GoodsKG
GoodsKG, 基于京东网站的1300种商品上下级概念,约10万商品品牌,约65万品牌销售关系,商品描述维度等知识库,基于该知识库可以支持商品属性库构建,商品销售问答,品牌物品生产等知识查询服务,也可用于情感分析等下游应用.
项目介绍
概念层级知识是整个常识知识体系中的重要组成部分。概念层级目前包括百科性概念层级和专业性概念层级两类,百度百科概念体系以及互动百科分类体系是其中的一个代表。就后者而言,目前出现了许多垂直行业概念层级,如医疗领域概念体系,垫上领域概念体系,其中以淘宝、京东等为代表的电商网站在以商品为中心上,构建起了一种商品概念目录层级以及商品与品牌,品牌与品牌之间的关联关系。
本项目认为,电商网站中的商品分类目录能够供我们构建起一个商品概念体系,基于商品首页,我们可以得到商品与商品品牌之间的关系,商品的属性以及属性的取值信息。基于这类信息,又可以进一步得到商品的画像以及商品品牌的画像。基于该画像。可以对自然语言处理处理的几个下游应用带来帮助,如商品品牌识别,商品对象及属性级别情感分析,商品评价短语库构建,商品品牌竞争关系梳理等。
因此,本项目以京东电商为实验数据来源,采集京东商品目录树,并获取其对应的底层商品概念信息,组织形成商品知识图谱。目前,该图谱包括有概念的上下位is a关系以及商品品牌与商品之间的销售sale关系共两类关系,涉及商品概念数目1300+,商品品牌数目约10万+,属性数目几千种,关系数目65万规模。该项目可以进一步增强商品领域概念体系的应用,对自然语言处理处理的几个下游应用带来帮助,如商品品牌识别,商品对象及属性级别情感分析,商品评价短语库构建,商品品牌竞争关系梳理等提供基础性的概念服务。
数据介绍
1, 基本数据内容

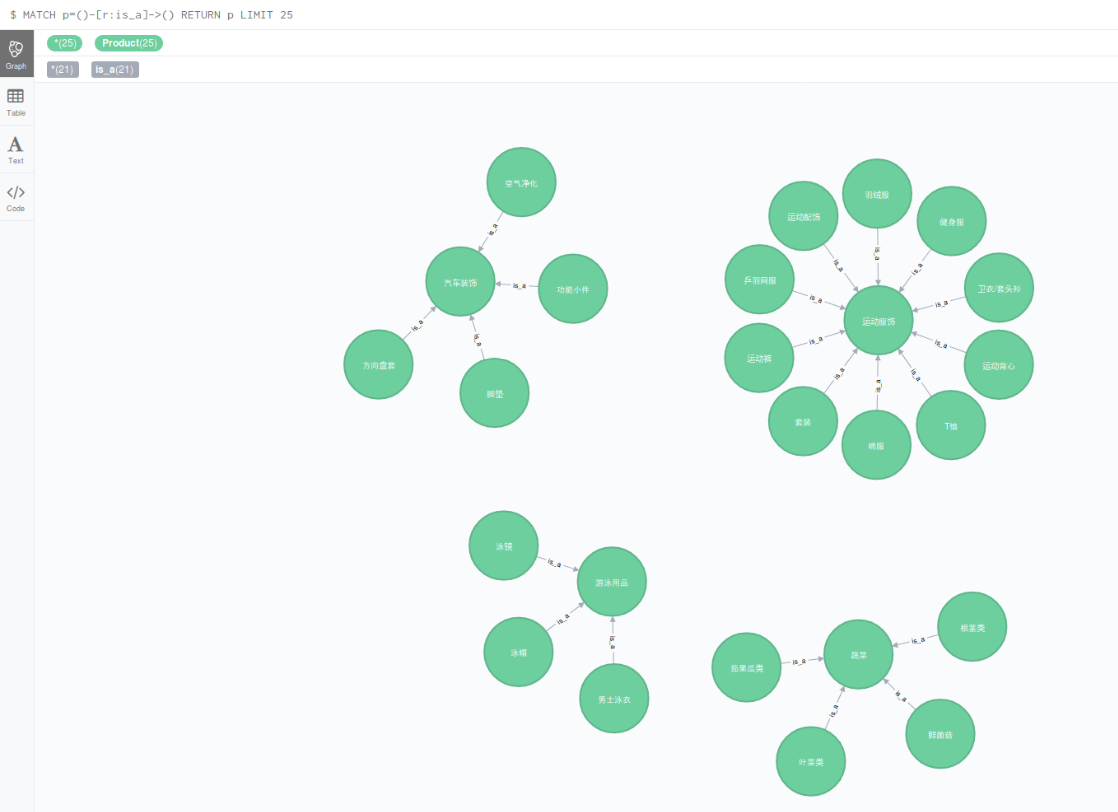
2, is-a概念上下位关系
MATCH p=()-[r:is_a]->() RETURN p LIMIT 25
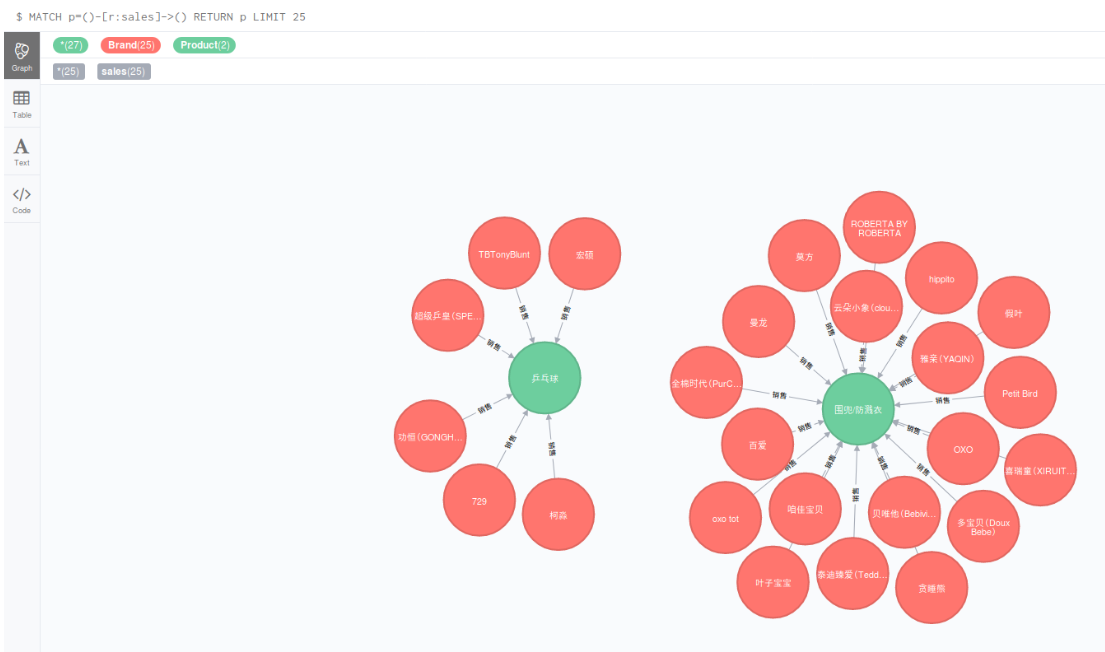
3, sale销售关系
MATCH p=()-[r:sales]->() RETURN p LIMIT 25
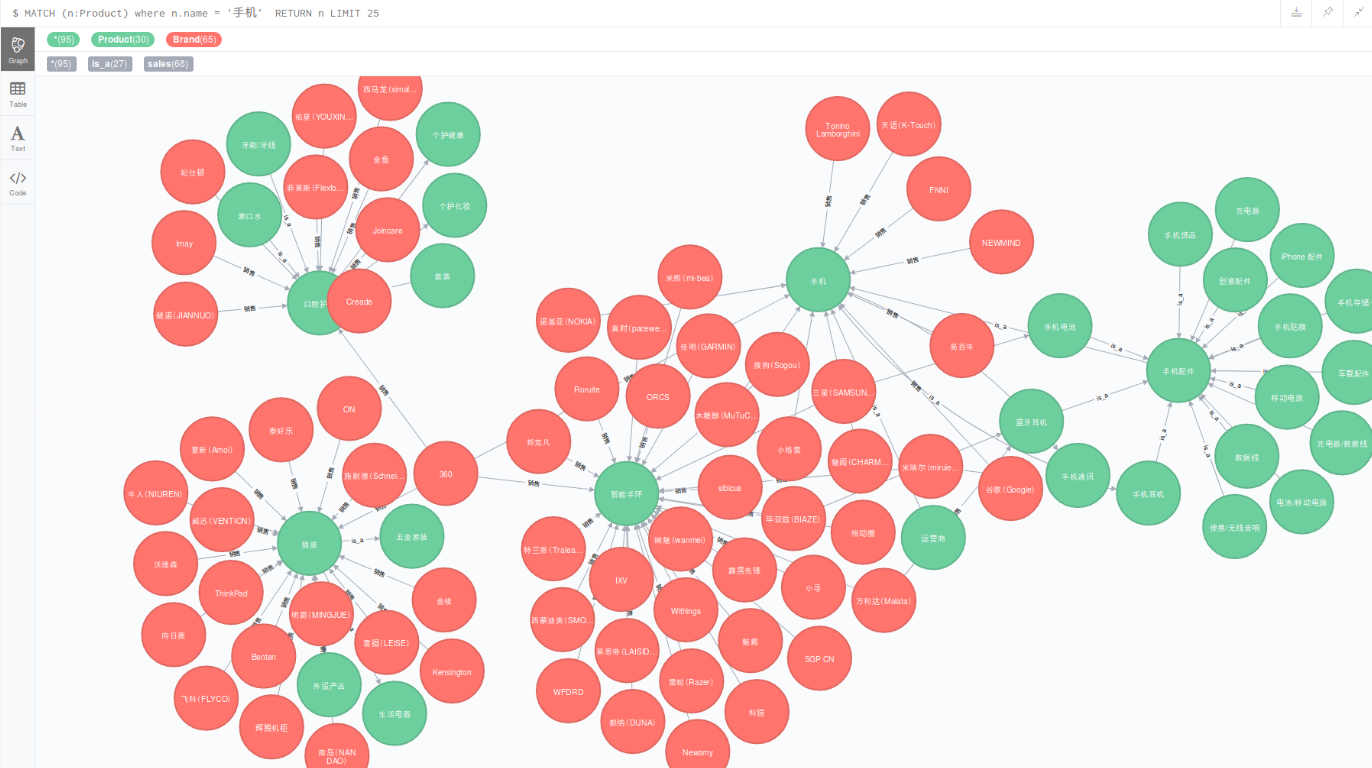
4, 混合关联关系
MATCH (n:Product) where n.name=’手机’ RETURN n LIMIT 25
GitHub源码
https://github.com/chenjj9527/ProductKnowledgeGraph-master
1 #!/usr/bin/env python3 2 # coding: utf-8 3 # File: build_kg.py 4 # Author: cjj 5 # Date: 19-12-23 6 7 import urllib.request 8 from urllib.parse import quote_plus 9 from lxml import etree 10 import gzip 11 import chardet 12 import json 13 import pymongo 14 15 class GoodSchema: 16 def __init__(self): 17 self.conn = pymongo.MongoClient() 18 return 19 20 '''获取搜索页''' 21 def get_html(self, url): 22 headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/600.5.17 (KHTML, like Gecko) Version/8.0.5 Safari/600.5.17"} 23 try: 24 req = urllib.request.Request(url, headers=headers) 25 data = urllib.request.urlopen(req).read() 26 coding = chardet.detect(data) 27 html = data.decode(coding['encoding']) 28 except: 29 req = urllib.request.Request(url, headers=headers) 30 data = urllib.request.urlopen(req).read() 31 html = data.decode('gbk') 32 33 34 return html 35 36 '''获取详情页''' 37 def get_detail_html(self, url): 38 headers = { 39 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", 40 "accept-encoding": "gzip, deflate, br", 41 "accept-language": "en-US,en;q=0.9", 42 "cache-control": "max-age=0", 43 "referer": "https://www.jd.com/allSort.aspx", 44 "upgrade-insecure-requests": 1, 45 "user-agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/66.0.3359.181 Chrome/66.0.3359.181 Safari/537.36" 46 } 47 try: 48 req = urllib.request.Request(url, headers=headers) 49 data = urllib.request.urlopen(req).read() 50 html = gzip.decompress(data) 51 coding = chardet.detect(html) 52 html = html.decode(coding['encoding']) 53 except Exception as e: 54 req = urllib.request.Request(url, headers=headers) 55 data = urllib.request.urlopen(req).read() 56 html = gzip.decompress(data) 57 html = html.decode('gbk') 58 return html 59 60 61 '''根据主页获取数据''' 62 def home_list(self): 63 url = 'https://www.jd.com/allSort.aspx' 64 html = self.get_html(url) 65 selector = etree.HTML(html) 66 divs = selector.xpath('//div[@class= "category-item m"]') 67 for indx, div in enumerate(divs): 68 first_name = div.xpath('./div[@class="mt"]/h2/span/text()')[0] 69 second_classes = div.xpath('./div[@class="mc"]/div[@class="items"]/dl') 70 for dl in second_classes: 71 second_name = dl.xpath('./dt/a/text()')[0] 72 third_classes = ['https:' + i for i in dl.xpath('./dd/a/@href')] 73 third_names = dl.xpath('./dd/a/text()') 