1.小例子思路草图
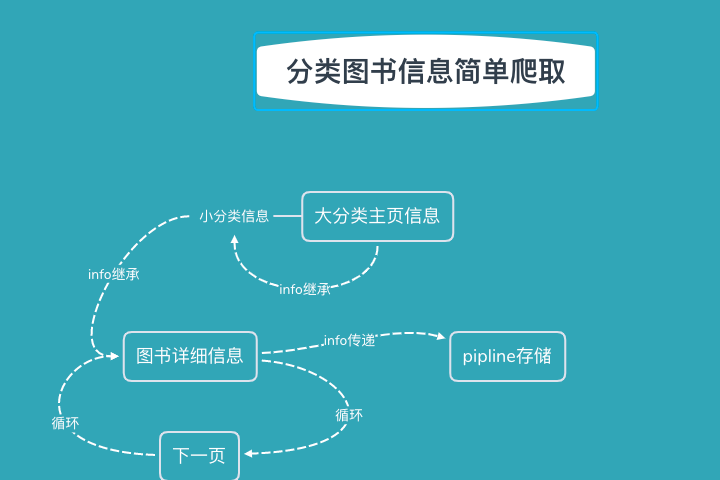
2.遇到的问题
2.1 异端请求(容易忽略)
在跳转详情页时候,请求的域名发生了变化,scrapy会给你过滤掉这个url
2.1.1.解决
更改spider.py
allowed_domains= ['www.xxx.com']
allowed_domains= ['www.xxx.com','www.ccc.com']
使它符合你的请求url
2.1.2.添加参数
yield scrapy.Request(url=url,
callback=self.parse,
dont_filter=True)
#添加dont_filter=True在跳转时
2.1.2爬取信息重复
因为先自定义item来存储字段信息,最后待所有字段保存完毕,再yield给scrapy的items来处理
所以这之间使用meta来传递数据,就是这里出现问题,导致数据重复。
原因:
由于结构限制,所有字段共用一个item,而scrapy是异步请求,上一层分类url不断传递时,下一层具体信息的代码多线程同步执行,
meta传来的item是引用(浅拷贝),所以会重复信息,它不像使用requests模块是单线层,从上到下执行完毕再循环。
解决:
form copy import deepcopy
利用 deepcopy来传递meta信息,每一个线程都会单独为其开辟空间,规避重复问题
2.1.3 页码js生成
在返回的element无下一页信息
解决:
在response.body.decode()中使用正则在js中匹配
通过当前页和总页数的判断大小
设定下一页跳转url