1. 开发调优
- 避免创建重复的RDD
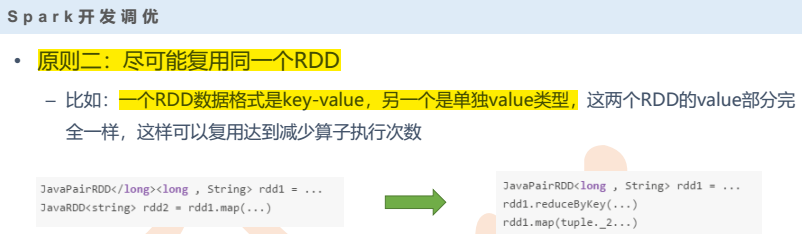
- 尽可能复用同一个RDD
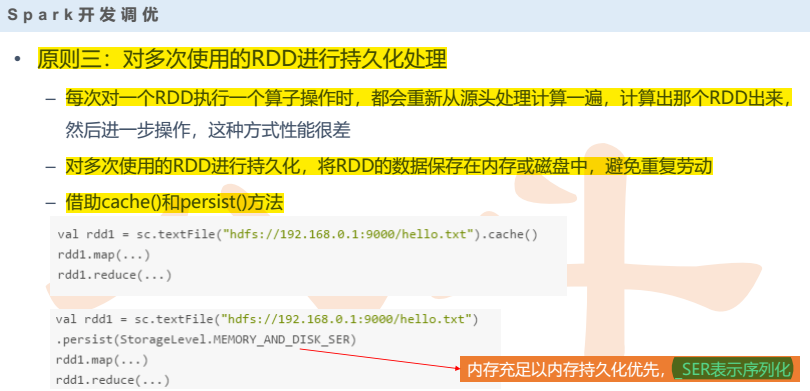
- 对多次使用的RDD进行持久化
- 尽量避免使用shuffle类算子
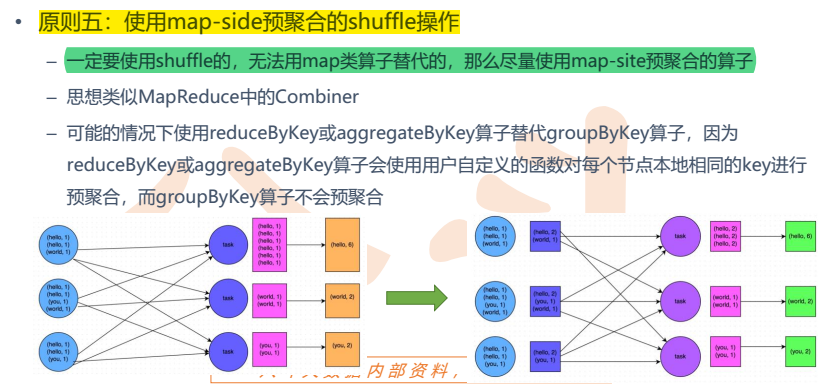
- 使用map-side预聚合的shuffle操作(在每个节点本地对相同的key进行一次聚合操作,map-side预聚合之后,每个节点本地就只会有一条相同的key)
- 使用高性能的算子
- 广播大变量
- 使用Kryo优化序列化性能
- 优化数据结构




2. 资源参数调优
- 运行时架构
- 运行流程
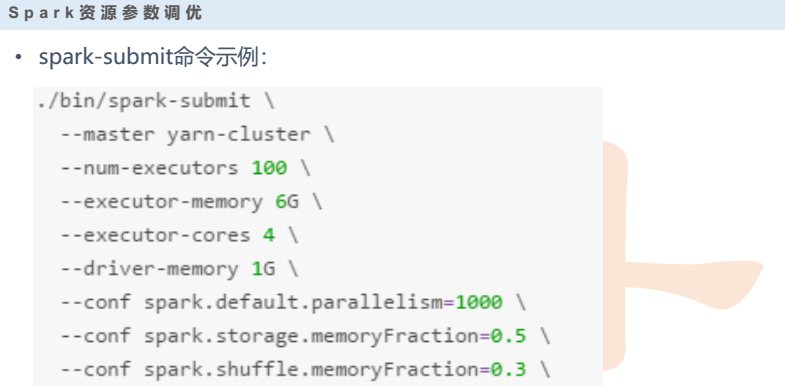
- 调优
- executor配置
- driver配置
- 并行度
- 网络超时
- 数据本地化
- JVM/gc配置



3. 数据倾斜调优
- 使用Hive ETL预处理数据
- 过滤少数导致倾斜的key
- 提高shuffle操作的并行度
- 两阶段聚合
- 将reduce join转为map join
- 使用随机前缀和扩容RDD进行join
4. Shuffle调优
- shuffle原理
- shuffle演进
- 调优
- join类型
5. 其他优化项
- 使用DataFrame/DataSet