74 for third_name, url in zip(third_names, third_classes): 75 try: 76 attr_dict = self.parser_goods(url) 77 attr_brand = self.collect_brands(url) 78 attr_dict.update(attr_brand) 79 data = {} 80 data['fisrt_class'] = first_name 81 data['second_class'] = second_name 82 data['third_class'] = third_name 83 data['attrs'] = attr_dict 84 self.conn['goodskg']['data'].insert(data) 85 print(indx, len(divs), first_name, second_name, third_name) 86 except Exception as e: 87 print(e) 88 return 89 90 '''解析商品数据''' 91 def parser_goods(self, url): 92 html = self.get_detail_html(url) 93 selector = etree.HTML(html) 94 title = selector.xpath('//title/text()') 95 attr_dict = {} 96 other_attrs = ''.join([i for i in html.split(' ') if 'other_exts' in i]) 97 other_attr = other_attrs.split('other_exts =[')[-1].split('];')[0] 98 if other_attr and 'var other_exts ={};' not in other_attr: 99 for attr in other_attr.split('},'): 100 if '}' not in attr: 101 attr = attr + '}' 102 data = json.loads(attr) 103 key = data['name'] 104 value = data['value_name'] 105 attr_dict[key] = value 106 attr_divs = selector.xpath('//div[@class="sl-wrap"]') 107 for div in attr_divs: 108 attr_name = div.xpath('./div[@class="sl-key"]/span/text()')[0].replace(':','') 109 attr_value = ';'.join([i.replace(' ','') for i in div.xpath('./div[@class="sl-value"]/div/ul/li/a/text()')]) 110 attr_dict[attr_name] = attr_value 111 112 return attr_dict 113 114 '''解析品牌数据''' 115 def collect_brands(self, url): 116 attr_dict = {} 117 brand_url = url + '&sort=sort_rank_asc&trans=1&md=1&my=list_brand' 118 html = self.get_html(brand_url) 119 if 'html' in html: 120 return attr_dict 121 data = json.loads(html) 122 brands = [] 123 124 if 'brands' in data and data['brands'] is not None: 125 brands = [i['name'] for i in data['brands']] 126 attr_dict['品牌'] = ';'.join(brands) 127 128 return attr_dict 129 130 131 132 if __name__ == '__main__': 133 handler = GoodSchema() 134 handler.home_list()
