一、阅读笔记
用户需求拓展:由于开发过程中需求的不断发展与增加,项目往往会落后于计划的进度并超出预算。出现这种情况是因为没有依据对需求的规模和复杂度的实际评估来制定计划,而不断修改需求来是情况变得更糟。问题的责任部分在于用户不断提出修改需求的要求,部分在于开发人员处理这种要求的方式。
有歧义的需求:歧义是需求规约的大忌。歧义表现为同一读者对同一项需求声明作出多种解释,或者不同的读者对同一需求产生不同的理解。
过于抽象的需求:营销人员或者经理经常喜欢只给出一个粗略的说明,他们希望开发人员在开发过程中充实他,这种方式对研究性项目或需求特别灵活的项目也许管用,但是需要紧密合作的团队,而且紧限于开发小型系统。大多数情况下,这种做法的结果是使开发人员受挫,让客户失望。
二、jupyterLab学习第二天
简单爬取一个小说网站
首先得在控制台中下载安装requests-html
安装requests-html非常简单,一行命令即可做到。需要注意一点就是,requests-html只支持Python 3.6及更新的版本,所以使用老版本的Python的同学需要更新一下Python版本了。看了下源代码,因为requests-html广泛使用了一个Python 3.6中的新特性——类型注解。
pip install requests-html
具体代码
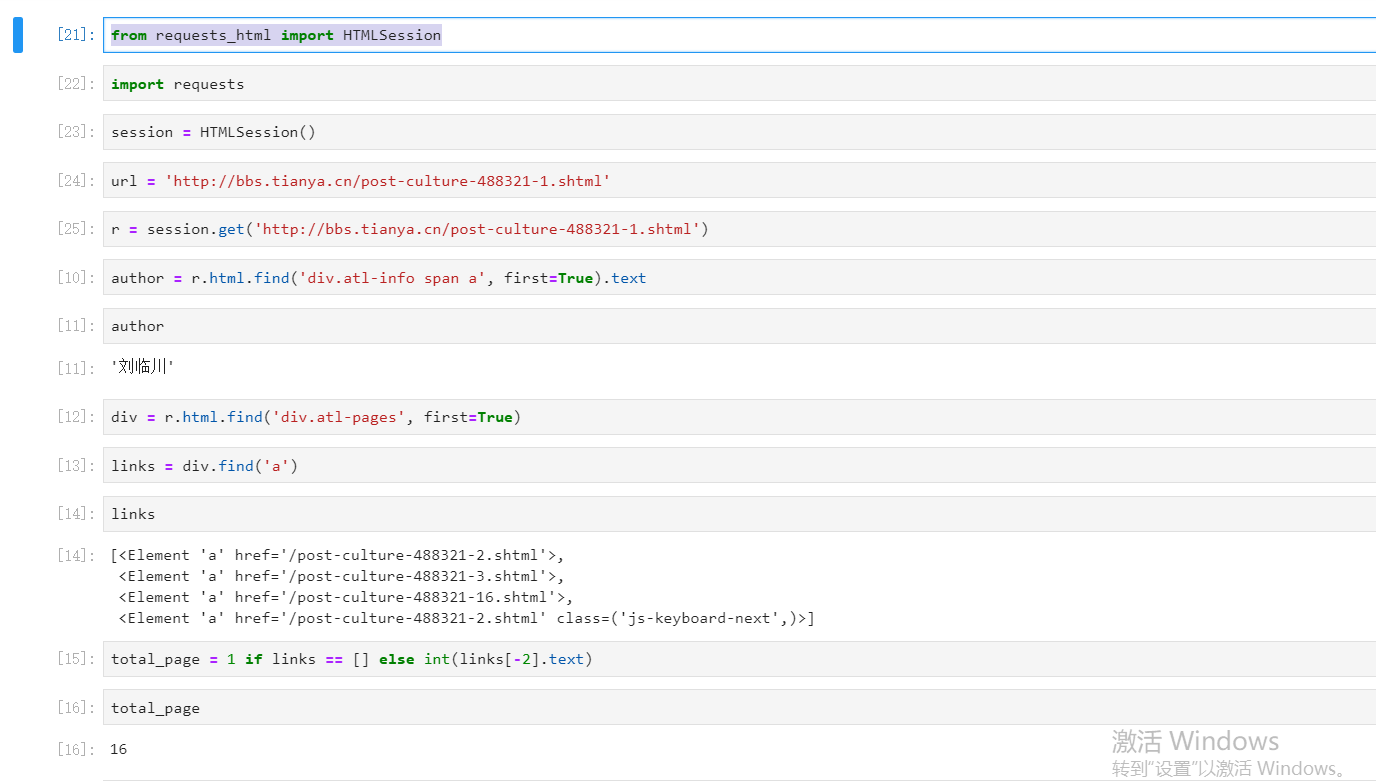
from requests_html import HTMLSession
import requests
session = HTMLSession()
url = 'http://bbs.tianya.cn/post-culture-488321-1.shtml'
r = session.get('http://bbs.tianya.cn/post-culture-488321-1.shtml')
author = r.html.find('div.atl-info span a', first=True).text
div = r.html.find('div.atl-pages', first=True)
links = div.find('a')
total_page = 1 if links == [] else int(links[-2].text)
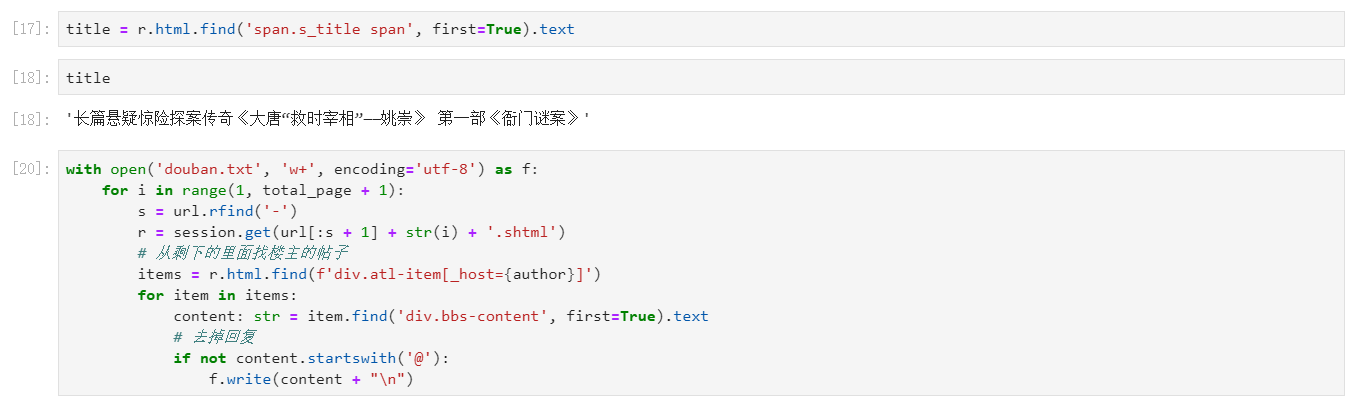
title = r.html.find('span.s_title span', first=True).text
with open('douban.txt', 'w+', encoding='utf-8') as f: for i in range(1, total_page + 1): s = url.rfind('-') r = session.get(url[:s + 1] + str(i) + '.shtml') # 从剩下的里面找楼主的帖子 items = r.html.find(f'div.atl-item[_host={author}]') for item in items: content: str = item.find('div.bbs-content', first=True).text # 去掉回复 if not content.startswith('@'): f.write(content + " ")
这里需要在目录下新建一个douban文本文件保存爬取后的数据