0 pandas介绍
Pandas是一款开放源码的BSD许可的Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具。
使用import pandas as pd导入pandas包并且起个响亮的名字pd
1 读取数据的方式
-
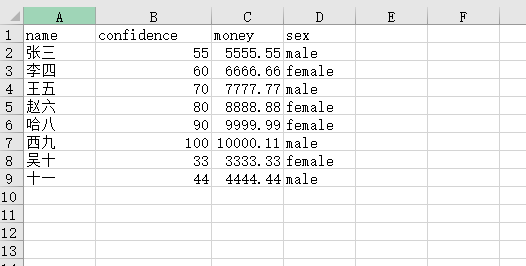
1.1准备数据表csv文件
- it01.csv

-
- it02.csv
-
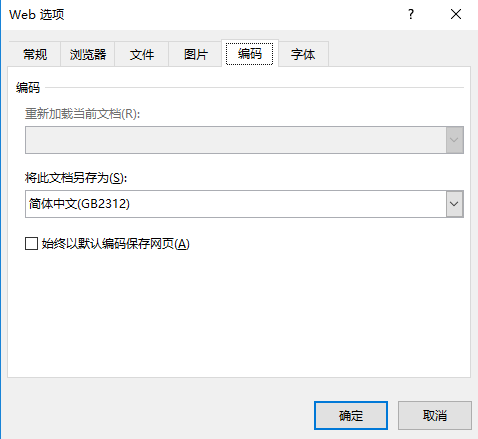
- 创建的时候记得选编码
-
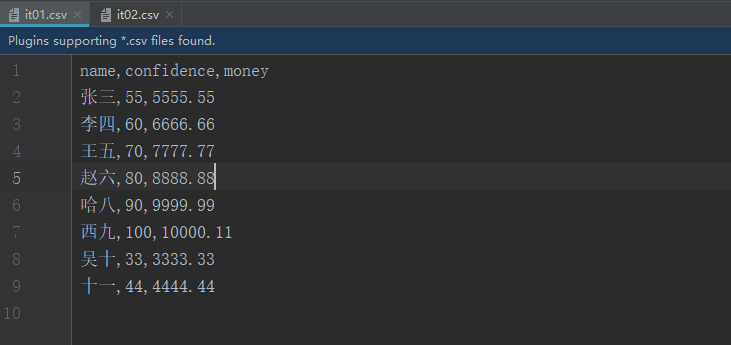
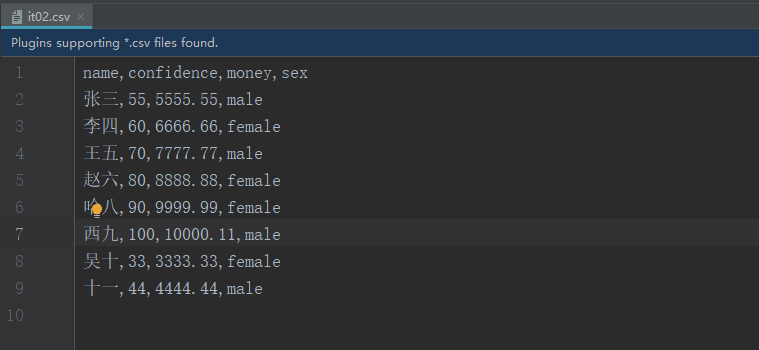
- 在桌面上我们打开的文件是表格形式,但是我们在idea里用txt方式打开就能发现数据是以
,号分隔的。
- 在桌面上我们打开的文件是表格形式,但是我们在idea里用txt方式打开就能发现数据是以
import pandas as pd #编码以gb2312从文件读取csv文件, itInfo = pd.read_csv('it01.csv',encoding='gb2312') print(type(itInfo)) print("---------------------") print(itInfo.dtypes) print("---------------------") print(itInfo)
测试结果: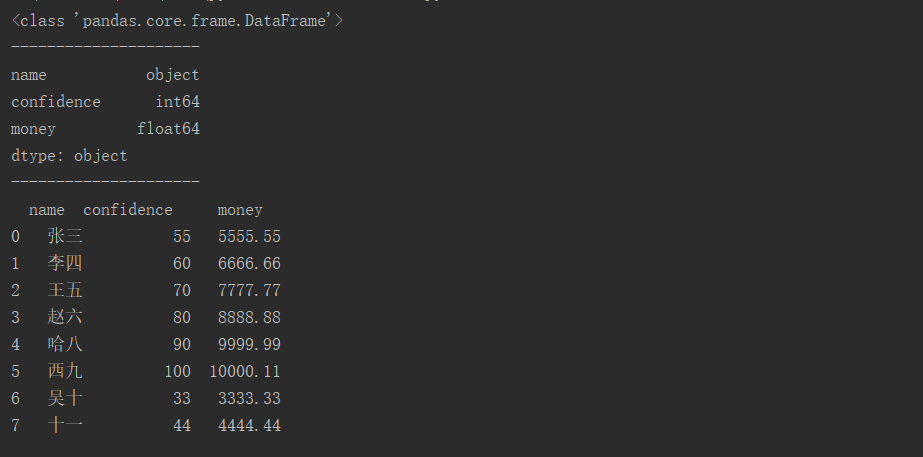
2 展现数据的方式
-
2.1数据列名集合及数据维度
import pandas as pd itInfo = pd.read_csv('it01.csv',encoding='gb2312') #查询几行几列数据 print(itInfo.shape) print("---------------------") #查询列名集合 print(itInfo.columns)
测试结果:
(8, 3)
Index(['name', 'confidence', 'money'], dtype='object')
-
2.2数据查询
import pandas as pd #编码以gb2312从文件读取csv文件, itInfo = pd.read_csv('it01.csv',encoding='gb2312') print("案例1---------------------") #读取前5条数据 print(itInfo.head()) print("案例2---------------------") #读取前2条数据 print(itInfo.head(2)) print("案例3---------------------") #读取后2条数据 print(itInfo.tail(2)) print("案例4---------------------") #读取第几条数据,下标从0开始 print(itInfo.loc[0]) print("案例5---------------------") #读取第4条到第7条数据 print(itInfo.loc[3:6]) print("案例6---------------------") #读取所有name字段的值 print(itInfo['name'])
测试结果:
案例1---------------------
name confidence money
0 张三 55 5555.55
1 李四 60 6666.66
2 王五 70 7777.77
3 赵六 80 8888.88
4 哈八 90 9999.99
案例2---------------------
name confidence money
0 张三 55 5555.55
1 李四 60 6666.66
案例3---------------------
name confidence money
6 吴十 33 3333.33
7 十一 44 4444.44