1 #!/usr/bin/env python3 2 # coding: utf-8 3 # File: build_kg.py 4 # Author: cjj 5 # Date: 19-12-23 6 7 import json 8 import os 9 from py2neo import Graph, Node, Relationship 10 11 12 class GoodsKg: 13 def __init__(self): 14 cur = '/'.join(os.path.abspath(__file__).split('/')[:-1]) 15 self.data_path = os.path.join(cur, 'data/goods_info.json') 16 self.g = Graph( 17 host="127.0.0.1", # neo4j 搭载服务器的ip地址,ifconfig可获取到 18 http_port=7474, # neo4j 服务器监听的端口号 19 user="neo4j", # 数据库user name,如果没有更改过,应该是neo4j 20 password="111111") 21 return 22 23 '''读取数据''' 24 def read_data(self): 25 rels_goods = [] 26 rels_brand = [] 27 goods_attrdict = {} 28 concept_goods = set() 29 concept_brand = set() 30 count = 0 31 for line in open(self.data_path,encoding='UTF-8'): 32 count += 1 33 print(count) 34 line = line.strip() 35 data = json.loads(line) 36 first_class = data['fisrt_class'].replace("'",'') 37 second_class = data['second_class'].replace("'",'') 38 third_class = data['third_class'].replace("'",'') 39 attr = data['attrs'] 40 concept_goods.add(first_class) 41 concept_goods.add(second_class) 42 concept_goods.add(third_class) 43 rels_goods.append('@'.join([second_class, 'is_a', '属于', first_class])) 44 rels_goods.append('@'.join([third_class, 'is_a', '属于', second_class])) 45 46 if attr and '品牌' in attr: 47 brands = attr['品牌'].split(';') 48 for brand in brands: 49 brand = brand.replace("'",'') 50 concept_brand.add(brand) 51 rels_brand.append('@'.join([brand, 