我前面的博客爬取第一页信息
现在来学习这部分代码
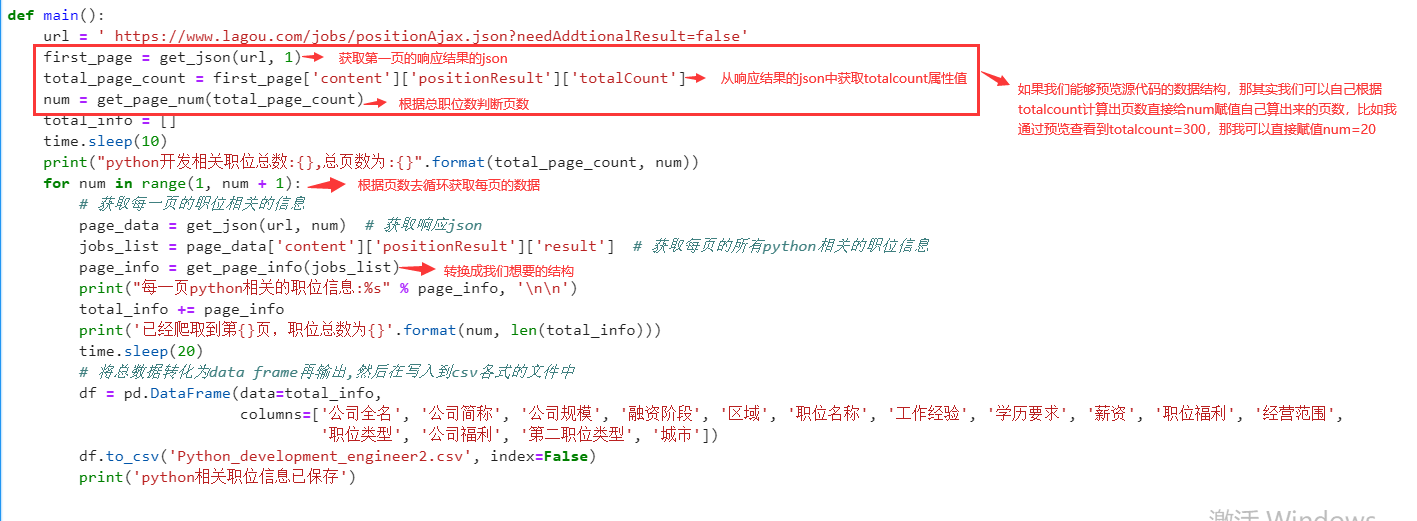
def main(): url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' first_page = get_json(url, 1) total_page_count = first_page['content']['positionResult']['totalCount'] num = get_page_num(total_page_count) total_info = [] time.sleep(10) print("python开发相关职位总数:{},总页数为:{}".format(total_page_count, num)) for num in range(1, num + 1): # 获取每一页的职位相关的信息 page_data = get_json(url, num) # 获取响应json jobs_list = page_data['content']['positionResult']['result'] # 获取每页的所有python相关的职位信息 page_info = get_page_info(jobs_list) print("每一页python相关的职位信息:%s" % page_info, ' ') total_info += page_info print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info))) time.sleep(20) # 将总数据转化为data frame再输出,然后在写入到csv各式的文件中 df = pd.DataFrame(data=total_info, columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '薪资', '职位福利', '经营范围', '职位类型', '公司福利', '第二职位类型', '城市']) df.to_csv('Python_development_engineer2.csv', index=False) print('python相关职位信息已保存')
爬取第一页数据时进行了网页解析,这里也接着来看

点击”预览(preview)”, 预览源代码, 进而分析源代码的数据结构,如果无法通过预览查看源代码,我们也可以通过我们爬取第一页信息获取到的响应结果来分析


我们想要的数据都存储在[‘content’]里,[‘positionResult’][‘pageSize’]告诉我们每页最多15条职位信息,产品经理岗位的总体数量存储在totalCount,[‘positionResult’][‘result’]里面是每个岗位有哪些信息,可将其都打印出来,以便选择自己想要的内容。
但是因为拉勾网最多只能展示30页的数据,每页展示15条总共是450条,而这里有1357条显然是无法全部获取到的,所以我们这里要添加一个函数来判断
def get_page_num(count): """ 计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息 :return: """ page_num = math.ceil(count / 15) if page_num > 30: return 30 else: return page_num
如果你,sum=totalCount除以15(即页数)小于30页返回总页数为sum,如果页数大于30则返回总页数为30页