m个样本的梯度下降
回顾
上节课我们求得的是单一训练样本的梯度下降,并且得到了一些式子
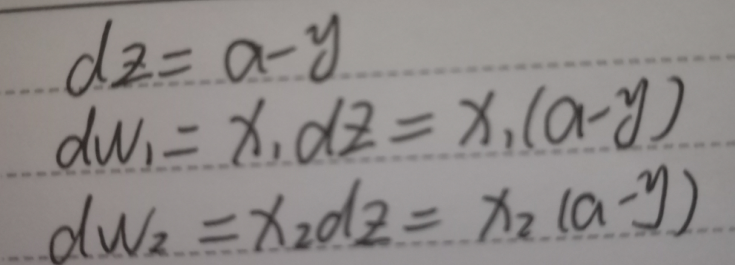
之前我们讲成本函数 J (w,b) 是m项各个损失的平均值
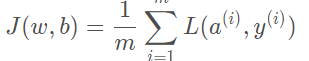
那么,dw1,dw2和db添上上标i,表示的是单一训练样本下的取值。所以要求全局成本函数 J (w,b) 对w1的微 分同样是各项损失对w1微分的平均,也就是m项训练样本的dw1累加起来除于m
具体实现
代码:
J=0;dw1=0;dw2=0;db=0;
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
说明:这里有两个for循环,第一个是通过循环m个训练样本,把 J、dw1、dw1、db累加起来。第二个是没有 写出来的,因为你一个训练样本的x是一个矩阵(列向量),里面可能包含多个特征x1、x2、x3 ~ xn 需要for 循环展开。
注:这里只是应用了一步梯度下降,所以我认为还应该有一个大的循环进行多次训练。
这里讲到了for循环的局限性即导致算法低效,所以向量化就很重要
向量化
运用for循环和向量化的效率对比
import numpy as np #导入numpy库
a = np.array([1,2,3,4]) #创建一个数据a
print(a)
# [1 2 3 4]
import time #导入时间库
a = np.random.rand(1000000)
b = np.random.rand(1000000) #通过round随机得到两个一百万维度的数组
tic = time.time() #现在测量一下当前时间
#向量化的版本
c = np.dot(a,b)
toc = time.time()
print("Vectorized version:" + str(1000*(toc-tic)) +"ms") #打印一下向量化的版本的时间
#继续增加非向量化的版本
c = 0
tic = time.time()
for i in range(1000000):
c += a[i]*b[i]
toc = time.time()
print(c)
print("For loop:" + str(1000*(toc-tic)) + "ms")#打印for循环的版本的时间

注:要学会运用内置函数来尽量避免显示for循环,从而提高效率
向量化的更多例子
numpy库
比如 u=np.log是计算对数函数(log)、 np.abs() 是计算数据的绝对值、np.maximum() 计算元素 y中的最 大值,你也可以 np.maximum(v,0) 、 v ∗ ∗ 2 代表获得元素 y 每个值的平方等等。函数大全
逻辑回归中的初步向量化
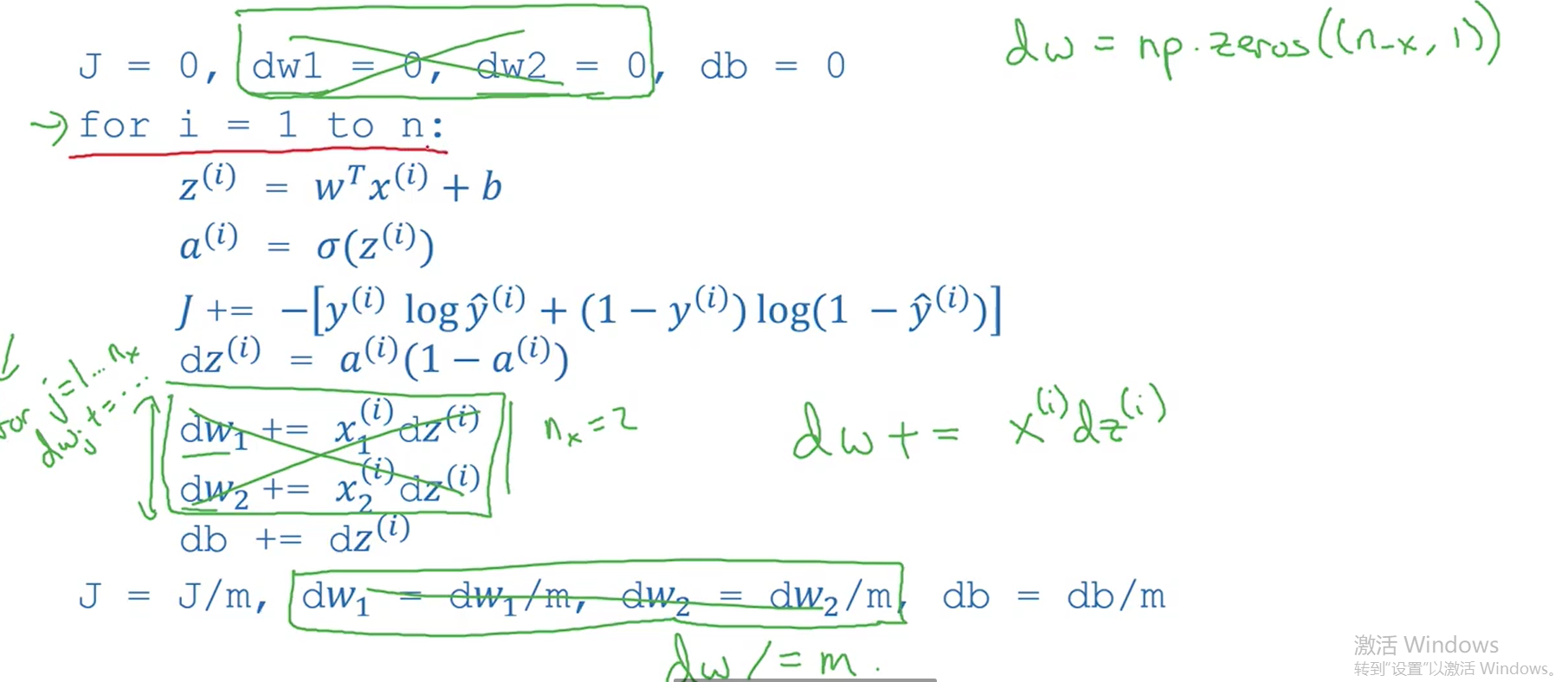
前面讲过w和x都是列向量,z=wTx+b=w1x1+w2x2+b,所以计算dw时我们需要第二个for循环去分别累加求dw1、dw2。现在用向量化解决这个问题,我们知道 dz=a-y 是一个实数,直接初始化dw为一个列向量,那么 就可以使得dw +=x(i)dz(i)。
参考:https://blog.csdn.net/weixin_36815313/article/details/105267247