存储和节点的创建
raftexample中的存储其实有两种,一个是通过raft.NewMemoryStorage()进行创建的raft.raftStorage,关联到单个raft节点,另一个是通过newKVStore创建的kv存储,用于服务来自外部的访问。
节点启动时raft.raftStorage的加载
上一篇中主要围绕replayWAL介绍wal的读写,到本文为止可以完整拼接出该函数的处理逻辑。其中snapshot的作用是通过index限定了加载的wal日志的范围。
-
一开始会通过
loadSnapshot函数找出一个有效且最新的snapshot。保证有效的方式是:从raftNode.waldir中读取所有snapshotType类型的数据(snaps),以及最新的stateType类型的数据(state),然后过滤出所有index<=state.Commit的snapshot(state.Commit表示已提交的日志的index,从本地加载的snapshot的index不能超过state.Commit,否则被认为是无效的历史数据);保证最新的方式是:通过对比raftNode.snapdir(注意对比时文件是倒序的)和上一步获取到的snaps(即通过对比Snapshot.Term和Snapshot.Index),找出最新的snapshot。 -
openWAL函数根据第1步中获取到的snapshot的index找出符合条件(即index<=snapshot.index)的wal文件 -
ReadAll()会从上一步的wal文件中读取index大于snapshot.index的entryType类型的表项(wal的start就是snapshot),以及stateType类型的状态信息。case entryType: e := mustUnmarshalEntry(rec.Data) // 0 <= e.Index-w.start.Index - 1 < len(ents) if e.Index > w.start.Index { // prevent "panic: runtime error: slice bounds out of range [:13038096702221461992] with capacity 0" up := e.Index - w.start.Index - 1 if up > uint64(len(ents)) { // return error before append call causes runtime panic return nil, state, nil, ErrSliceOutOfRange } // The line below is potentially overriding some 'uncommitted' entries. ents = append(ents[:up], e) } w.enti = e.Index
总结一下,上面的关系如下,state限定了读取的snapshot的范围(起点),而snapshot限定了读取的ents的范围。

三者的大小关系如下:snapshot.Index<=state.Commit,ents>snapshot.Index。

后续就是将snapshot、state和ents保存到raftStorage中(raftexample的存储实际并不支持持久化,下面以"落库"表示将数据保存到存储中),需要注意的是,落库的内容也受snapshot的限制,即只保存index>snapshot.index的表项(ApplySnapshot函数会使用snapshot的覆盖原有数据,由此可见raftStorage中并没有保存完整的数据)。从上图可以看出所有处理逻辑都以state为起点进行的,state表示raft的处理结果,可以直接落库。当保存snapshot时,需要与存储中的snapshot进行比较,只有当index大于存储中的snapshot的index时才会被保存。在保存ents时,由于ReadAll接口(见上)对读取的ents的范围作了限制,因此只可能出现以下3种情况:1)ents的数据的最大index小于存储中的最小index,这种情况不做任何处理;2)ents的数据的最小index等于存储中的最小index,这种情况直接追加到存储即可;3)ents的数据和存储的数据有交叉,这种情况需要剔除重叠的数据,并追加新的数据。

snapshot中除了保存了索引相关的内容,还保存了与集群状态有关的信息(snapshot.Metadata.ConfState),用于恢复集群状态。
kvStore的存储
节点运行中主要通过raftNode.commitC来通知kvStore。一种是在接收到snapshot时先保存snapshot,然后通过给rc.commitC传递nil来触发kvStore从snap目录中加载snapshot;另一种就是直接通过rc.commitC将接收到的entries保存到kvStore。

raftLog
raft通过raftLog与raftStorage存储进行交互,unstable可以看作是storage的缓存,保存着未进入raftStorage的数据(entires和snapshot)。当需要获取raftLog的首末索引时,会优先从unstable中查找,若找不到,再从raftStorage中查找。
raftNode的创建
下图展示了raft节点的创建过程,从下图可以看到,raft节点启动时主要涉及的是raftLog、ProgressTracker和msgs。上一节已经讲过raftlog,它作为raft的存储,包括unstable和storage。ProgressTracker是raft中用来跟踪集群(config)以及各个节点的状态(prs)。raft集群中的节点分为Voters,Learners和LearnersNext三大类,其中前两个是互斥的,即一个raft节点只能属于其中一类。最后一类存在的原因是为了在voters(outgoing)向learner转换过程中保证一致性(受raft的joint行为限制,raft的状态变更是通过joint方式运作的),是个临时状态。Voters又分为incoming(Voters[0])和outgoing(Voters[1])两种,分别表示新状态和原始状态。当发生状态变更时,会将当前状态拷贝到outgoing中,根据新状态类型(ConfChangeAddNode/ConfChangeAddLearnerNode/ConfChangeRemoveNode/ConfChangeUpdateNode)来执行joint操作,如果raft处于joint状态(outgoing长度大于0),则不能再次执行joint(有可能存在中间状态)。
raftLog中有两个标识:committed和applied,committed标识已经进入storage中的最大日志位置,而applied表示已经处理过的消息(如配置变更等)。其中applied <= committed。
ProgressTracker中保存的节点状态有如下三种:
StateProbe:每个心跳周期只能发送一个复制消息,同时用来探测follower的进度。StateReplicate:为follower可以快速接收赋值日志的理想状态StateSnapshot:在发送赋值消息前需要发送snapshot,来让follower转变为StateReplicate状态