案例4---------------------
name 张三
confidence 55
money 5555.55
Name: 0, dtype: object
案例5---------------------
name confidence money
3 赵六 80 8888.88
4 哈八 90 9999.99
5 西九 100 10000.11
6 吴十 33 3333.33
案例6---------------------
0 张三
1 李四
2 王五
3 赵六
4 哈八
5 西九
6 吴十
7 十一
Name: name, dtype: object
-
2.3数据处理
import pandas as pd #编码以gb2312从文件读取csv文件, itInfo = pd.read_csv('it01.csv',encoding='gb2312') print("案例1---------------------") #读取全部数据 print(itInfo) print("案例2---------------------") #把信任度进行归一化操作 confidence = itInfo['confidence']/100 print(confidence) print("案例3---------------------") #新增一个数据列 cMoney = itInfo['money'] / itInfo['confidence'] itInfo['cMoney'] = cMoney print(itInfo) print("案例4---------------------") #confidence,最小值,平均值 print(itInfo['confidence'].max()) print(itInfo['confidence'].min()) print(itInfo['confidence'].mean()) print("案例5---------------------") #根据工资排序:inplace是否替换源,ascending倒序设置 itInfo.sort_values('money',inplace=True,ascending=False) print(itInfo)
测试结果:
案例1---------------------
name confidence money
0 张三 55 5555.55
1 李四 60 6666.66
2 王五 70 7777.77
3 赵六 80 8888.88
4 哈八 90 9999.99
5 西九 100 10000.11
6 吴十 33 3333.33
7 十一 44 4444.44
案例2---------------------
0 0.55
1 0.60
2 0.70
3 0.80
4 0.90
5 1.00
6 0.33
7 0.44
Name: confidence, dtype: float64
案例3---------------------
name confidence money cMoney
0 张三 55 5555.55 101.0100
1 李四 60 6666.66 111.1110
2 王五 70 7777.77 111.1110
3 赵六 80 8888.88 111.1110
4 哈八 90 9999.99 111.1110
5 西九 100 10000.11 100.0011
6 吴十 33 3333.33 101.0100
7 十一 44 4444.44 101.0100
案例4---------------------
100
33
66.5
案例5---------------------
name confidence money cMoney
5 西九 100 10000.11 100.0011
4 哈八 90 9999.99 111.1110
3 赵六 80 8888.88 111.1110
2 王五 70 7777.77 111.1110
1 李四 60 6666.66 111.1110
0 张三 55 5555.55 101.0100
7 十一 44 4444.44 101.0100