'sales', '销售', third_class])) 52 53 goods_attrdict[third_class] = {name:value for name,value in attr.items() if name != '品牌'} 54 55 return concept_brand, concept_goods, rels_goods, rels_brand 56 57 '''构建图谱''' 58 def create_graph(self): 59 concept_brand, concept_goods, rels_goods, rels_brand = self.read_data() 60 print('creating nodes....') 61 self.create_node('Product', concept_goods) 62 self.create_node('Brand', concept_brand) 63 print('creating edges....') 64 self.create_edges(rels_goods, 'Product', 'Product') 65 self.create_edges(rels_brand, 'Brand', 'Product') 66 return 67 68 '''批量建立节点''' 69 def create_node(self, label, nodes): 70 pairs = [] 71 bulk_size = 1000 72 batch = 0 73 bulk = 0 74 batch_all = len(nodes)//bulk_size 75 print(batch_all) 76 for node_name in nodes: 77 sql = """CREATE(:%s {name:'%s'})""" % (label, node_name) 78 pairs.append(sql) 79 bulk += 1 80 if bulk % bulk_size == 0 or bulk == batch_all+1: 81 sqls = ' '.join(pairs) 82 self.g.run(sqls) 83 batch += 1 84 print(batch*bulk_size,'/', len(nodes), 'finished') 85 pairs = [] 86 return 87 88 89 '''构造图谱关系边''' 90 def create_edges(self, rels, start_type, end_type): 91 batch = 0 92 count = 0 93 for rel in set(rels): 94 count += 1 95 rel = rel.split('@') 96 start_name = rel[0] 97 end_name = rel[3] 98 rel_type = rel[1] 99 rel_name = rel[2] 100 sql = 'match (m:%s), (n:%s) where m.name = "%s" and n.name = "%s" create (m)-[:%s{name:"%s"}]->(n)' %(start_type, end_type, start_name, end_name,rel_type,rel_name) 101 try: 102 self.g.run(sql) 103 except Exception as e: 104 print(e) 105 if count%10 == 0: 106 print(count) 107 108 return 109 110 111 if __name__ =='__main__': 112 handler = GoodsKg() 113 handler.create_graph()