raft的joint操作以及LearnersNext存在的原因见下:
// When we turn a voter into a learner during a joint consensus transition,
// we cannot add the learner directly when entering the joint state. This is
// because this would violate the invariant that the intersection of
// voters and learners is empty. For example, assume a Voter is removed and
// immediately re-added as a learner (or in other words, it is demoted):
//
// Initially, the configuration will be
//
// voters: {1 2 3}
// learners: {}
//
// and we want to demote 3. Entering the joint configuration, we naively get
//
// voters: {1 2} & {1 2 3}
// learners: {3}
//
// but this violates the invariant (3 is both voter and learner). Instead,
// we get
//
// voters: {1 2} & {1 2 3}
// learners: {}
// next_learners: {3}
//
// Where 3 is now still purely a voter, but we are remembering the intention
// to make it a learner upon transitioning into the final configuration:
//
// voters: {1 2}
// learners: {3}
// next_learners: {}
//
// Note that next_learners is not used while adding a learner that is not
// also a voter in the joint config. In this case, the learner is added
// right away when entering the joint configuration, so that it is caught up
// as soon as possible.
上图中的涉及新raft节点的创建,整个过程也比较简单。首先根据replayWAL获取到的snapshot来恢复集群和节点的状态,然后根据本节点是否是leader来执行更新raftLog的提交记录和消息发送。
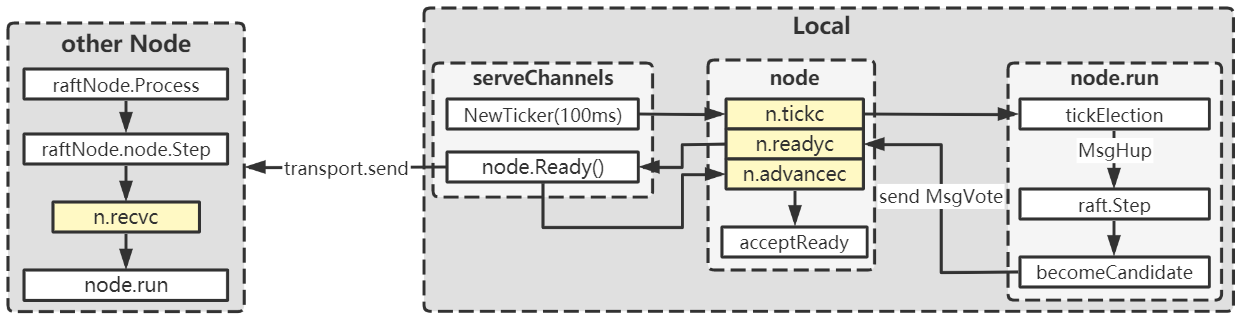
raftNode的运行
下图给出了raftNode的基本运作流程,仅含初始的选举流量,但后续处理方式也大体类似,区别在于传递和处理的消息类型不同。在raftExample的讲解中可以看到启动了一个serveChannels的服务,该服务用于从n.readyc中接收封装好的ready消息,然后进行保存、应用(配置)和发送等操作,最后通过n.advancec通知node节点处理结果,node以此执行acceptReady操作,更新提交记录和应用记录等。
serveChannels中会创建一个100ms的时钟,定时向n.tickc发送触发消息。一开始,所有节点角色都是follower,此时会触发tickElection(follower和candidate为tickElection,leader为tickHeartbeat),尝试将角色转变为candidate。此外ProgressTracker.Votes中保存了支持本节点作为leader的票数,超过一半节点同意时会转变为leader。
n.readyc中传递的ready消息封装了本节点的状态变更以及待发送的信息,n.readyc中的消息进而会传递给serveChannels,后续通过transport.send发送给其他节点,反之亦然。
TIPs
-
etcd的raft角色有三种:leader、follower、learner。在etcd 3.4之前出现可能会出现如下问题:
- 新加入一个节点,leader会将快照同步到该节点,但如果快照数量过大,可能会导致超时,导致节点加入失败
- 新加一个节点时,如果新的节点配置错误(如url错误),可能会导致raft选举失败,集群不可用
为了避免如上问题,加入了一个新的角色learner,它作为一个单独的节点,在日志同步完成之前不参与选举,etcd中需要通过
member promote命令来让learner参与选举。