参考这篇文章:http://blog.csdn.net/dongtingzhizi/article/details/15962797
这篇文章写的真好,把我之前那篇文章的困惑都解释了 http://www.cnblogs.com/charlesblc/p/6208688.html
对《机器学习实战》上面关于梯度上升和下降之间的区别也说清楚了,真好。
已经下载了pdf版,在 /Users/baidu/Documents/Data/Interview/机器学习-数据挖掘/Logistic回归总结.pdf
(1)找一个合适的预测函数(Andrew Ng的公开课中称为hypothesis),一般表示为h函数
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差。将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有的是梯度下降法(Gradient Descent)。
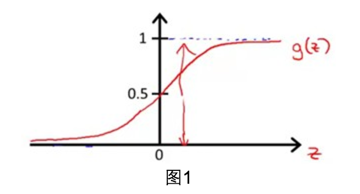
Logistic函数(或称为Sigmoid函数),函数形式为:

构造预测函数为:
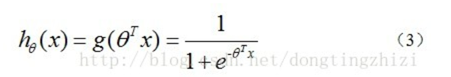
hθ(x)函数的值有特殊的含义,它表示结果取1的概率。(非常适合用来做CTR预估,等等)
3.2 构造Cost函数
Andrew Ng在课程中直接给出了Cost函数及J(θ)函数如式(5)和(6),但是并没有给出具体的解释,只是说明了这个函数来衡量h函数预测的好坏是合理的。
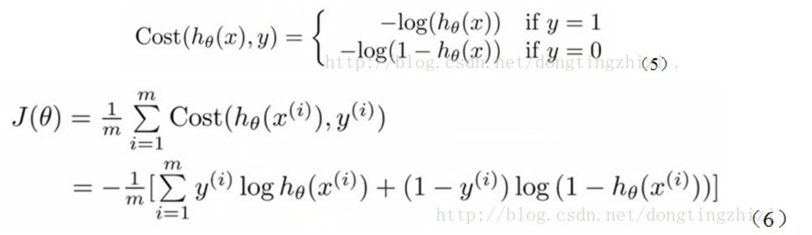
实际上这里的Cost函数和J(θ)函数是基于最大似然估计推导得到的。最大似然的介绍可以见:
http://www.cnblogs.com/charlesblc/p/6257848.html
在Andrew Ng的课程中将J(θ)取为(6)式,
因为乘了一个负的系数-1/m,所以J(θ)取最小值时的θ为要求的最佳参数。(本来极大似然是要求最大值的)
3.3 梯度下降法求J(θ)的最小值
求J(θ)的最小值可以使用梯度下降法,根据梯度下降法可得θ的更新过程:
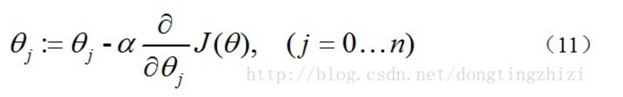
式中为α学习步长,下面来求偏导:
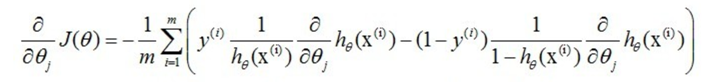
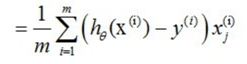
因此,(11)式的更新过程可以写成:
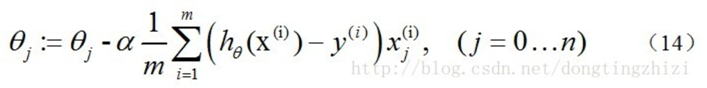
因为式中α本来为一常量,所以1/m一般将省略,所以最终的θ更新过程为
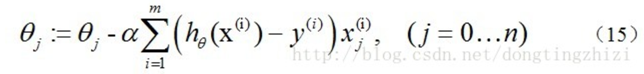
3.4 梯度下降过程向量化
关于θ更新过程的vectorization,Andrew Ng的课程中只是一带而过,没有具体的讲解。
下面说明一下我理解《机器学习实战》中代码实现的vectorization过程。
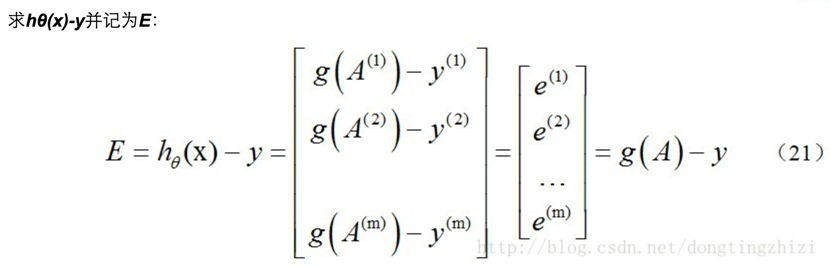
g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知hθ(x)-y可以由g(A)-y一次计算求得。

综上所述,vectorization后θ更新的步骤如下:
(1)求A=x.θ;
(2)求E=g(A)-y;
(3)求θ:=θ-α.x'.E, x'表示矩阵x的转置。
也可以综合起来写成:
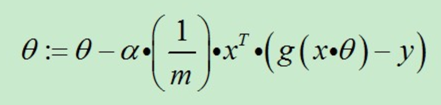
前面已经提到过:1/m是可以省略的。
4. 代码分析
图4中是《机器学习实战》中给出的部分实现代码。
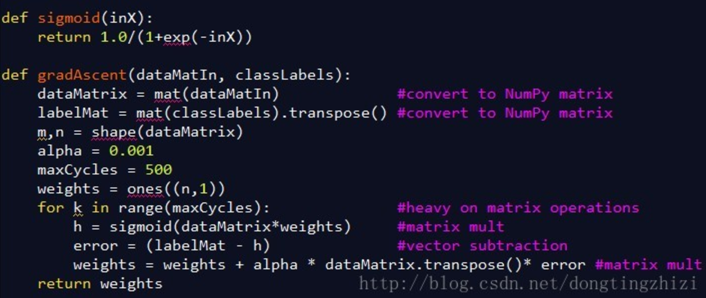
一句话,牛逼!