'pool1_dr1': _pool_dr1,
'conv2': _conv2, 'pool2': _pool2, 'pool_dr2': _pool_dr2, 'dense1': _dense1,
'fc1': _fc1, 'fc_dr1': _fc_dr1, 'out': _out
}
return out
print ("CNN READY")
a = tf.Variable(tf.random_normal([3, 3, 1, 64], stddev=0.1))
print (a)
a = tf.Print(a, [a], "a: ")
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
#sess.run(a)
x = tf.placeholder(tf.float32, [None, n_input])
y = tf.placeholder(tf.float32, [None, n_output])
keepratio = tf.placeholder(tf.float32)
# FUNCTIONS
_pred = conv_basic(x, weights, biases, keepratio)['out']
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=_pred, labels=y))
optm = tf.train.AdamOptimizer(learning_rate=0.001).minimize(cost)
_corr = tf.equal(tf.argmax(_pred,1), tf.argmax(y,1))
accr = tf.reduce_mean(tf.cast(_corr, tf.float32))
init = tf.global_variables_initializer()
# SAVER
print ("GRAPH READY")
sess = tf.Session()
sess.run(init)
training_epochs = 15
batch_size = 100
display_step = 1
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
#total_batch = 10
# Loop over all batches
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Fit training using batch data
sess.run(optm, feed_dict={x: batch_xs, y: batch_ys, keepratio:0.7})
# Compute average loss
avg_cost += sess.run(cost, feed_dict={x: batch_xs, y: batch_ys, keepratio:1.})/total_batch
# Display logs per epoch step
if epoch % display_step == 0:
print ("Epoch: %03d/%03d cost: %.9f" % (epoch, training_epochs, avg_cost))
train_acc = sess.run(accr, feed_dict={x: batch_xs, y: batch_ys, keepratio:1.})
print (" Training accuracy: %.3f" % (train_acc))
test_acc = sess.run(accr, feed_dict={x: testimg, y: testlabel, keepratio:1.})
print (" Test accuracy: %.3f" % (test_acc))
print ("OPTIMIZATION FINISHED")
最后结果
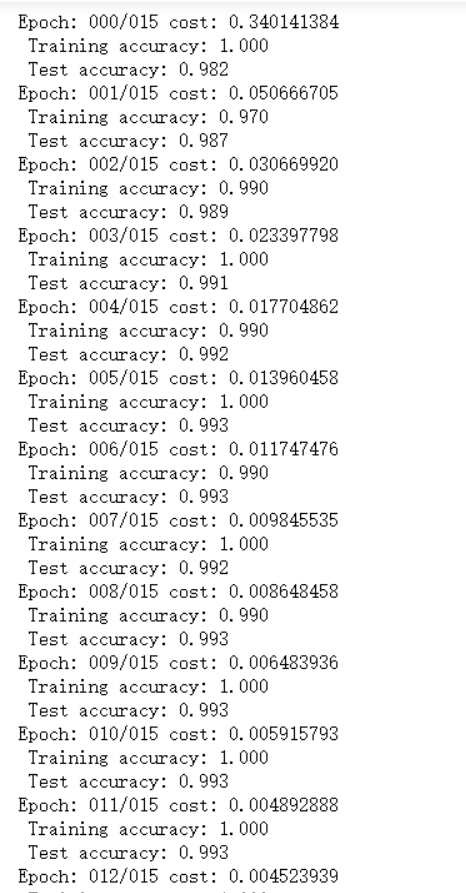
模型草图
-
基本结构
输入→卷积→ReLU→池化→卷积→ReLU→池化→全连接→ReLU→全连接→输出
-
具体模型

-
过滤器:因为在我们这里的图片是只有黑白的28x28的灰度图,所以第一层卷积选用过滤器f1=3x3x1,设置要产生64张特征图,那就需要64个f1。第一层卷积的输出也就是第二层卷积的输入是14x14x64,所以选用过滤器f2=3x3x64,设置需要产生128张特征图,那就需要128个f2,输出是7x7x128。
-
池化:选用了2x2的Max pooling,所以每张特征图经过池化后长、宽都缩小为二分之一,即由28x28x64 → 14x14x64 和 14x14x128 → 7x7x128