6 吴十 33 3333.33 101.0100
-
2.4空值判断
- 修改吴十的confidence为NaN(Not a Number-->不是一个数)
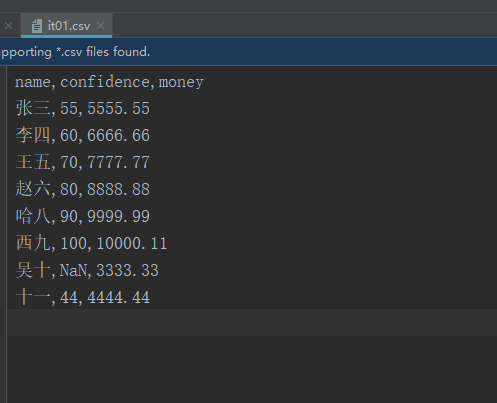
import pandas as pd #编码以gb2312从文件读取csv文件, itInfo = pd.read_csv('it01.csv',encoding='gb2312') print("案例1---------------------") #读取全部数据 print(itInfo) print("案例2---------------------") #判断是否为空 isnull_confidence = pd.isnull(itInfo['confidence']) print(isnull_confidence) print("案例3---------------------") #总和 print(sum(itInfo['confidence'])) print("案例4---------------------") #过滤 not_null_confidence = itInfo['confidence'][isnull_confidence==False] print(not_null_confidence) print("案例5---------------------") #求和 print(sum(not_null_confidence))
测试结果:
案例1---------------------
name confidence money
0 张三 55.0 5555.55
1 李四 60.0 6666.66
2 王五 70.0 7777.77
3 赵六 80.0 8888.88
4 哈八 90.0 9999.99
5 西九 100.0 10000.11
6 吴十 NaN 3333.33
7 十一 44.0 4444.44
案例2---------------------
0 False
1 False
2 False
3 False
4 False
5 False
6 True
7 False
Name: confidence, dtype: bool
案例3---------------------
nan
案例4---------------------
0 55.0
1 60.0
2 70.0
3 80.0
4 90.0
5 100.0
7 44.0
Name: confidence, dtype: float64
案例5---------------------
499.0
-
2.5分组
import pandas as pd import numpy as np #编码以gb2312从文件读取csv文件, itInfo = pd.read_csv('it02.csv',encoding='gb2312') print("案例1---------------------") #读取全部数据 print(itInfo) print("案例2---------------------") #分组:index以什么分组,values求什么结果,aggfunc以什么方法 group = itInfo.pivot_table(index='sex',values='money',aggfunc=np.sum) print(group)
测试结果:
案例1---------------------
name confidence money sex
0 张三 55 5555.55 male
1 李四 60 6666.66 female
2 王五 70 7777.77 male
3 赵六 80 8888.88 female
4 哈八 90 9999.99 female
5 西九 100 10000.11 male
6 吴十 33 3333.33 female
7 十一 44 4444.44 male
案例2---------------------
money
sex
female 28888.86
male 27777.87